Original Link: https://www.anandtech.com/show/16252/mac-mini-apple-m1-tested
The 2020 Mac Mini Unleashed: Putting Apple Silicon M1 To The Test
by Andrei Frumusanu on November 17, 2020 9:00 AM EST
Last week, Apple made industry news by announcing new Mac products based upon the company’s new Apple Silicon M1 SoC chip, marking the first move of a planned 2-year roadmap to transition over from Intel-based x86 CPUs to the company’s own in-house designed microprocessors running on the Arm instruction set.
During the launch we had prepared an extensive article based on the company’s already related Apple A14 chip, found in the new generation iPhone 12 phones. This includes a rather extensive microarchitectural deep-dive into Apple’s new Firestorm cores which power both the A14 as well as the new Apple Silicon M1, I would recommend a read if you haven’t had the opportunity yet:
Since a few days, we’ve been able to get our hands on one of the first Apple Silicon M1 devices: the new Mac mini 2020 edition. While in our analysis article last week we had based our numbers on the A14, this time around we’ve measured the real performance on the actual new higher-power design. We haven’t had much time, but we’ll be bringing you the key datapoints relevant to the new Apple Silicon M1.
Apple Silicon M1: Firestorm cores at 3.2GHz & ~20-24W TDP?
During the launch event, one thing that was in Apple fashion typically missing from the presentation were actual details on the clock frequencies of the design, as well as its TDP which it can sustain at maximum performance.
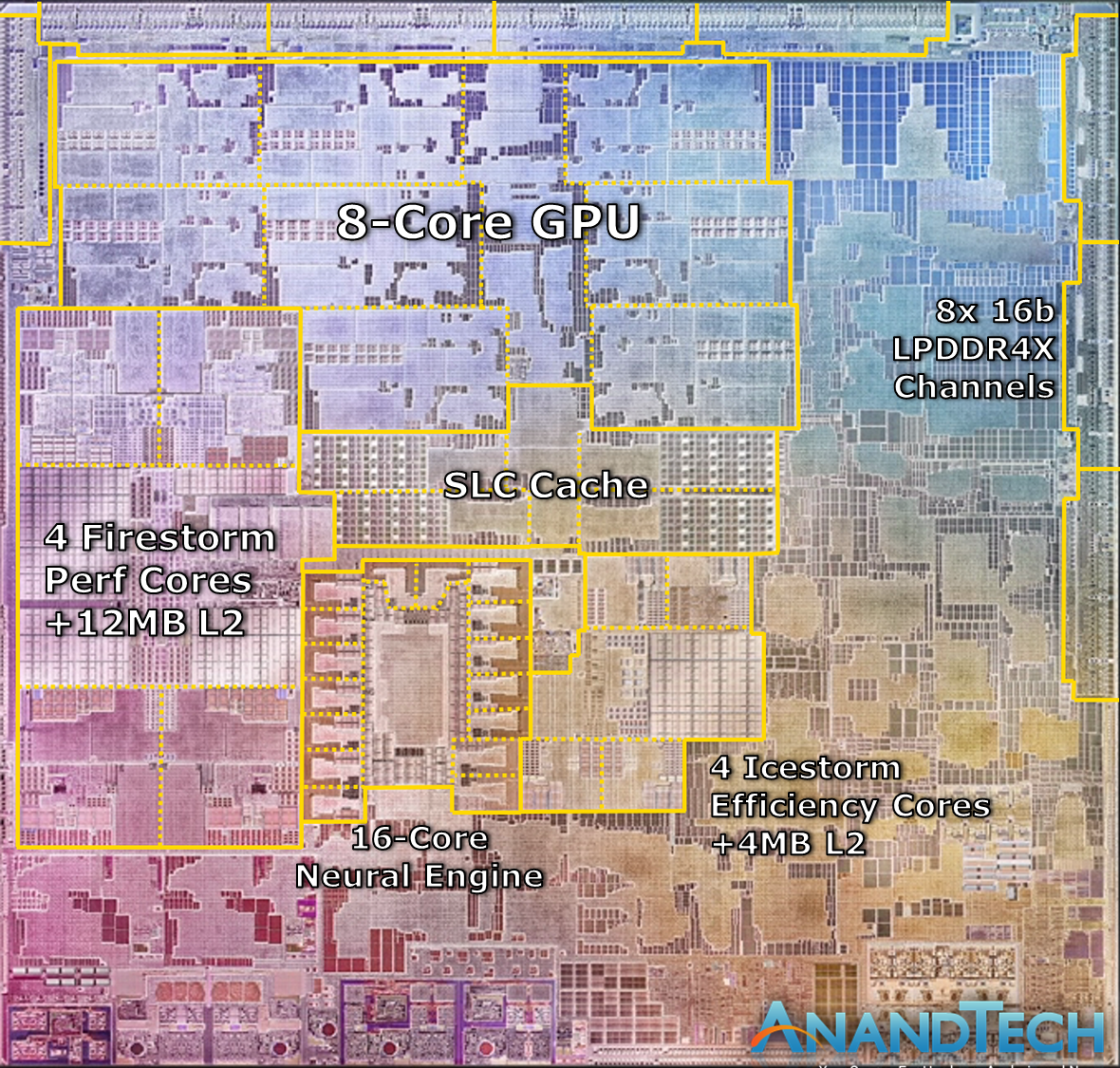
We can confirm that in single-threaded workloads, Apple’s Firestorm cores now clock in at 3.2GHz, a 6.66% increase over the 3GHz frequency of the Apple A14. As long as there's thermal headroom, this clock also applies to all-core loads, with in addition to 4x 3.2GHz performance cores also seeing 4x Thunder efficiency cores at 2064MHz, also quite a lot higher than 1823MHz on the A14.
