Original Link: https://www.anandtech.com/show/16805/amd-threadripper-pro-review-an-upgrade-over-regular-threadripper
AMD Threadripper Pro Review: An Upgrade Over Regular Threadripper?
by Dr. Ian Cutress on July 14, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- ThreadRipper
- Threadripper Pro
- 3995WX

Since the launch of AMD’s Threadripper Pro platform, the desire to see what eight channels of memory brings to compute over the regular quad-channel Threadripper has been an intriguing prospect. Threadripper Pro is effectively a faster version of AMD’s EPYC, limited for single CPU workstation use, but also heralds a full 280 W TDP to match the frequencies of the standard Threadripper line. There is a 37% price premium from Threadripper to Threadripper Pro, which allows for ECC memory support, double the PCIe lanes, and double the memory bandwidth. In this review, we’re comparing every member of both platforms that is commercially available.
Threadripper Pro: Born of Need
When AMD embarked upon its journey with the new Ryzen portfolio, the delineation of where each product sat in the traditional market has not always been entirely clear. The first generation Ryzen was earmarked for standard consumers, however the top of the line Ryzen 7 1800X, with eight cores, competed against Intel’s high-end desktop market. The Zen 2-based portfolio saw the mainstream Ryzen go to 16 cores, pushing past Intel’s best 18-core HEDT processor at the time in most tests. That Zen 2-based Ryzen 9 3950X was still classified as a ‘mainstream platform’ processor, as it only had 24 PCIe lanes and dual-channel memory, sufficient for mainstream users but not enough for workstation markets. These mainstream processors were also limited to 105W TDP.
At the other end of the scale was AMD EPYC, with the first generation EPYC 7601 having 32 cores, and the second generation EPYC 7742 having 64 cores, up to 225W TDP. These share the same LGA4094 socket, have eight channels of memory, full ECC support, and 128 PCIe lanes (first PCIe 3.0, then PCIe 4.0), with dual-socket support. For workstation users interested in EPYC, AMD launched single socket ‘P’ versions. These offered the same features, at around 200 TDP, losing some performance to the regular non-P versions.
AMD then launched Threadripper, a high-end desktop version of EPYC that went all the way up to 280 W for peak frequency and performance. Threadripper sat above Ryzen with 64 PCIe lanes and quad channel memory, enabling mainstream users that wanted a bit more to get a bit more. However workstation users noted that while 280 W was great, it lacked official ECC memory support, and compared to EPYC, sometimes the reduced memory channel support and reduced PCIe compared to EPYC stopped Threadripper being adopted.

So enter Threadripper Pro, which sits between Threadripper and EPYC, and in this instance, very much more on the EPYC side. Threadripper Pro has almost all the features of AMD’s EPYC platform, but in a 280W thermal envelope. It has eight channels of memory support, all 128 PCIe 4.0 lanes, and can support ECC. The only downside to EPYC is that it can only be used in single socket systems, and the peak memory support is halved (from 4 TB to 2 TB). Threadripper Pro also comes at a small price premium as well.
| AMD Comparison | ||||
| AnandTech | Ryzen | Threadripper | Threadripper Pro |
Enterprise EPYC |
| Cores | 6-16 | 32-64 | 12-64 | 16-64 |
| Architecture | Zen 3 | Zen 2 | Zen 2 | Zen 3 |
| 1P Flagship | R9 5950X |
TR 3990X |
TR Pro 3995WX | EPYC 7713P |
| MSRP | $799 | $3990 | $5490 | $5010 |
| TDP | 105 W | 280 W | 280 W | 225 W |
| Base Freq | 3400 MHz | 2900 MHz | 2700 MHz | 2000 MHz |
| Turbo Freq | 4900 MHz | 4300 MHz | 4200 MHz | 3675 MHz |
| Socket | AM4 | sTRX40 | sTRX4: WRX80 | SP3 |
| L3 Cache | 64 MB | 256 MB | 256 MB | 256 MB |
| DRAM | 2 x DDR4-3200 | 4 x DDR4-3200 | 8 x DDR4-3200 | 8 x DDR4-3200 |
| DRAM Capacity | 128 GB | 256 GB | 2 TB, ECC | 4 TB, ECC |
| PCIe | 4.0 x20 + chipset |
4.0 x56 + chipset | 4.0 x120 + chipset | 4.0 x128 |
| Pro Features | No | No | Yes | Yes |
One of the biggest pulls for Threadripper and Threadripper Pro has been any market that typically uses high-speed workstations and can scale their workloads. Speaking to a local OEM, the demand for Threadripper and Threadripper Pro from the visual effects industry has been off the charts, where these companies are ripping out their old infrastructure and replacing anew with AMD. This has also been spurned by the recent pandemic, where these studios want to keep the expensive hardware onsite and allow their artists to work from home via remote access.
Threadripper Pro CPUs: Four Models, Three at Retail
When TR Pro launched in 2020, the processors were a Lenovo exclusive for the P620 workstation. The deal between Lenovo and AMD was not disclosed, however it would appear that the exclusivity deal ran for six months, from September to February, with the processors being made retail available on March 2nd.

During that time, we were sampled one of these workstations for review, and it still remains one of the best modular systems I’ve ever tested:
Lenovo ThinkStation P620 Review: A Vehicle for Threadripper Pro
AMD’s first Threadripper Pro platform has four processors in it, ranging from 12 cores to 64 cores, mimicking their equivalents in Threadripper 3000 and EPYC 77x2 but at 280W.
| AMD Ryzen Threadripper Pro | |||||||
| AnandTech | Cores | Base Freq |
Turbo Freq |
Chiplets | L3 Cache |
TDP | Price SEP |
| 3995WX | 64 / 128 | 2700 | 4200 | 8 + 1 | 256 MB | 280 W | $5490 |
| 3975WX | 32 / 64 | 3500 | 4200 | 4 + 1 | 128 MB | 280 W | $2750 |
| 3955WX | 16 / 32 | 3900 | 4300 | 2 + 1 | 64 MB | 280 W | $1150 |
| 3945WX | 12 / 24 | 4000 | 4300 | 2 + 1 | 64 MB | 280 W | OEM |
Sitting at the top is the 64-core Threadripper Pro 3995WX, with a 2.7 GHz base frequency and a 4.2 GHz turbo frequency. This processor is the only one in the family to have all 256 MB of L3 cache, as it has all eight chiplets fully active. The $5490 price is a full 37.5% increase over the Threadripper 3990X at $3990.
| AMD 64-Core Zen 2 Comparison | |||
| AnandTech | Threadripper 3990X |
Threadripper Pro 3995WX |
EPYC 7702P |
| MSRP | $3990 | $5490 | $4425 |
| TDP | 280 W | 280 W | 200 W |
| Base Freq | 2900 MHz | 2700 MHz | 2000 MHz |
| Turbo Freq | 4300 MHz | 4200 MHz | 3350 MHz |
| L3 Cache | 256 MB | 256 MB | 256 MB |
| DRAM | 4 x DDR4-3200 | 8 x DDR4-3200 | 8 x DDR4-3200 |
| DRAM Capacity | 256 GB | 2 TB, ECC | 4 TB, ECC |
| PCIe | 4.0 x56 + chipset | 4.0 x120 + chipset | 4.0 x128 |
| Pro Features | No | Yes | Yes |
Middle of the line is the 32-core Threadripper Pro 3975WX, with a 3.5 GHz base frequency and a 4.2 GHz turbo frequency. AMD decided to make this processor use four chiplets with all eight cores on each chiplet, leading to 128 MB of L3 cache total. At $2750, it is also 37.5% more expensive than the equivalent 32-core Threadripper 3970X.
| AMD 32-Core Zen 2 Comparison | |||
| AnandTech | Threadripper 3970X |
Threadripper Pro 3975WX |
EPYC 7501P |
| MSRP | $3990 | $2750 | $2300 |
| TDP | 280 W | 280 W | 180 W |
| Base Freq | 3700 MHz | 3500 MHz | 2500 MHz |
| Turbo Freq | 4500 MHz | 4200 MHz | 3350 MHz |
| L3 Cache | 128 MB | 128 MB | 128 MB |
| DRAM | 4 x DDR4-3200 | 8 x DDR4-3200 | 8 x DDR4-3200 |
| DRAM Capacity | 256 GB | 2 TB, ECC | 4 TB, ECC |
| PCIe | 4.0 x56 + chipset | 4.0 x120 + chipset | 4.0 x128 |
| Pro Features | No | Yes | Yes |
The following two processors have no Threadripper equivalents, but also represent a slightly different scenario that we’ll explore in this review. Both the 3955WX and 3945WX, despite being part of the big Threadripper Pro family, only use two chiplets in their design: 8 core per chipet for the 3955 WX and 6 core per chiplet for the 3945WX. This means these processors only have 64 MB of L3 cache, making them somewhat identical to the Ryzen 9 3950X and Ryzen 9 3900X, except the IO die means there is eight channels of memory and 128 PCIe lanes here.
| AMD 16-Core Zen 2/3 Comparison | |||
| AnandTech | Ryzen 9 3950X |
Threadripper Pro 3955WX |
Ryzen 9 5950X |
| MSRP | $749 | $1150 | $799 |
| TDP | 105 W | 280 W | 105 W |
| Base Freq | 3500 MHz | 3900 MHz | 3400 MHz |
| Turbo Freq | 4700 MHz | 4300 MHz | 4900 MHz |
| L3 Cache | 64 MB | 64 MB | 64 MB |
| DRAM | 2 x DDR4-3200 | 8 x DDR4-3200 | 2 x DDR4-3200 |
| DRAM Capacity | 128 GB | 2 TB, ECC | 128 GB |
| PCIe | 4.0 x20 + chipset |
4.0 x120 + chipset |
4.0 x20 + chipset |
| Pro Features | No | Yes | No |
| Motherboard Cost | -- | +++ | -- |
The 3955WX has a higher base frequency, but the 3950X has the higher turbo frequency. The 3950X is also cheaper, and motherboards are cheaper! It might be worth partitioning these out into a separate comparison review.
The final Threadripper Pro processor, the 3945WX, does not have a price, because AMD is not making it available at retail. This part is for selected OEM customers only it seems; perhaps the limited substrate resources in the market right now makes it unappealing to make too many of these? Hard to say.
Motherboards: Beware!
Despite being based on the same LGA4094 socket as both Threadripper and EPYC, Threadripper Pro has its own unique WRX80 platform that has to be used instead. Only select vendors seem to have access/licenses to make WRX80 motherboards, and your main options are:
- ASUS Pro WS WRX80E-SAGE SE WiFi ($1000)
- Supermicro M12SWA-TF (~$750)
- GIGABYTE WRX80 SU8-IPMI ($790)
All three boards use a transposed LGA4094 socket, eight DDR4 memory slots, and 6-7 PCIe 4.0 slots.

Though beware! There is an option of finding an old/refurbished Lenovo P620 motherboard. It is worth noting that Lenovo is exercising an AMD feature for OEMs: processors used in that Lenovo motherboard will be locked to Lenovo forever. This is part of AMD’s guaranteed supply chain process, allowing OEMs to hard lock processors into certain vendors for supply chain end-to-end security that is requested by specific customers. In that instance, if you might ever want to break down your system to upgrade and sell off parts, it is not recommended you find a Lenovo TR Pro system unless you buy/sell it as a whole.
This Review
The main goal of this review is to test all of the Threadripper Pro 3000 hardware and compare against the equivalent Threadripper 3000 to get a sense of how much performance is gained by the increased memory bandwidth, or lost due to the slight core frequency differences. We are also including Intel’s best HEDT/workstation processor for comparison, the W-3175X, as well as the top consumer-grade processors on the market. All systems are tested at JEDEC specifications.
| Test Setup | |||||
| AMD TR Pro |
3995WX 3975WX 3955WX |
ASUS Pro WS WRX80E-SAGE SE WiFi |
BIOS 0405 |
IceGiant Thermosiphon |
Kingston 8x16 GB DDR4-3200 ECC |
| AMD TR |
TR 3990X TR 3970X TR 3960X |
ASRock TRX40 Taichi |
BIOS P1.70 |
IceGiant Thermosiphon |
ADATA 4x32 GB DDR4-3200 |
| AMD Ryzen |
R9 5950X | GIGABYTE X570 I Aorus Pro |
BIOS F31L |
Noctua NH-U12S |
ADATA 4x32 GB DDR4-3200 |
| Intel Core |
i9-11900K | ASUS Maximus XIII Hero |
BIOS 0703 |
Thermalright TRUE Copper* |
ADATA 4x32 GB DDR4-3200 |
| Intel Xeon |
Xeon W-3175X | ASUS ROG Dominus Extreme |
BIOS 0601 | Asetek 690LX-PN |
DDR4-2666 ECC |
| GPU | Sapphire RX 460 2GB (CPU Tests) | ||||
| PSU | Various (inc. Corsair AX860i) | ||||
| SSD | Crucial MX500 2TB | ||||
| *Silverstone SST-FHP141-VF 173 CFM fans also used. Nice and loud. | |||||
Many thanks to Kingston for supplying a full set of KSM32RD8/16MEI - 16x16 GB of DDR4-3200 ECC RDIMMs for enterprise testing in systems like Threadripper Pro.

As part of this review, we are also showcasing the 64 core processors in 128T mode as well as 64T mode. This is being done to showcase how some processors can get better performance by having better memory bandwidth per thread - one of the issues with these high core count processors is the limited amount of memory bandwidth each thread can access. Also, some operating systems (such as Windows) struggle above 64 threads due to the use of thread groups.
Power Consumption
The nature of reporting processor power consumption has become, in part, a dystopian nightmare. Historically the peak power consumption of a processor, as purchased, is given by its Thermal Design Power (TDP, or PL1). For many markets, such as embedded processors, that value of TDP still signifies the peak power consumption. For the processors we test at AnandTech, either desktop, notebook, or enterprise, this is not always the case.
Modern high performance processors implement a feature called Turbo. This allows, usually for a limited time, a processor to go beyond its rated frequency. Exactly how far the processor goes depends on a few factors, such as the Turbo Power Limit (PL2), whether the peak frequency is hard coded, the thermals, and the power delivery. Turbo can sometimes be very aggressive, allowing power values 2.5x above the rated TDP.
AMD and Intel have different definitions for TDP, but are broadly speaking applied the same. The difference comes to turbo modes, turbo limits, turbo budgets, and how the processors manage that power balance. These topics are 10000-12000 word articles in their own right, and we’ve got a few articles worth reading on the topic.
- Why Intel Processors Draw More Power Than Expected: TDP and Turbo Explained
- Talking TDP, Turbo and Overclocking: An Interview with Intel Fellow Guy Therien
- Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics
- Intel’s TDP Shenanigans Hurts Everyone
In simple terms, processor manufacturers only ever guarantee two values which are tied together - when all cores are running at base frequency, the processor should be running at or below the TDP rating. All turbo modes and power modes above that are not covered by warranty. Intel kind of screwed this up with the Tiger Lake launch in September 2020, by refusing to define a TDP rating for its new processors, instead going for a range. Obfuscation like this is a frustrating endeavor for press and end-users alike.
However, for our tests in this review, we measure the power consumption of the processor in a variety of different scenarios. These include full peak AVX workflows, a loaded rendered test, and others as appropriate. These tests are done as comparative models. We also note the peak power recorded in any of our tests.
First up is our loaded rendered test, designed to peak out at max power.
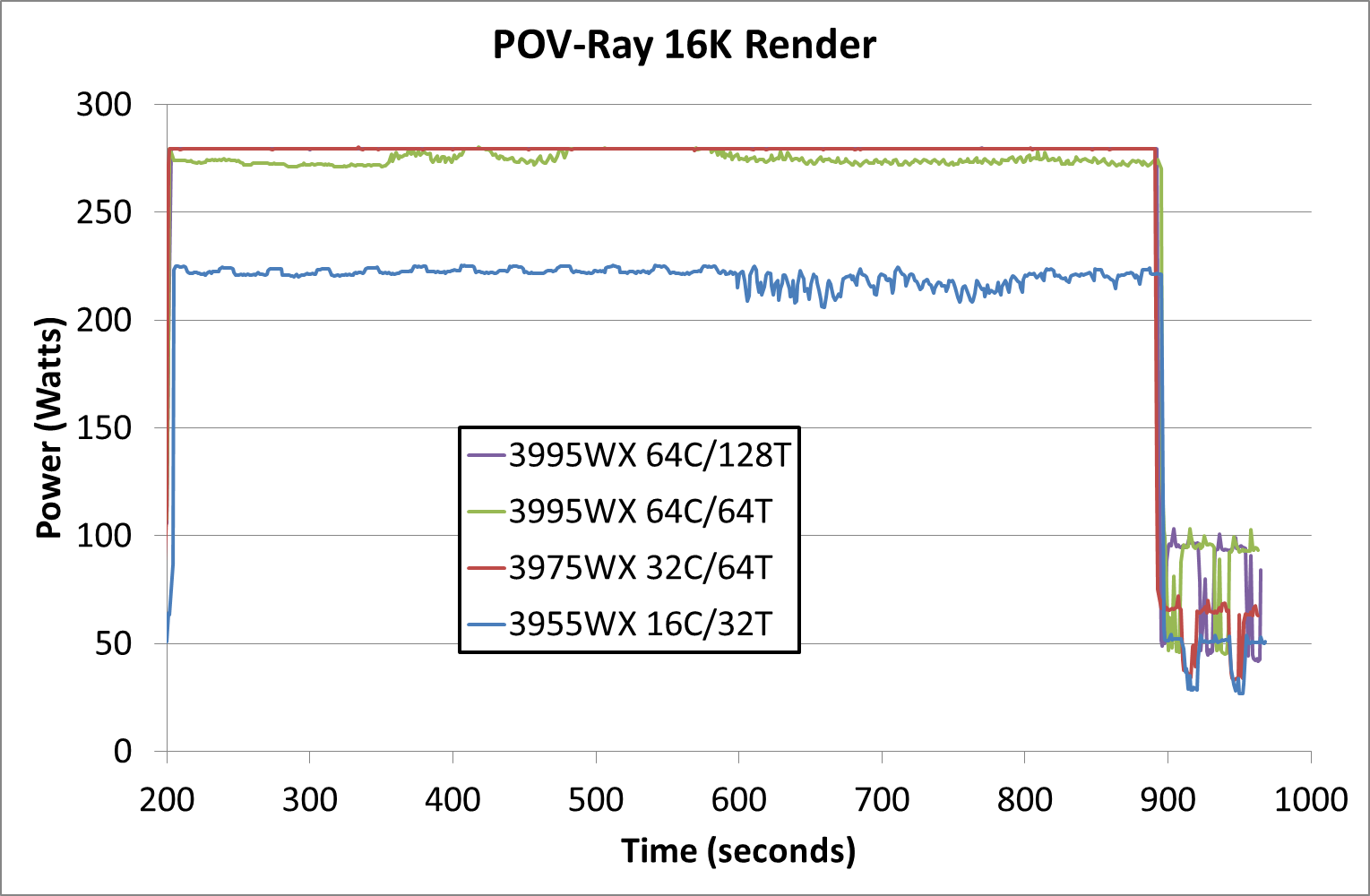
In this test the 3995WX with only 64 threads actually uses slightly less power, given that one thread per core doesn’t keep everything active. Despite this, the 64C/64T benchmark result is ~16000 points, compared to ~12600 points when all 128 threads are enabled. Also in this chart we see that the 3955WX with only sixteen cores hovers around the 212W mark.
The second test is from y-Cruncher, which is our AVX2/AVX512 workload. This also has some memory requirements, which can lead to periodic cycling with systems that have lower memory bandwidth per core options.
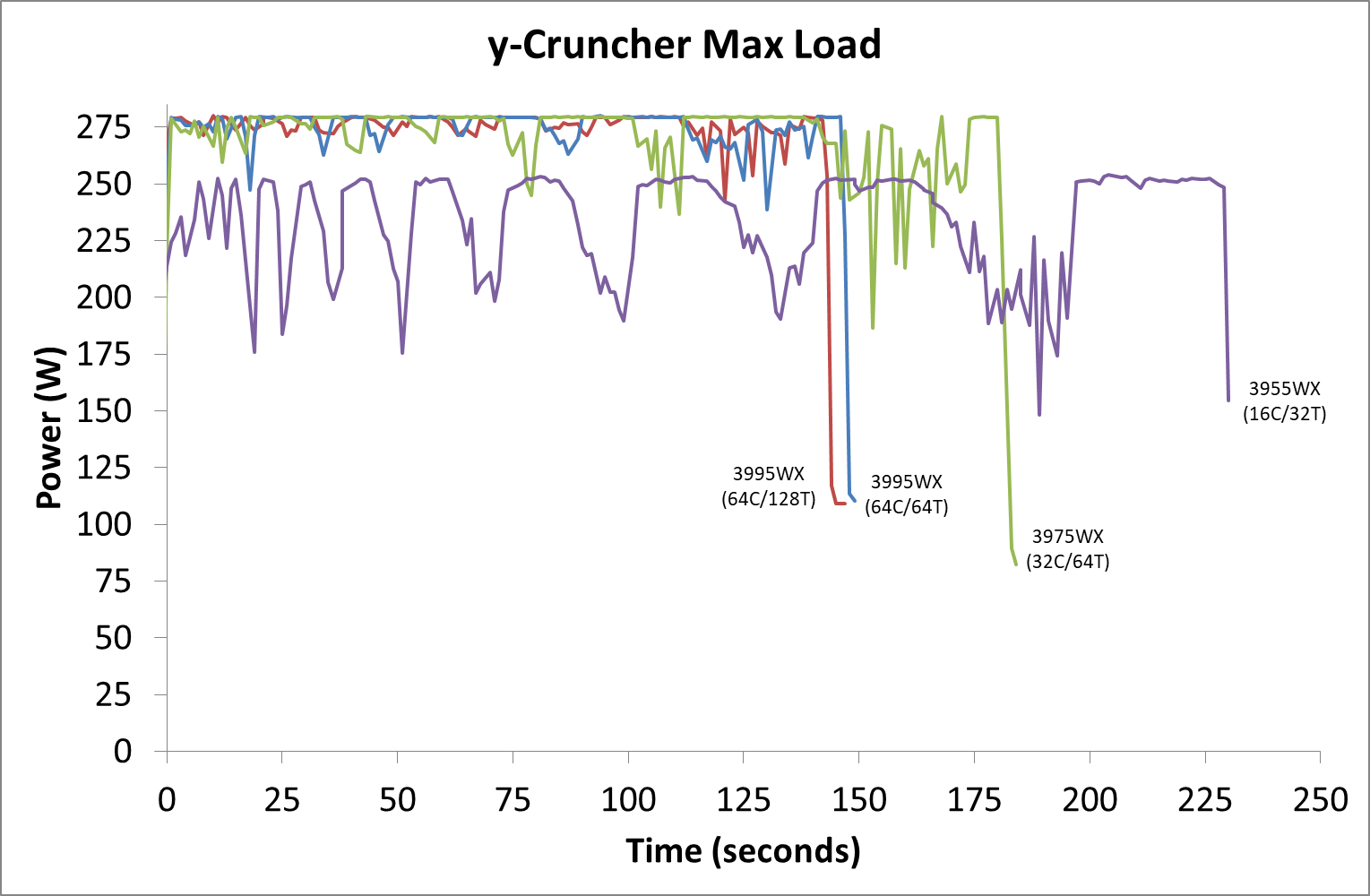
Both of the 3995WX configurations perform similarly, while the 3975WX has more variability as it requests data from memory causing the cores to idle slightly. The 3955WX peaks around 250W this time.
For peak power, we report the highest value observed from any of our benchmark tests.