Alongside the four performance Firestorm cores, the M1 also includes four Icestorm cores which are aimed for low idle power and increased power efficiency for battery-powered operation. Both the 4 performance cores and 4 efficiency cores can be active in tandem, meaning that this is an 8-core SoC, although performance throughput across all the cores isn’t identical.
The biggest question during the announcement event was the power consumption of these designs. Apple had presented several charts including performance and power axes, however we lacked comparison data as to come to any proper conclusion.
As we had access to the Mac mini rather than a Macbook, it meant that power measurement was rather simple on the device as we can just hook up a meter to the AC input of the device. It’s to be noted with a huge disclaimer that because we are measuring AC wall power here, the power figures aren’t directly comparable to that of battery-powered devices, as the Mac mini’s power supply will incur a efficiency loss greater than that of other mobile SoCs, as well as TDP figures contemporary vendors such as Intel or AMD publish.
It’s especially important to keep in mind that the figure of what we usually recall as TDP in processors is actually only a subset of the figures presented here, as beyond just the SoC we’re also measuring DRAM and voltage regulation overhead, something which is not included in TDP figures nor your typical package power readout on a laptop.
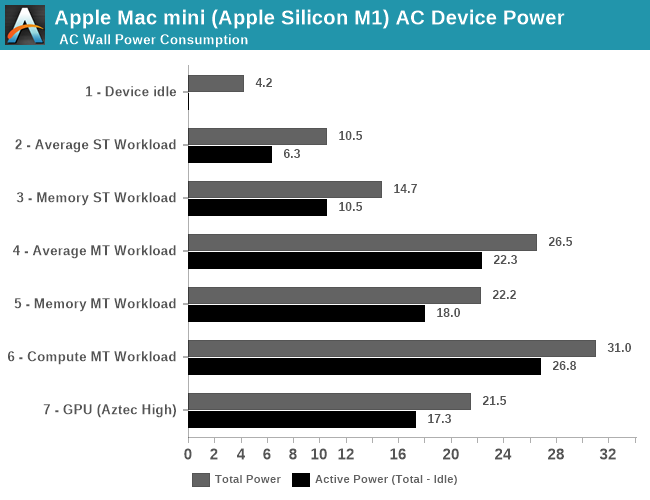
Starting off with an idle Mac mini in its default state while sitting idle when powered on, while connected via HDMI to a 2560p144 monitor, Wi-Fi 6 and a mouse and keyboard, we’re seeing total device power at 4.2W. Given that we’re measuring AC power into the device which can be quite inefficient at low loads, this makes quite a lot of sense and represents an excellent figure.
This idle figure also serves as a baseline for following measurements where we calculate “active power”, meaning our usual methodology of taking total power measured and subtracting the idle power.
During average single-threaded workloads on the 3.2GHz Firestorm cores, such as GCC code compilation, we’re seeing device power go up to 10.5W with active power at around 6.3W. The active power figure is very much in line with what we would expect from a higher-clocked Firestorm core, and is extremely promising for Apple and the M1.
In workloads which are more DRAM heavy and thus incur a larger power penalty on the LPDDR4X-class 128-bit 16GB of DRAM on the Mac mini, we’re seeing active power go up to 10.5W. Already with these figures the new M1 is might impressive and showcases less than a third of the power of a high-end Intel mobile CPU.