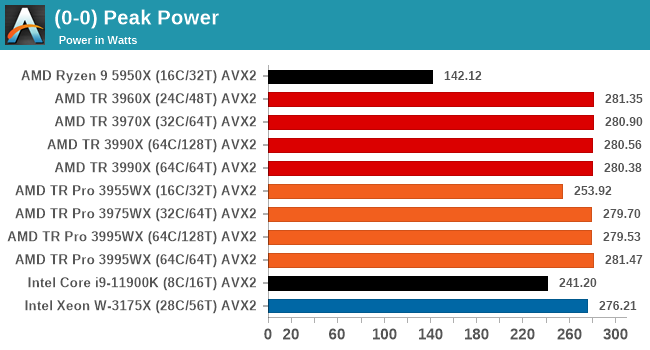
As with most AMD processors, there is a total package power tracking value, and for Threadripper Pro that is the same as the TDP at 280 W. I have included the AVX2 values here for the Intel processors, however at AVX512 these will turbo to 296 W (i9-11900K) and 291 W (W-3175X).
CPU Tests: Rendering
Rendering tests, compared to others, are often a little more simple to digest and automate. All the tests put out some sort of score or time, usually in an obtainable way that makes it fairly easy to extract. These tests are some of the most strenuous in our list, due to the highly threaded nature of rendering and ray-tracing, and can draw a lot of power. If a system is not properly configured to deal with the thermal requirements of the processor, the rendering benchmarks is where it would show most easily as the frequency drops over a sustained period of time. Most benchmarks in this case are re-run several times, and the key to this is having an appropriate idle/wait time between benchmarks to allow for temperatures to normalize from the last test.
Blender 2.83 LTS: Link
One of the popular tools for rendering is Blender, with it being a public open source project that anyone in the animation industry can get involved in. This extends to conferences, use in films and VR, with a dedicated Blender Institute, and everything you might expect from a professional software package (except perhaps a professional grade support package). With it being open-source, studios can customize it in as many ways as they need to get the results they require. It ends up being a big optimization target for both Intel and AMD in this regard.
For benchmarking purposes, we fell back to one rendering a frame from a detailed project. Most reviews, as we have done in the past, focus on one of the classic Blender renders, known as BMW_27. It can take anywhere from a few minutes to almost an hour on a regular system. However now that Blender has moved onto a Long Term Support model (LTS) with the 2.83 release, we decided to go for something different.

We use this scene, called PartyTug at 6AM by Ian Hubert, which is the official image of Blender 2.83. It is 44.3 MB in size, and uses some of the more modern compute properties of Blender. As it is more complex than the BMW scene, but uses different aspects of the compute model, time to process is roughly similar to before. We loop the scene for at least 10 minutes, taking the average time of the completions taken. Blender offers a command-line tool for batch commands, and we redirect the output into a text file.
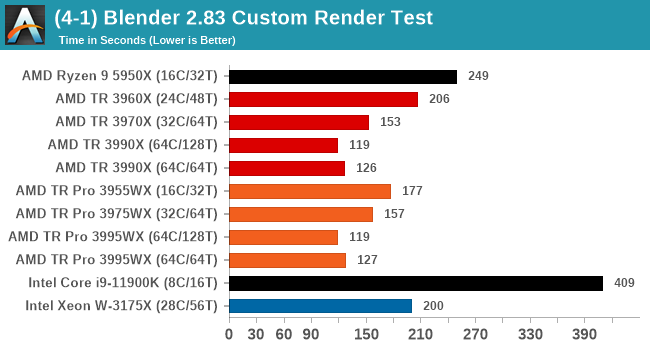
For Blender, we're seeing that SMT gives some extra performance in 64C mode, and comparing TR to TR Pro shows a big jump for the 3955WX over the 3960X despite having fewer cores, whereas the 32c TR is slightly faster than the 32c TR Pro. At 64c, there's little difference.
Corona 1.3: Link
Corona is billed as a popular high-performance photorealistic rendering engine for 3ds Max, with development for Cinema 4D support as well. In order to promote the software, the developers produced a downloadable benchmark on the 1.3 version of the software, with a ray-traced scene involving a military vehicle and a lot of foliage. The software does multiple passes, calculating the scene, geometry, preconditioning and rendering, with performance measured in the time to finish the benchmark (the official metric used on their website) or in rays per second (the metric we use to offer a more linear scale).
The standard benchmark provided by Corona is interface driven: the scene is calculated and displayed in front of the user, with the ability to upload the result to their online database. We got in contact with the developers, who provided us with a non-interface version that allowed for command-line entry and retrieval of the results very easily. We loop around the benchmark five times, waiting 60 seconds between each, and taking an overall average. The time to run this benchmark can be around 10 minutes on a Core i9, up to over an hour on a quad-core 2014 AMD processor or dual-core Pentium.
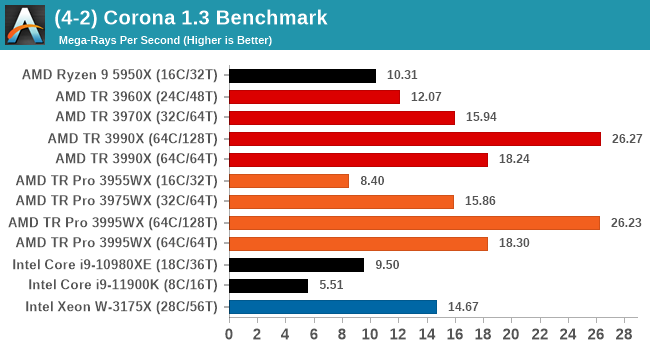
Corona is another bencmark where having SMT enabled does push the results higher, and there's no real difference between TR and TR Pro here.
Crysis CPU-Only Gameplay
One of the most oft used memes in computer gaming is ‘Can It Run Crysis?’. The original 2007 game, built in the Crytek engine by Crytek, was heralded as a computationally complex title for the hardware at the time and several years after, suggesting that a user needed graphics hardware from the future in order to run it. Fast forward over a decade, and the game runs fairly easily on modern GPUs.
But can we also apply the same concept to pure CPU rendering? Can a CPU, on its own, render Crysis? Since 64 core processors entered the market, one can dream. So we built a benchmark to see whether the hardware can.
For this test, we’re running Crysis’ own GPU benchmark, but in CPU render mode. This is a 2000 frame test, with medium and low settings.
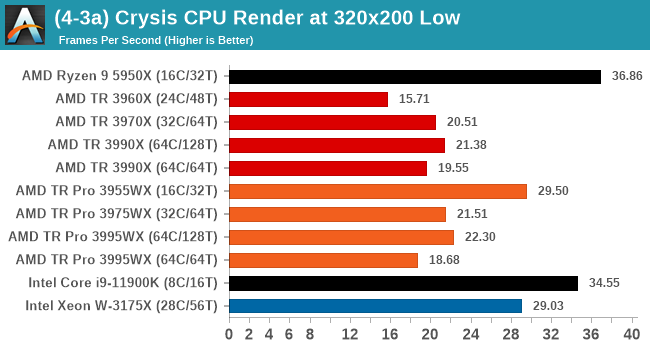
Crysis CPU only has two main limitations: either 32 threads, or 23 cores. We typically run across 16 cores with all threads, and this benchmark tends to prefer cores with high IPC. The 3955WX seems to perform best here, although the Intel options come out ahead.
POV-Ray 3.7.1: Link
A long time benchmark staple, POV-Ray is another rendering program that is well known to load up every single thread in a system, regardless of cache and memory levels. After a long period of POV-Ray 3.7 being the latest official release, when AMD launched Ryzen the POV-Ray codebase suddenly saw a range of activity from both AMD and Intel, knowing that the software (with the built-in benchmark) would be an optimization tool for the hardware.
We had to stick a flag in the sand when it came to selecting the version that was fair to both AMD and Intel, and still relevant to end-users. Version 3.7.1 fixes a significant bug in the early 2017 code that was advised against in both Intel and AMD manuals regarding to write-after-read, leading to a nice performance boost.
The benchmark can take over 20 minutes on a slow system with few cores, or around a minute or two on a fast system, or seconds with a dual high-core count EPYC. Because POV-Ray draws a large amount of power and current, it is important to make sure the cooling is sufficient here and the system stays in its high-power state. Using a motherboard with a poor power-delivery and low airflow could create an issue that won’t be obvious in some CPU positioning if the power limit only causes a 100 MHz drop as it changes P-states.
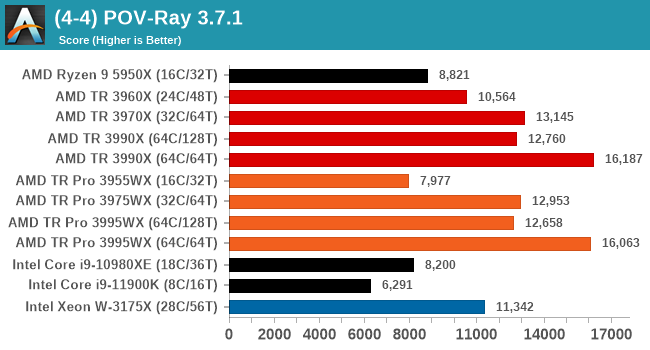
POV-Ray seems to prefer the 64C/64T variants of Threadripper, but the difference between TR and TR Pro is ever so slightly in favor of the higher frequency TR processors.
V-Ray: Link
We have a couple of renderers and ray tracers in our suite already, however V-Ray’s benchmark came through for a requested benchmark enough for us to roll it into our suite. Built by ChaosGroup, V-Ray is a 3D rendering package compatible with a number of popular commercial imaging applications, such as 3ds Max, Maya, Undreal, Cinema 4D, and Blender.

We run the standard standalone benchmark application, but in an automated fashion to pull out the result in the form of kilosamples/second. We run the test six times and take an average of the valid results.
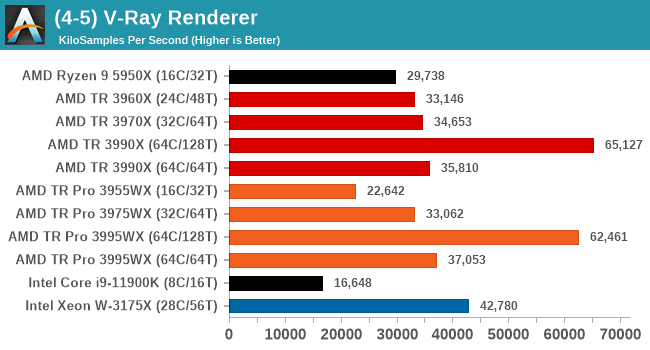
V-Ray shows benefit from having all 128 threads enabled, and it is interesting here that the performance difference between the 32c and 64c/64t options is next to zero. The W-3175X does well here by contrast, beating out the 32c variants.
Cinebench R20: Link
Another common stable of a benchmark suite is Cinebench. Based on Cinema4D, Cinebench is a purpose built benchmark machine that renders a scene with both single and multi-threaded options. The scene is identical in both cases. The R20 version means that it targets Cinema 4D R20, a slightly older version of the software which is currently on version R21. Cinebench R20 was launched given that the R15 version had been out a long time, and despite the difference between the benchmark and the latest version of the software on which it is based, Cinebench results are often quoted a lot in marketing materials.
Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code path. The results are output as a score from the software, which is directly proportional to the time taken. Using the benchmark flags for single CPU and multi-CPU workloads, we run the software from the command line which opens the test, runs it, and dumps the result into the console which is redirected to a text file. The test is repeated for a minimum of 10 minutes for both ST and MT, and then the runs averaged.
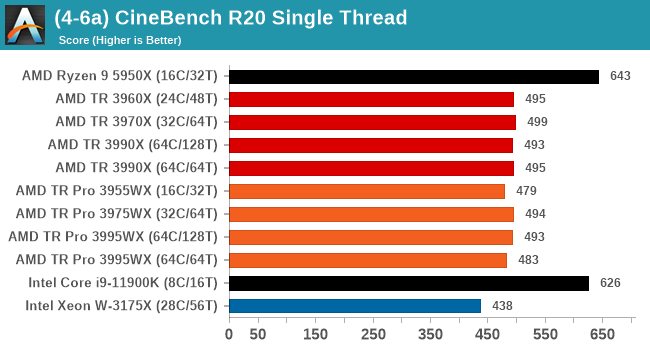
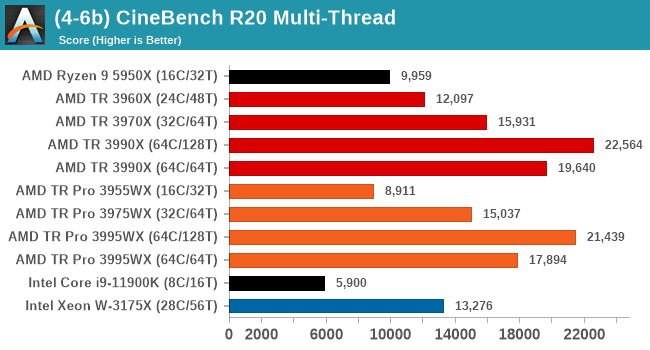
CBR20 scales up to 128 threads no problem, but we're seeing a preference in TR over TR Pro in this test where memory bandwidth doesn't matter much.
CPU Tests: Encoding
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake 1.32: Link
Video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codecs, VP9 and AV1, there are others that are prominent: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H.265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content. There are other codecs coming to market designed for specific use cases all the time.
Handbrake is a favored tool for transcoding, with the later versions using copious amounts of newer APIs to take advantage of co-processors, like GPUs. It is available on Windows via an interface or can be accessed through the command-line, with the latter making our testing easier, with a redirection operator for the console output.
We take the compiled version of this 16-minute YouTube video about Russian CPUs at 1080p30 h264 and convert into three different files: (1) 480p30 ‘Discord’, (2) 720p30 ‘YouTube’, and (3) 4K60 HEVC.
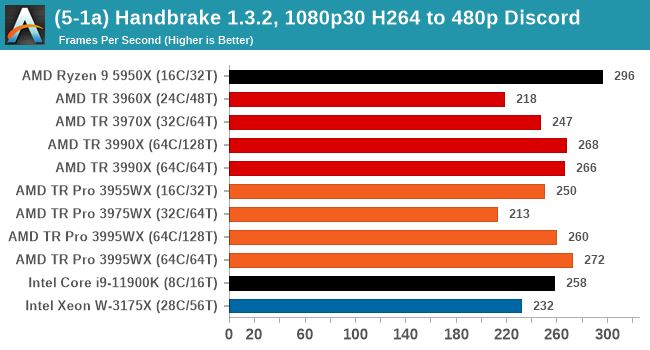
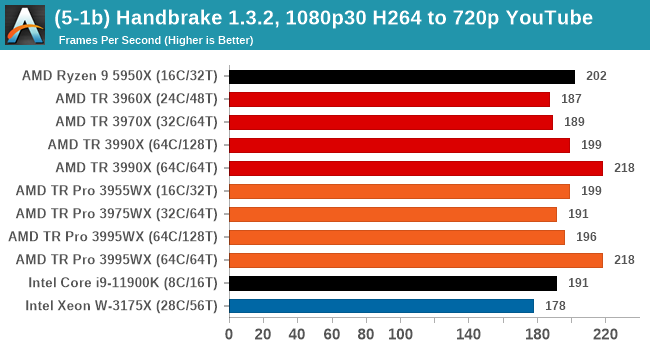
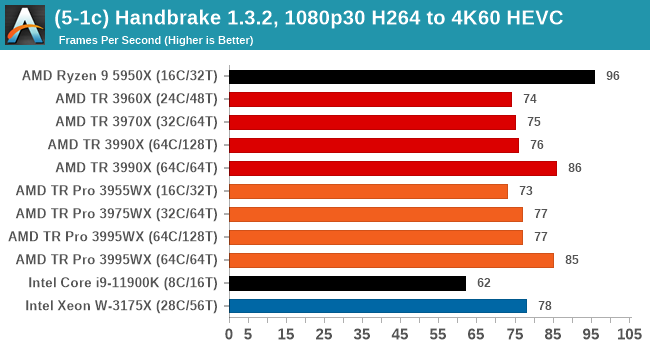
In every situation the R9 5950X does the best or near the best, but HB is one of those tests where running in 64C/64T mode does benefit the result by a good 10%. Otherwise there is little difference between TR and TR Pro.
7-Zip 1900: Link
The first compression benchmark tool we use is the open-source 7-zip, which typically offers good scaling across multiple cores. 7-zip is the compression tool most cited by readers as one they would rather see benchmarks on, and the program includes a built-in benchmark tool for both compression and decompression.
The tool can either be run from inside the software or through the command line. We take the latter route as it is easier to automate, obtain results, and put through our process. The command line flags available offer an option for repeated runs, and the output provides the average automatically through the console. We direct this output into a text file and regex the required values for compression, decompression, and a combined score.
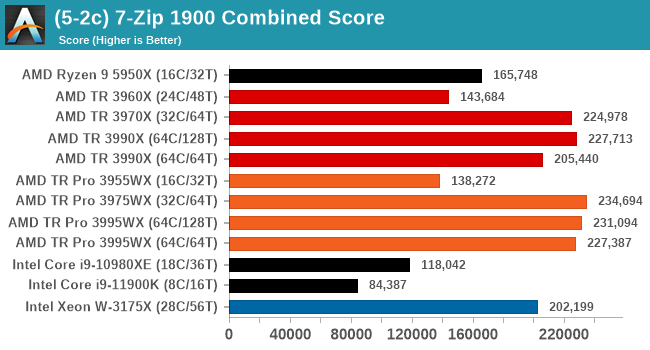
7-zip tends to like memory bandwidth as well as compute, however this test seems to top out at 64 threads, so any processor above that is scoring roughly the same. The 3990X result seems a little low, however.
AES Encoding
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.
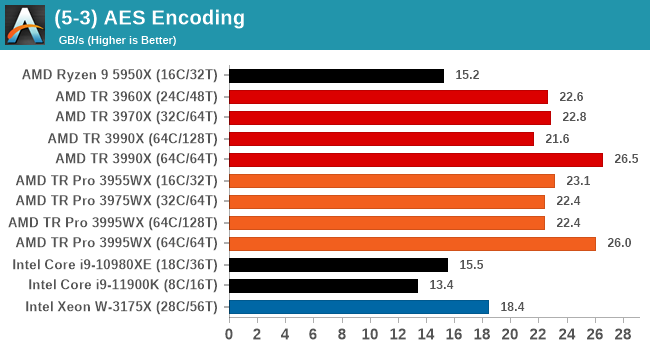
AES does like memory bandwidth, and the 64C/64T setting does best here.
WinRAR 5.90: Link
For the 2020 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack
- 33 video files , each 30 seconds, in 1.37 GB,
- 2834 smaller website files in 370 folders in 150 MB,
- 100 Beat Saber music tracks and input files, for 451 MB
This is a mixture of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test for 20 minutes times and take the average of the last five runs when the benchmark is in a steady state.
For automation, we use AHK’s internal timing tools from initiating the workload until the window closes signifying the end. This means the results are contained within AHK, with an average of the last 5 results being easy enough to calculate.
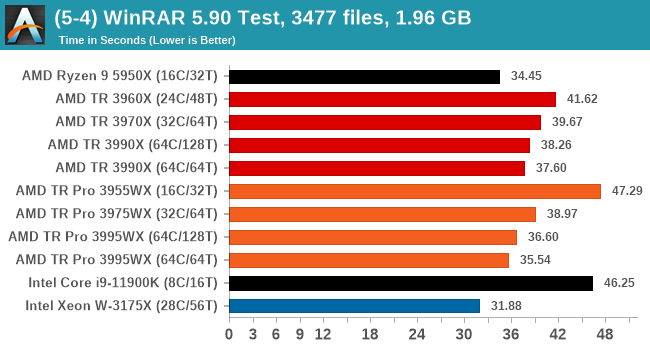
In this test we're looking for the smallest bars representing the lowest time, and 64C/64T has a slight advantage over the full 128T modes. There seems to be no real difference between TR and TR Pro here though - normally WinRAR likes having memory bandwidth, but it seems that there is enough to go around.
CPU Tests: Office and Science
Our previous set of ‘office’ benchmarks have often been a mix of science and synthetics, so this time we wanted to keep our office section purely on real world performance.
Agisoft Photoscan 1.3.3: link
The concept of Photoscan is about translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the final 3D model in both spatial accuracy and texturing accuracy. The algorithm has four stages, with some parts of the stages being single-threaded and others multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures.

For the update to version 1.3.3, the Agisoft software now supports command line operation. Agisoft provided us with a set of new images for this version of the test, and a python script to run it. We’ve modified the script slightly by changing some quality settings for the sake of the benchmark suite length, as well as adjusting how the final timing data is recorded. The python script dumps the results file in the format of our choosing. For our test we obtain the time for each stage of the benchmark, as well as the overall time.

Photoscan has variable thread scaling, so while in general we see better results with more threads, the frequency of the cores comes into play when 1-16 threads are needed in those portions of the calculation. As a result the 64C/64T versions are better here, and TR Pro has a slight advantage over TR due to memory bandwidth. Nonetheless, the consumer R9 5950X wins out.
Science
In this version of our test suite, all the science focused tests that aren’t ‘simulation’ work are now in our science section. This includes Brownian Motion, calculating digits of Pi, molecular dynamics, and for the first time, we’re trialing an artificial intelligence benchmark, both inference and training, that works under Windows using python and TensorFlow. Where possible these benchmarks have been optimized with the latest in vector instructions, except for the AI test – we were told that while it uses Intel’s Math Kernel Libraries, they’re optimized more for Linux than for Windows, and so it gives an interesting result when unoptimized software is used.
3D Particle Movement v2.1: Non-AVX and AVX2/AVX512
This is the latest version of this benchmark designed to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. This involves randomly moving particles in a 3D space using a set of algorithms that define random movement. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in.
The initial version of v2.1 is a custom C++ binary of my own code, and flags are in place to allow for multiple loops of the code with a custom benchmark length. By default this version runs six times and outputs the average score to the console, which we capture with a redirection operator that writes to file.
For v2.1, we also have a fully optimized AVX2/AVX512 version, which uses intrinsics to get the best performance out of the software. This was done by a former Intel AVX-512 engineer who now works elsewhere. According to Jim Keller, there are only a couple dozen or so people who understand how to extract the best performance out of a CPU, and this guy is one of them. To keep things honest, AMD also has a copy of the code, but has not proposed any changes.
The 3DPM test is set to output millions of movements per second, rather than time to complete a fixed number of movements.
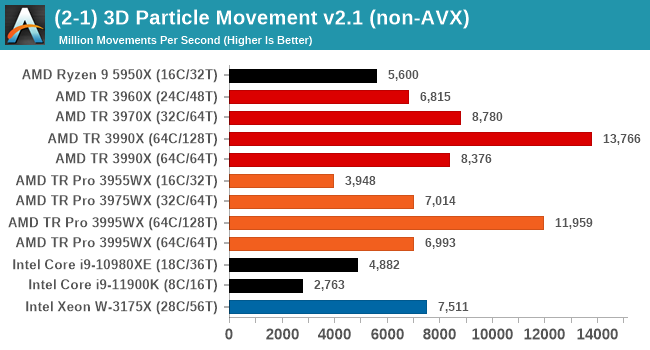
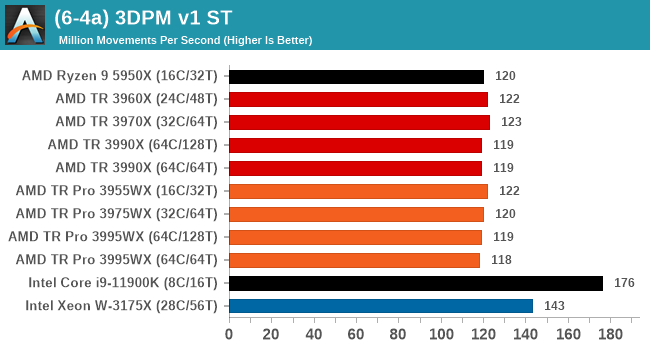
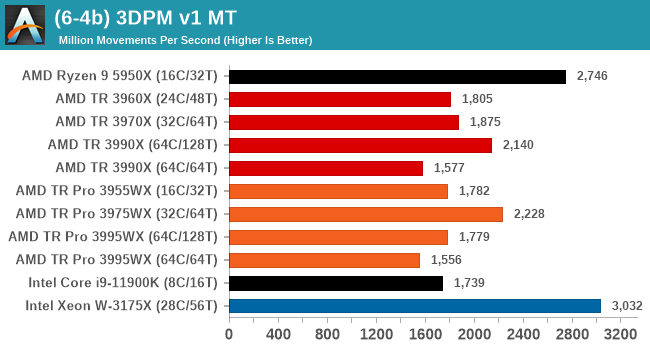
In a non-AVX mode, having a full 128 threads works best here, and TR beats TR Pro because there is very little memory bandwidth required.