In multi-threaded scenarios, power highly depends on the workload. In memory-heavy workloads where the CPU utilisation isn’t as high, we’re seeing 18W active power, going up to around 22W in average workloads, and peaking around 27W in compute heavy workloads. These figures are generally what you’d like to compare to “TDPs” of other platforms, although again to get an apples-to-apples comparison you’d need to further subtract some of the overhead as measured on the Mac mini here – my best guess would be a 20 to 24W range.
Finally, on the part of the GPU, we’re seeing a lower power consumption figure of 17.3W in GFXBench Aztec High. This would contain a larger amount of DRAM power, so the power consumption of Apple’s GPU is definitely extremely low-power, and far less than the peak power that the CPUs can draw.
Memory Differences
Besides the additional cores on the part of the CPUs and GPU, one main performance factor of the M1 that differs from the A14 is the fact that’s it’s running on a 128-bit memory bus rather than the mobile 64-bit bus. Across 8x 16-bit memory channels and at LPDDR4X-4266-class memory, this means the M1 hits a peak of 68.25GB/s memory bandwidth.
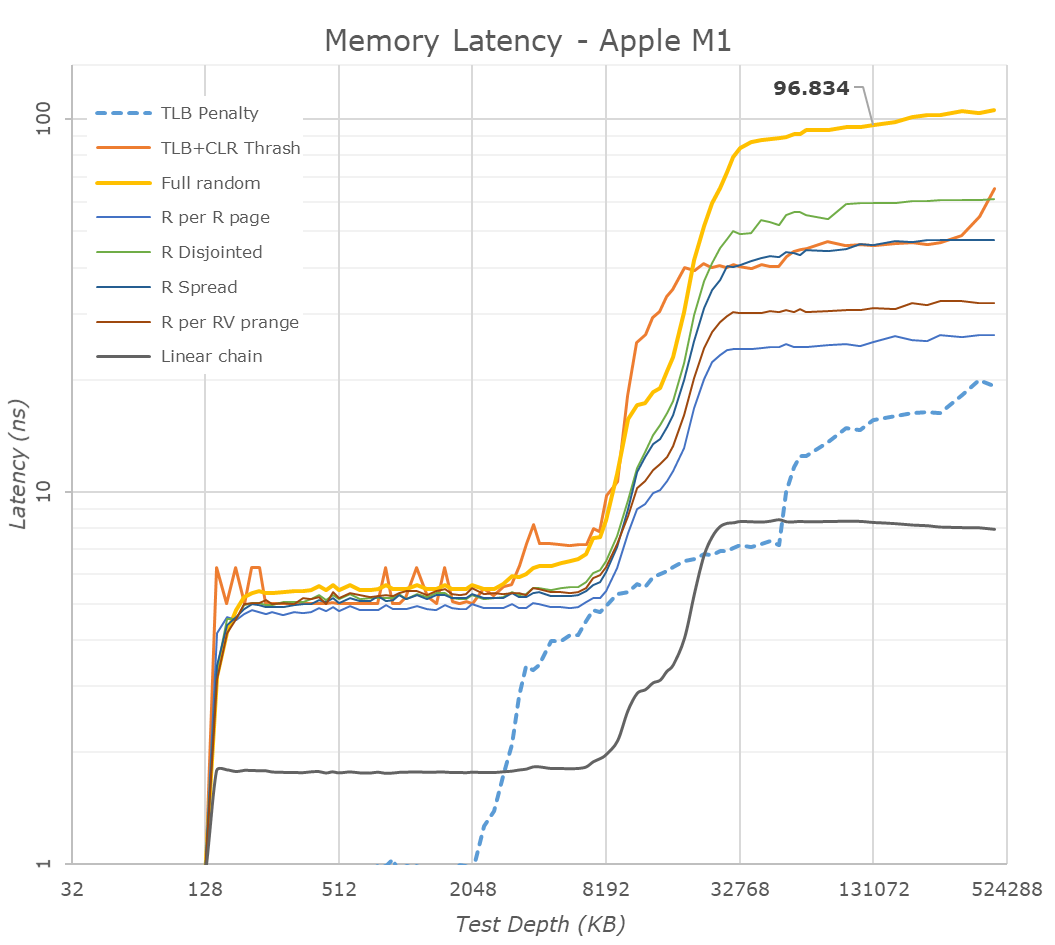
In terms of memory latency, we’re seeing a (rather expected) reduction compared to the A14, measuring 96ns at 128MB full random test depth, compared to 102ns on the A14.