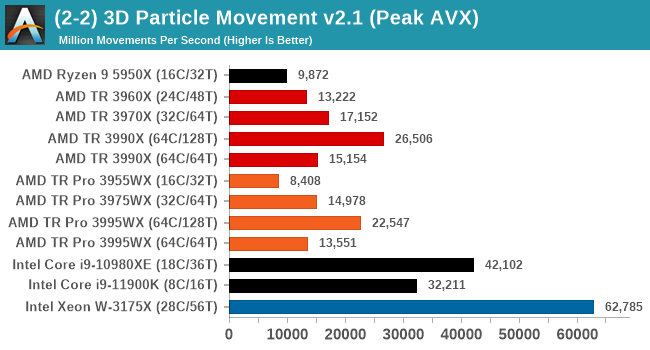
When we move into peak performance mode, the Intel chips with AVX512 scream out ahead. The AMD processors still get a rough 2x performance increase with AVX2, but the order still remains.
y-Cruncher 0.78.9506: www.numberworld.org/y-cruncher
If you ask anyone what sort of computer holds the world record for calculating the most digits of pi, I can guarantee that a good portion of those answers might point to some colossus super computer built into a mountain by a super-villain. Fortunately nothing could be further from the truth – the computer with the record is a quad socket Ivy Bridge server with 300 TB of storage. The software that was run to get that was y-cruncher.
Built by Alex Yee over the last part of a decade and some more, y-Cruncher is the software of choice for calculating billions and trillions of digits of the most popular mathematical constants. The software has held the world record for Pi since August 2010, and has broken the record a total of 7 times since. It also holds records for e, the Golden Ratio, and others. According to Alex, the program runs around 500,000 lines of code, and he has multiple binaries each optimized for different families of processors, such as Zen, Ice Lake, Sky Lake, all the way back to Nehalem, using the latest SSE/AVX2/AVX512 instructions where they fit in, and then further optimized for how each core is built.
For our purposes, we’re calculating Pi, as it is more compute bound than memory bound. In single thread mode we calculate 250 million digits, while in multithreaded mode we go for 2.5 billion digits. That 2.5 billion digit value requires ~12 GB of DRAM, and so is limited to systems with at least 16 GB.
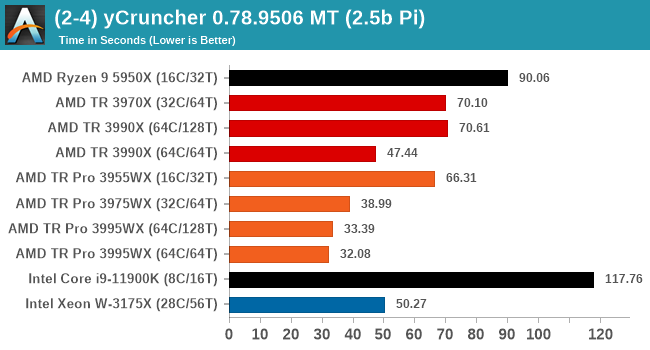
In full multithreaded mode, y-Cruncher eats memory bandwidth for breakfast. TR Pro is the clear winner here, but also bandwidth per core is important, and 64C/64T is preferred.
NAMD 2.13 (ApoA1): Molecular Dynamics
One of the popular science fields is modeling the dynamics of proteins. By looking at how the energy of active sites within a large protein structure over time, scientists behind the research can calculate required activation energies for potential interactions. This becomes very important in drug discovery. Molecular dynamics also plays a large role in protein folding, and in understanding what happens when proteins misfold, and what can be done to prevent it. Two of the most popular molecular dynamics packages in use today are NAMD and GROMACS.
NAMD, or Nanoscale Molecular Dynamics, has already been used in extensive Coronavirus research on the Frontier supercomputer. Typical simulations using the package are measured in how many nanoseconds per day can be calculated with the given hardware, and the ApoA1 protein (92,224 atoms) has been the standard model for molecular dynamics simulation.
Luckily the compute can home in on a typical ‘nanoseconds-per-day’ rate after only 60 seconds of simulation, however we stretch that out to 10 minutes to take a more sustained value, as by that time most turbo limits should be surpassed. The simulation itself works with 2 femtosecond timesteps. We use version 2.13 as this was the recommended version at the time of integrating this benchmark into our suite. The latest nightly builds we’re aware have started to enable support for AVX-512, however due to consistency in our benchmark suite, we are retaining with 2.13. Other software that we test with has AVX-512 acceleration.
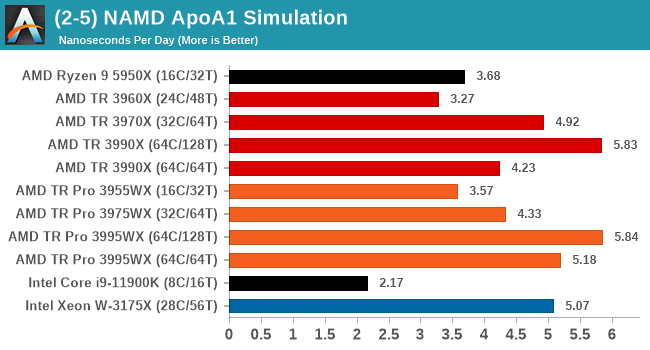
NAMD can use all 128 threads, showcasing 64C/128T as being the better performer. Interestingly though the TR 3990X doesn't do so well here at 64C/64T, but the 3995WX does.
AI Benchmark 0.1.2 using TensorFlow: Link
Finding an appropriate artificial intelligence benchmark for Windows has been a holy grail of mine for quite a while. The problem is that AI is such a fast moving, fast paced word that whatever I compute this quarter will no longer be relevant in the next, and one of the key metrics in this benchmarking suite is being able to keep data over a long period of time. We’ve had AI benchmarks on smartphones for a while, given that smartphones are a better target for AI workloads, but it also makes some sense that everything on PC is geared towards Linux as well.
Thankfully however, the good folks over at ETH Zurich in Switzerland have converted their smartphone AI benchmark into something that’s useable in Windows. It uses TensorFlow, and for our benchmark purposes we’ve locked our testing down to TensorFlow 2.10, AI Benchmark 0.1.2, while using Python 3.7.6.

The benchmark runs through 19 different networks including MobileNet-V2, ResNet-V2, VGG-19 Super-Res, NVIDIA-SPADE, PSPNet, DeepLab, Pixel-RNN, and GNMT-Translation. All the tests probe both the inference and the training at various input sizes and batch sizes, except the translation that only does inference. It measures the time taken to do a given amount of work, and spits out a value at the end.
There is one big caveat for all of this, however. Speaking with the folks over at ETH, they use Intel’s Math Kernel Libraries (MKL) for Windows, and they’re seeing some incredible drawbacks. I was told that MKL for Windows doesn’t play well with multiple threads, and as a result any Windows results are going to perform a lot worse than Linux results. On top of that, after a given number of threads (~16), MKL kind of gives up and performance drops of quite substantially.
So why test it at all? Firstly, because we need an AI benchmark, and a bad one is still better than not having one at all. Secondly, if MKL on Windows is the problem, then by publicizing the test, it might just put a boot somewhere for MKL to get fixed. To that end, we’ll stay with the benchmark as long as it remains feasible.
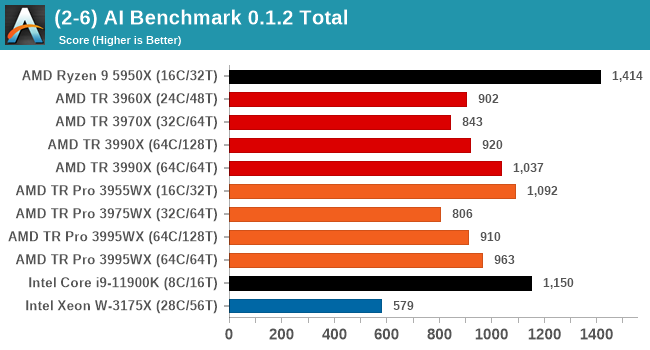
This benchmark likes high IPC, and R9 has it in spades.
CPU Tests: Simulation
Simulation and Science have a lot of overlap in the benchmarking world, however for this distinction we’re separating into two segments mostly based on the utility of the resulting data. The benchmarks that fall under Science have a distinct use for the data they output – in our Simulation section, these act more like synthetics but at some level are still trying to simulate a given environment.
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected. Results are shown as a multiple of real-time calculation.
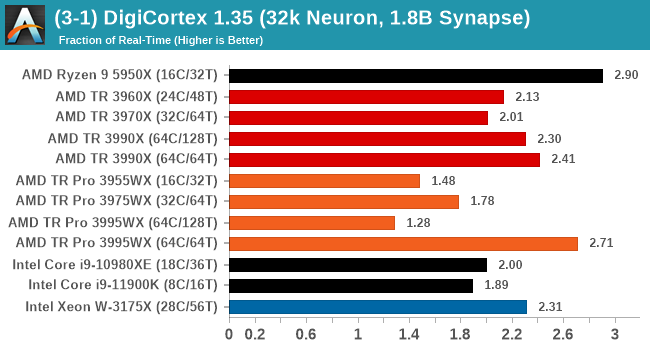
Normally DigiCortex likes memory bandwidth, but most of the TR Pro CPUs wilted in this test. The only mode that did not is the 3995WX in 64C/64T mode, perhaps showcasing this test runs better without SMT enabled.
Dwarf Fortress 0.44.12: Link
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006 and still being regularly updated today, aiming for a Steam launch sometime in the future.
Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes as it has to simulate more famous people, more world events, and the natural way that humanoid creatures take over an environment. Like some kind of virus.
For our test we’re using DFMark. DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. After analyzing the test, we ended up going for three different world generation sizes:
- Small, a 65x65 world with 250 years, 10 civilizations and 4 megabeasts
- Medium, a 127x127 world with 550 years, 10 civilizations and 4 megabeasts
- Large, a 257x257 world with 550 years, 40 civilizations and 10 megabeasts

DFMark outputs the time to run any given test, so this is what we use for the output. We loop the small test for as many times possible in 10 minutes, the medium test for as many times in 30 minutes, and the large test for as many times in an hour.
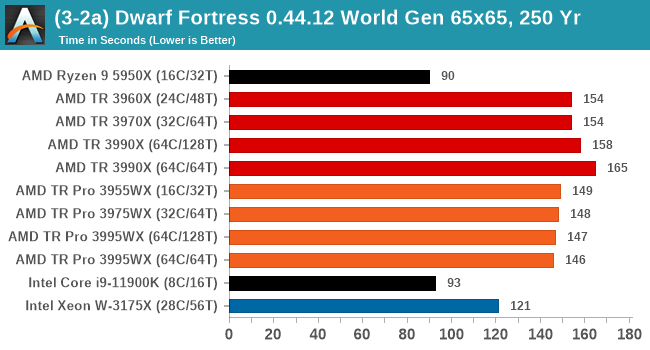
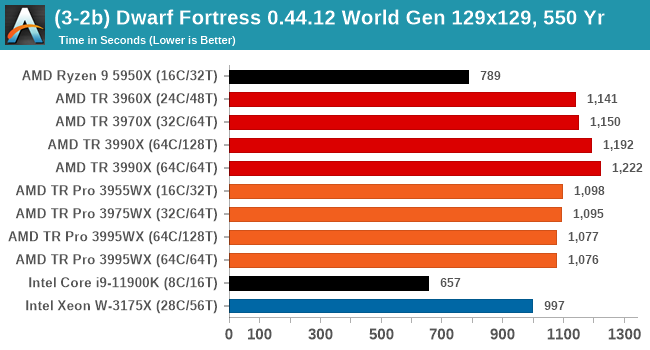
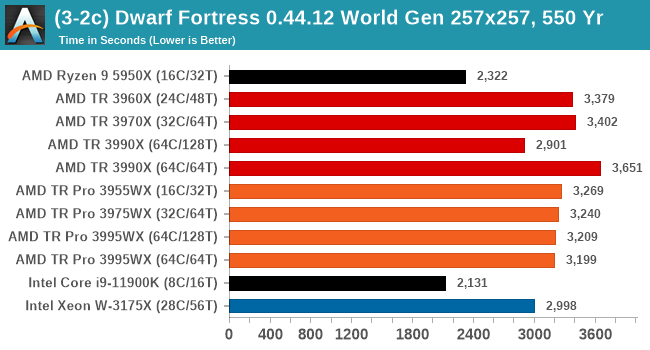
As a mostly ST test, the consumer processors do best here. However overall, TR Pro does better than TR.
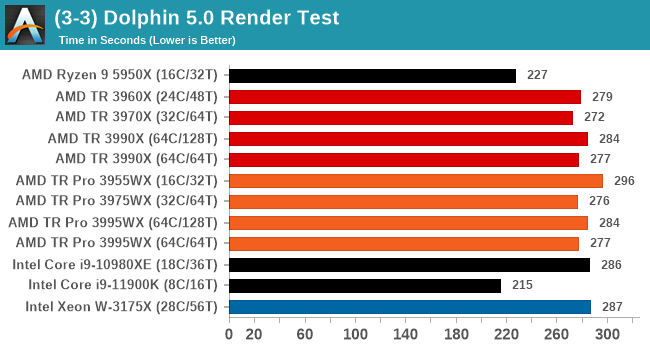
Dolphin v5.0 Emulation: Link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in seconds, where the Wii itself scores 1051 seconds.
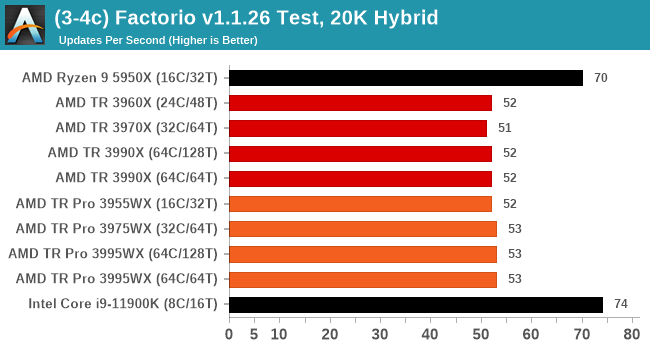
Factorio v1.1.26: Link
One of the most requested simulation game tests we’ve had in recently is that of Factorio, a construction and management title where the user builds endless automated factories of increasing complexity. Factorio falls under the same banner as other simulation games where users can lose hundreds of hours of sleepless nights configuring the minutae of their production line.
Our new benchmark here takes the v1.1.26 version of the game, a fixed map, and uses the automated benchmark mode to calculate how long it takes to run 1000 updates. This is then repeated for 5 minutes, and the best time to complete is used, reported in updates per second. The benchmark is single threaded and said to be reliant on cache size and memory.
Details for the benchmark can be found at this link.


CPU Tests: Legacy and Web
In order to gather data to compare with older benchmarks, we are still keeping a number of tests under our ‘legacy’ section. This includes all the former major versions of CineBench (R15, R11.5, R10) as well as x264 HD 3.0 and the first very naïve version of 3DPM v2.1. We won’t be transferring the data over from the old testing into Bench, otherwise it would be populated with 200 CPUs with only one data point, so it will fill up as we test more CPUs like the others.
The other section here is our web tests.
Web Tests: Kraken, Octane, and Speedometer
Benchmarking using web tools is always a bit difficult. Browsers change almost daily, and the way the web is used changes even quicker. While there is some scope for advanced computational based benchmarks, most users care about responsiveness, which requires a strong back-end to work quickly to provide on the front-end. The benchmarks we chose for our web tests are essentially industry standards – at least once upon a time.
It should be noted that for each test, the browser is closed and re-opened a new with a fresh cache. We use a fixed Chromium version for our tests with the update capabilities removed to ensure consistency.
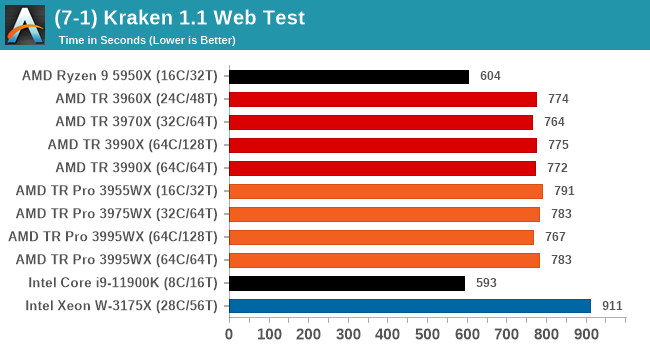
Mozilla Kraken 1.1
Kraken is a 2010 benchmark from Mozilla and does a series of JavaScript tests. These tests are a little more involved than previous tests, looking at artificial intelligence, audio manipulation, image manipulation, json parsing, and cryptographic functions. The benchmark starts with an initial download of data for the audio and imaging, and then runs through 10 times giving a timed result.

We loop through the 10-run test four times (so that’s a total of 40 runs), and average the four end-results. The result is given as time to complete the test, and we’re reaching a slow asymptotic limit with regards the highest IPC processors.
Google Octane 2.0
Our second test is also JavaScript based, but uses a lot more variation of newer JS techniques, such as object-oriented programming, kernel simulation, object creation/destruction, garbage collection, array manipulations, compiler latency and code execution.
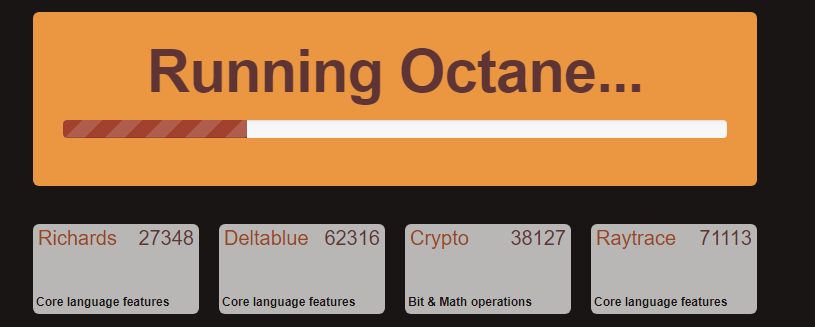
Octane was developed after the discontinuation of other tests, with the goal of being more web-like than previous tests. It has been a popular benchmark, making it an obvious target for optimizations in the JavaScript engines. Ultimately it was retired in early 2017 due to this, although it is still widely used as a tool to determine general CPU performance in a number of web tasks.
Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a test over a series of JavaScript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics.
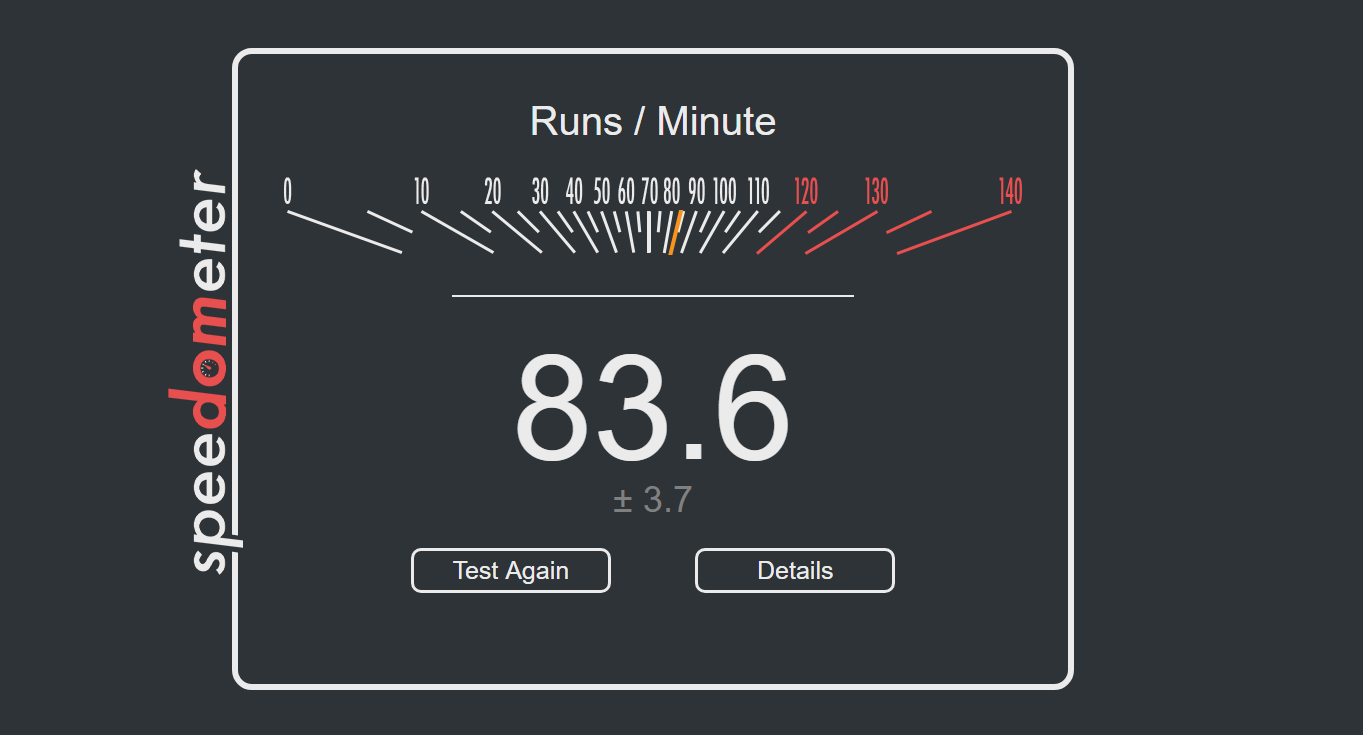
We repeat over the benchmark for a dozen loops, taking the average of the last five.
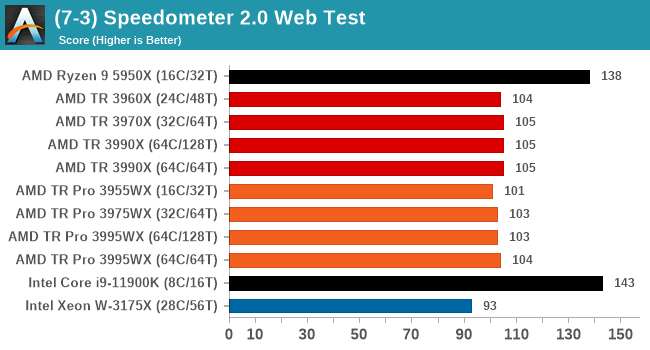
Legacy Tests
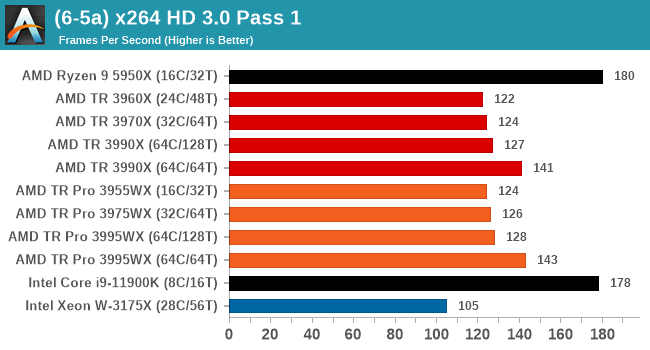
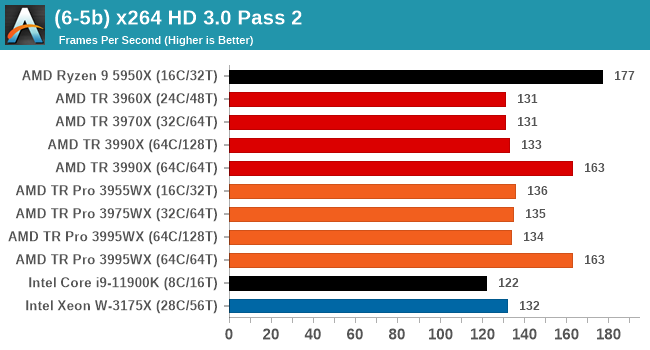
CPU Tests: Synthetic
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
Linux OpenSSL Speed: SHA256
One of our readers reached out in early 2020 and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode. All the graphs are in our benchmark database, Bench, and we use the sha256 results in published reviews.


AMD has had a sha256 accelerator in its processors for many years, whereas Intel only enabled SHA acceleration in Rocket Lake. That's why we see RKL matching TR in 1T mode, but when the cores get fired up, TR and TR Pro streak ahead with the available performance and memory bandwidth. This is all about threads here, and 128 threads really matters.
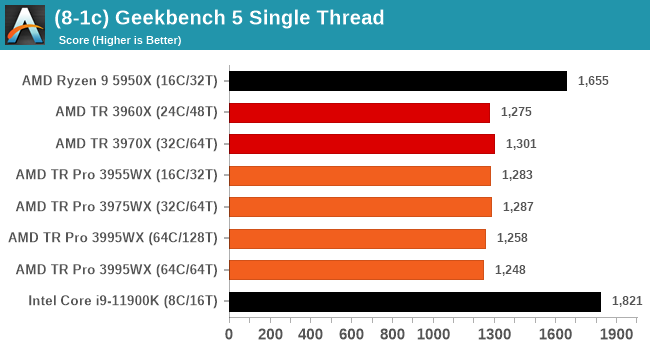
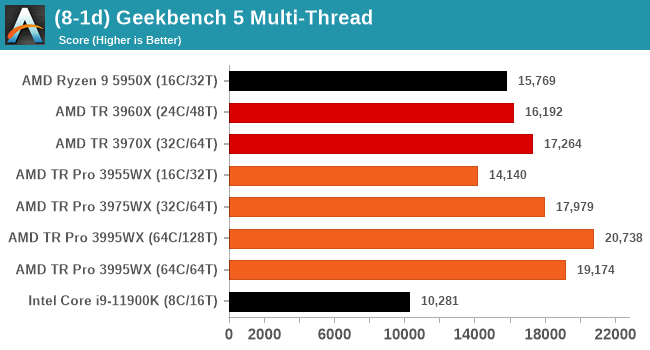
GeekBench 5: Link
As a common tool for cross-platform testing between mobile, PC, and Mac, GeekBench is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic.
DRAM Bandwidth
As we're moving from 2 channel memory on Ryzen to 4 channel memory on Threadripper then 8 channel memory on Threadripper Pro, these all have associated theoretical bandwidth maximums but there is a case for testing to see if those maximums can be reached. In this test, we do a simple memory write for peak bandwidth.
For 2-channel DDR4-3200, the theoretical maximum is 51.2 GB/s.
For 4-channel DDR4-3200, the theoretical maximum is 102.4 GB/s.
For 8-channel DDR4-3200, the theoretical maximum is 204.8 GB/s.
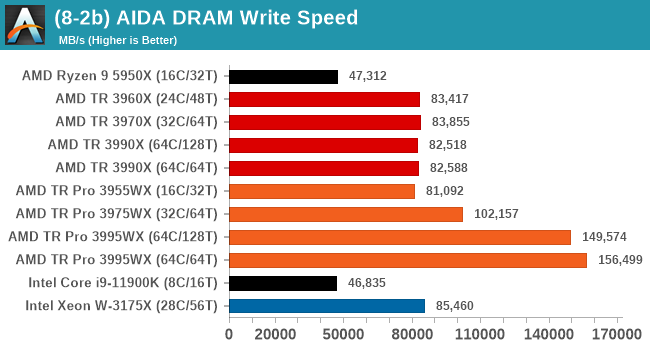
Here we see all the 4-channel Threadripper processors getting around 83 GB/s, but the Threadripper Pro can only achieve closer to its maximums when there are more cores present. Along with the memory controller bandwidth, AMD has to manage internal infinity fabric bandwidth and power to get the most out of the system. The fact that the 64C/64T achieves better than the 64C/128T might suggest that in 128T there is some congestion.
CPU Tests: SPEC
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0-svn350067-1~exp1+0~20181226174230.701~1.gbp6019f2 (trunk)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark. All of the major vendors, AMD, Intel, and Arm, all support the way in which we are testing SPEC.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
For each of the SPEC targets we are doing, SPEC2006 rate-1, SPEC2017 rate-1, and SPEC2017 rate-N, rather than publish all the separate test data in our reviews, we are going to condense it down into a few interesting data points. The full per-test values are in our benchmark database.
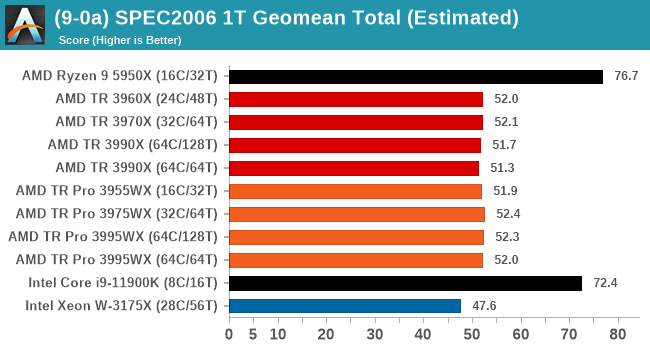
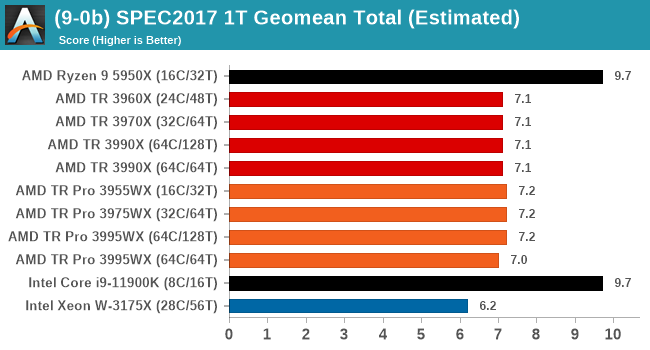
Single thread is very much what we expected, with the consumer processors out in the lead and no real major differences between TR and TR Pro.
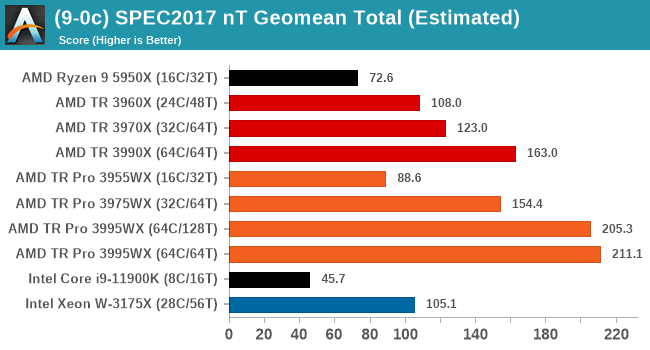
That changes when we move into full thread mode. The extra bandwidth of TR Pro is clear to see, even in the 32C/64T model. In this test we're using 128 GB of memory for all TR and TR Pro processors, and we're seeing a small bump when in 64C/64T mode, perhaps due to the increased memory cap/thread and memory bandwidth/thread as well. The 3990X 64C/128T run kept failing for an odd reason, so we do not have a score for that test.
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
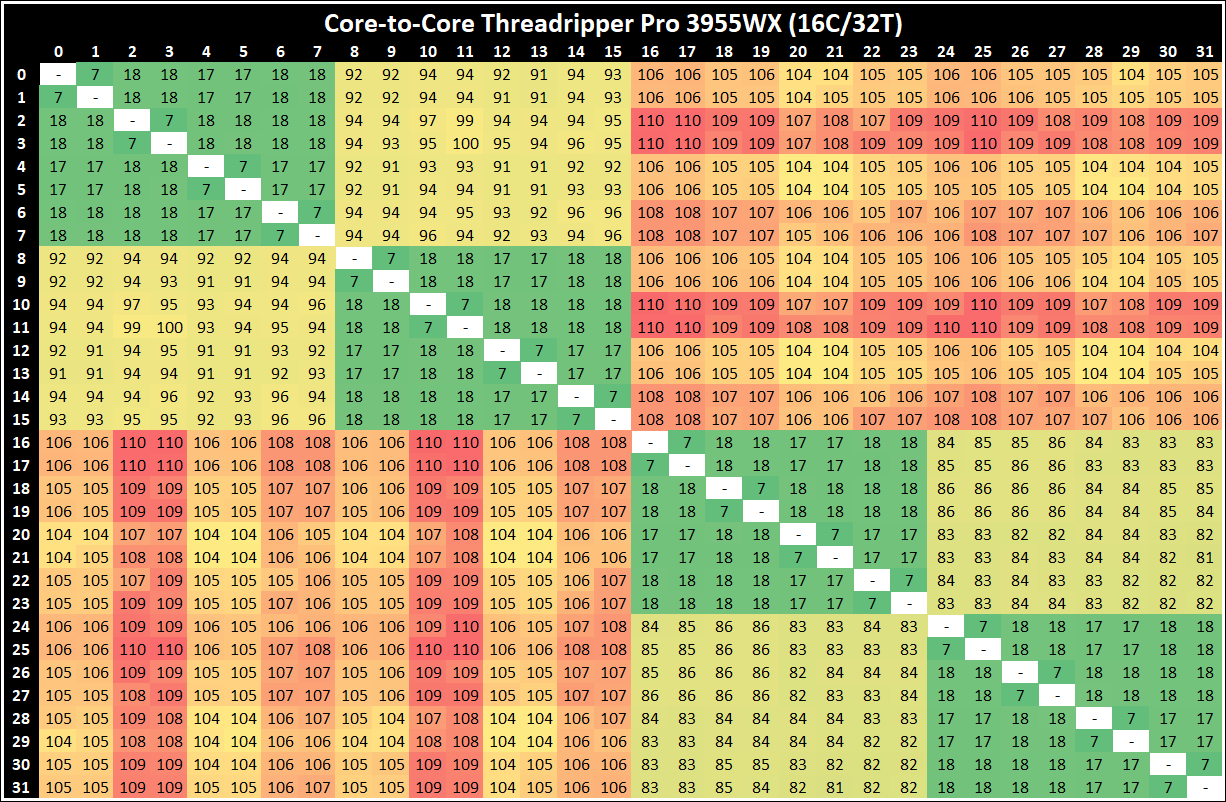
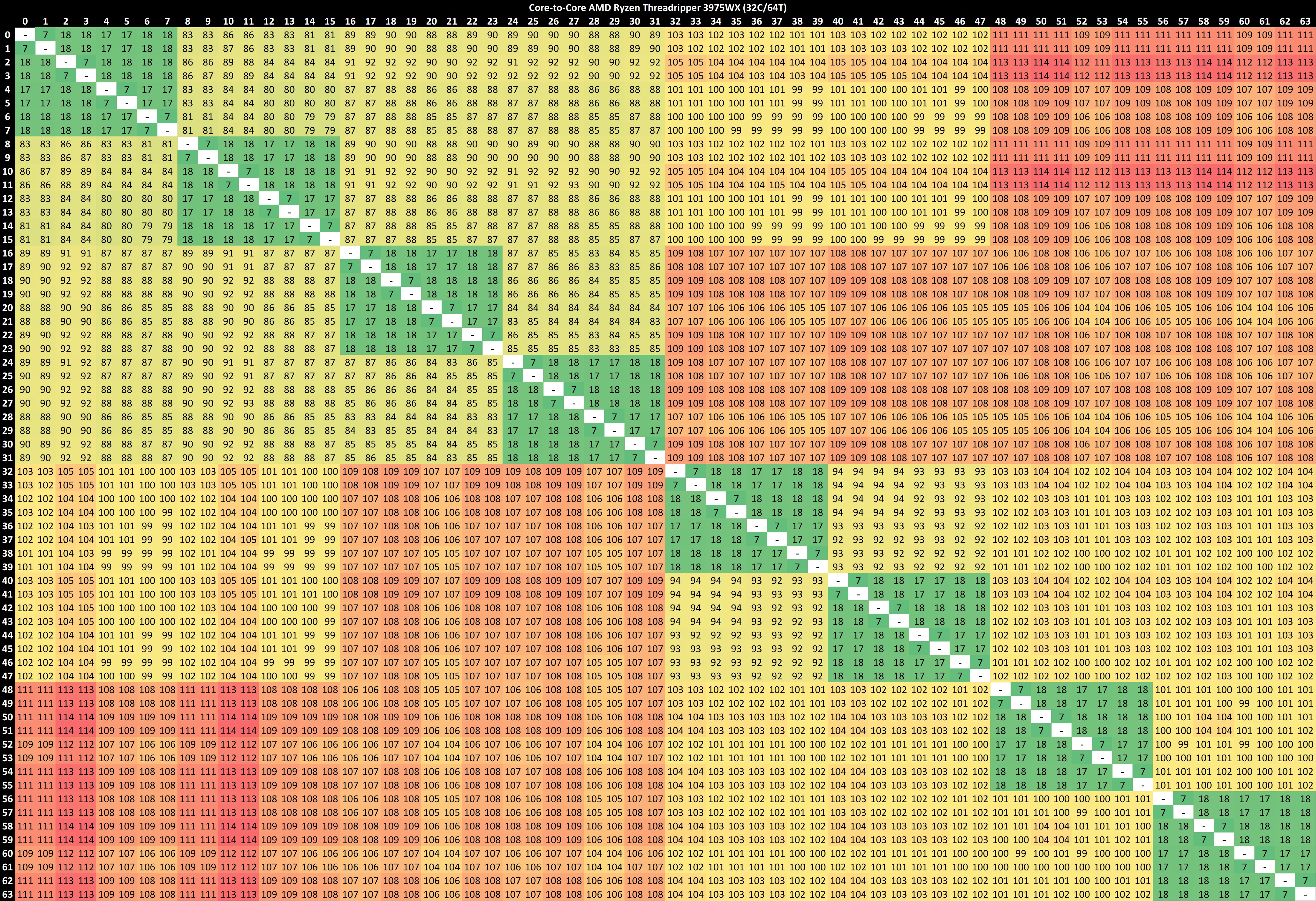
On all our Threadripper Pro CPUs, we saw:
- a thread-to-thread latency of 7ns,
- a core-to-core in the same CCX latency as 17-18 nanoseconds,
- a core-to-core in a different CCX scale from 80 ns with no IO die hops to 113 with 3 IO die hops
Here we can distinuguish how long it takes for threads to ping back and forth with cores that are different hops across the IO die.
A y-Cruncher Sprint
The y-cruncher website has a large about of benchmark data showing how different CPUs perform to calculate specific values of pi. Below these there are a few CPUs where it shows the time to compute moving from 25 million digits to 50 million, 100 million, 250 million, and all the way up to 10 billion, to showcase how the performance scales with digits (assuming everything is in memory). This range of results, from 25 million to 250 billion, is something I’ve dubbed a ‘sprint’.
I have written some code in order to perform a sprint on every CPU we test. It detects the DRAM, works out the biggest value that can be calculated with that amount of memory, and works up from 25 million digits. For the tests that go up to the ~25 billion digits, it only adds an extra 15 minutes to the suite for an 8-core Ryzen CPU.
With this test, we can see the effect of increasing memory requirements on the workload and the scaling factor for a workload such as this. We're plotting milllions of digits calculated per second.
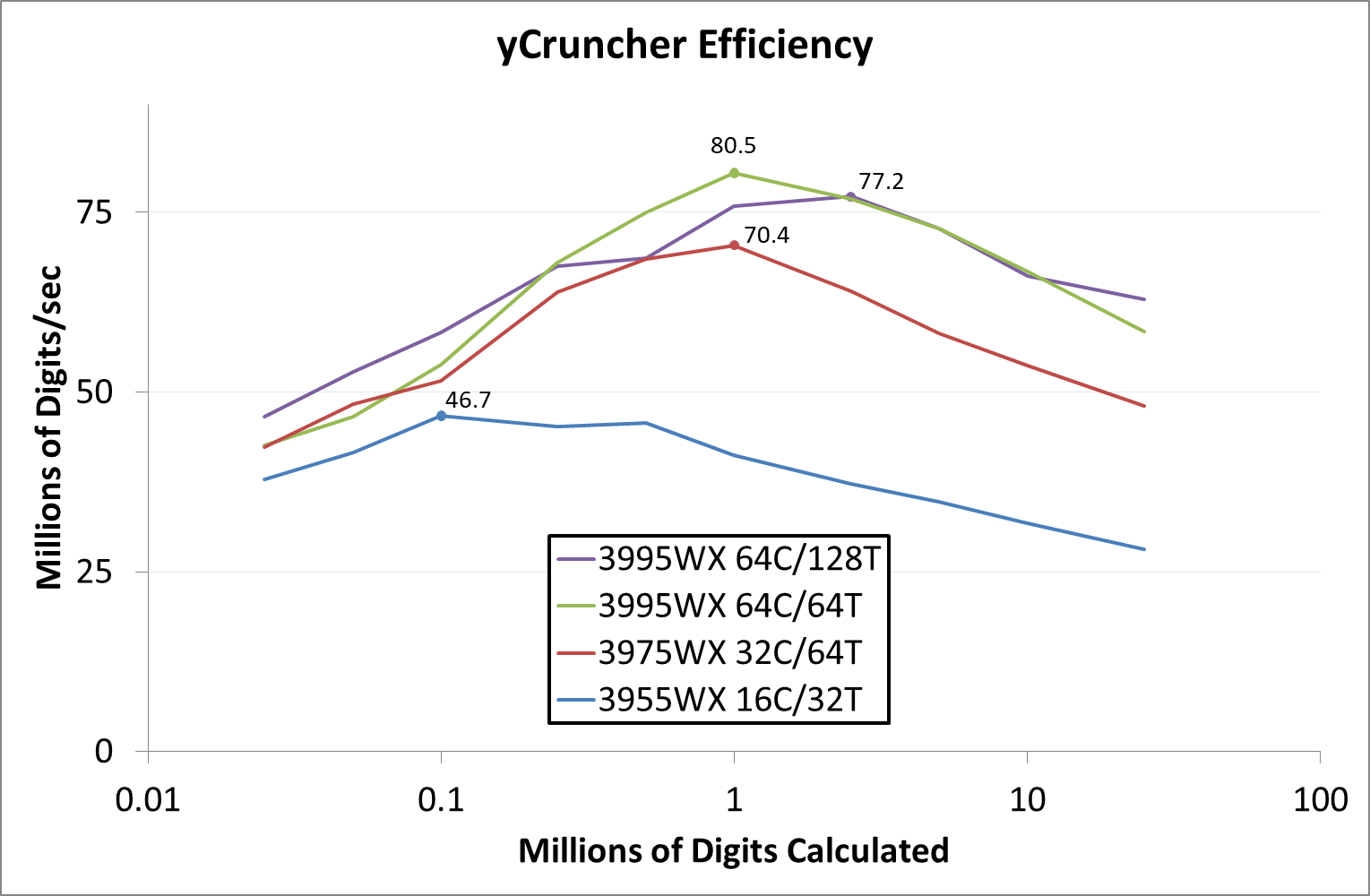
The 64C/64T processor obtains the peak efficiency here, although as more digits are calculated, the memory requirements come into play.
Conclusion
Threadripper Pro is designed to fill a niche in the workstation market. The workstation market has always been a little bit odd in that it wants the power and frequency of a high-end desktop, but the core count, memory support, and IO capabilities of servers. AMD blurred the lines by moving its mainstream desktop platform to 16 cores, but failed to meet memory and IO requirements – Threadripper got part of the way there, going up to 32 cores and then 64 cores with more memory and IO, but it was still limiting in support for things like ECC. That’s where Threadripper Pro comes in.
The whole point of Threadripper Pro is to appeal to those that need the features of EPYC but none of the downsides of potentially lower performance or extended service contracts. EPYC, by and large, has been sold only at the system level, whereas Threadripper Pro can be purchased at retail, and the goal of the product is to be ISV verified for standard workstation applications. In a world without Threadripper Pro, users who want the platform can either get a Threadripper and lament the reduced memory performance and IO, or they could get an EPYC and lament the reduced core performance. Speaking with OEMs, there are some verticals (like visual effects) that requested versions of Threadripper with Pro features, such as remote management, or remote access when WFH with a proper admin security stack. Even though TR Pro fills a niche, it’s still a niche.
In our testing today, we benchmarked all three retail versions of Threadripper Pro in a retail motherboard, and compared them to the Threadripper 3000 series.
| AMD Comparison | |||||||
| AnandTech | Cores | Base Freq |
Turbo Freq |
Chips | L3 Cache |
TDP | Price SEP |
| AMD EPYC (Zen 3, 128 PCIe 4.0, 8 channel DDR4 ECC) | |||||||
| 7763 (2P) | 64 / 128 | 2450 | 3500 | 8 + 1 | 256 MB | 280 W | $7890 |
| 7713P | 64 / 128 | 2000 | 3675 | 8 + 1 | 256 MB | 225 W | $5010 |
| 7543P | 32 / 64 | 2800 | 3700 | 8 + 1 | 256 MB | 225 W | $2730 |
| 7443P | 24 / 48 | 2850 | 4000 | 4 + 1 | 128 MB | 200 W | $1337 |
| 7313P | 16 / 32 | 3000 | 3700 | 4 + 1 | 128 MB | 155 W | $913 |
| AMD Threadripper Pro (Zen 2, 128 PCIe 4.0, 8 channel DDR4-ECC) | |||||||
| 3995WX | 64 / 128 | 2700 | 4200 | 8 + 1 | 256 MB | 280 W | $5490 |
| 3975WX | 32 / 64 | 3500 | 4200 | 4 + 1 | 128 MB | 280 W | $2750 |
| 3955WX | 16 / 32 | 3900 | 4300 | 2 + 1 | 64 MB | 280 W | $1150 |
| 3945WX | 12 / 24 | 4000 | 4300 | 2 + 1 | 64 MB | 280 W | OEM |
| AMD Threadripper (Zen 2, 64 PCIe 4.0, 4 channel DDR) | |||||||
| 3990X | 64 / 128 | 2900 | 4300 | 8 + 1 | 256 MB | 280 W | $3990 |
| 3970X | 32 / 64 | 3700 | 4500 | 4 + 1 | 128 MB | 280 W | $1999 |
| 3960X | 24 / 48 | 3800 | 4500 | 4 + 1 | 128 MB | 280 W | $1399 |
| AMD Ryzen (Zen 3, 20 PCIe 4.0, 2 channel DDR) | |||||||
| R9 5950X | 16 / 32 | 3400 | 4900 | 2 + 1 | 64 MB | 105 W | $799 |
Performance between Threadripper Pro and Threadripper came in three stages. Either (a) the results between similar processors was practically identical, (b) Threadripper beat TR Pro by a small margin due to slightly higher frequencies, or (c) TR Pro thrashed Threadripper due to memory bandwidth availability. That last point, (c), only really kicks in for the 32c and 64c processors it should be noted. Our 16c TR Pro had the same memory bandwidth results as TR, most likely due to only having two chiplets in its design.
In the end, that’s what TR Pro is there for – features that Threadripper doesn’t have. If you absolutely need up to 2 TB of eight-channel memory over 256 GB, you need TR Pro. If you absolutely need memory with ECC, then TR Pro has validated support. If you absolutely need 128 lanes of PCIe 4.0 rather than 64, then TR Pro has it. If you absolutely need Pro features, then TR Pro has it.
The price you pay for these Threadripper Pro features is an extra 37.5% over Threadripper. The corollary is that TR Pro is also more expensive than 1P EPYC processors because it has the full 280 W frequency profile, while EPYC 1P is only at 225W/240W. EPYC does have 280 W processors for dual-socket platforms, such as the 7763, but they cost more than TR Pro.
The benefit to EPYC right now is that EPYC Milan uses Zen 3 cores, while Threadripper Pro is using Zen 2 cores. We are patiently waiting for AMD to launch Threadripper versions with Zen 3 – we hoped it would have been at Computex in June, but now we’re not sure exactly when. Even if AMD does launch Threadripper with Zen 3 this year, Threadripper Pro variants might take longer to arrive.