Of further note is the 12MB L2 cache of the performance cores, although here it seems that Apple continues to do some partitioning as to how much as single core can use as we’re still seeing some latency uptick after 8MB.
The M1 also contains a large SLC cache which should be accessible by all IP blocks on the chip. We’re not exactly certain, but the test results do behave a lot like on the A14 and thus we assume this is a similar 16MB chunk of cache on the SoC, as some access patterns extend beyond that of the A14, which makes sense given the larger L2.
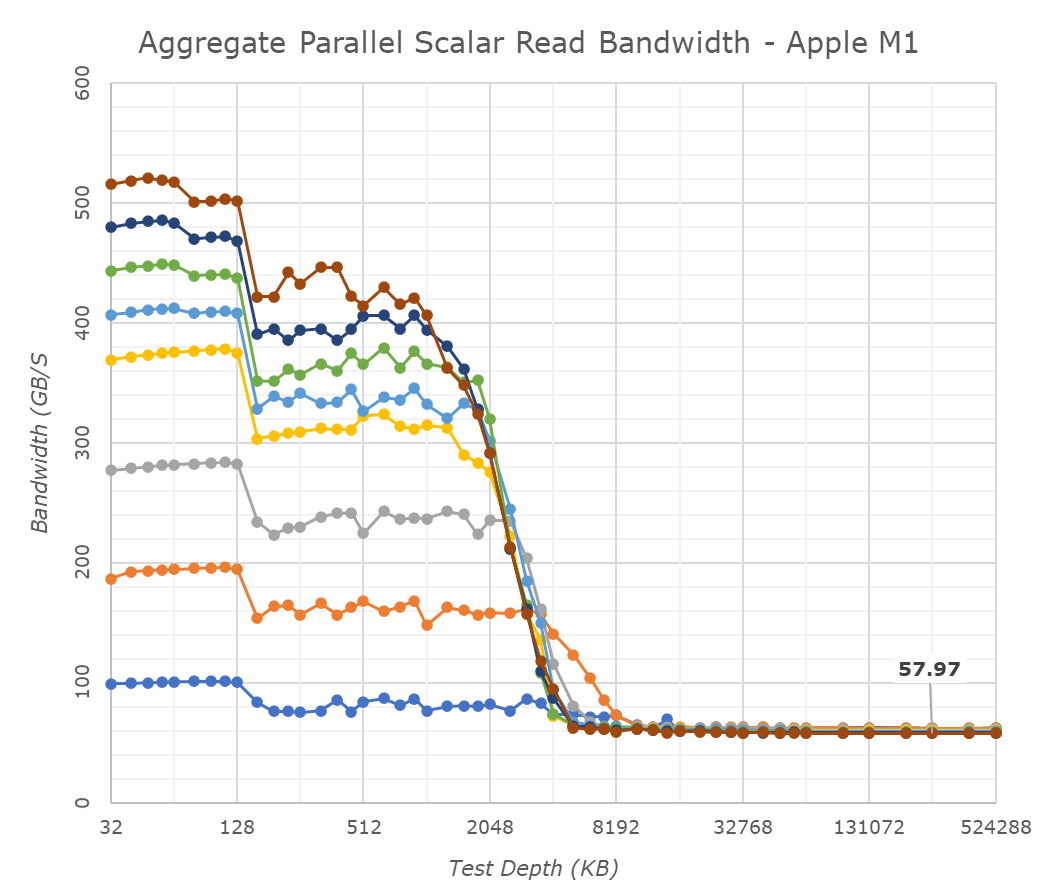
One aspect we’ve never really had the opportunity to test is exactly how good Apple’s cores are in terms of memory bandwidth. Inside of the M1, the results are ground-breaking: A single Firestorm achieves memory reads up to around 58GB/s, with memory writes coming in at 33-36GB/s. Most importantly, memory copies land in at 60 to 62GB/s depending if you’re using scalar or vector instructions. The fact that a single Firestorm core can almost saturate the memory controllers is astounding and something we’ve never seen in a design before.
Because one core is able to make use of almost the whole memory bandwidth, having multiple cores access things at the same time don’t actually increase the system bandwidth, but actually due to congestion lower the effective achieved aggregate bandwidth. Nevertheless, this 59GB/s peak bandwidth of one core is essentially also the speed at which memory copies happen, no matter the amount of active cores in the system, again, a great feat for Apple.
Beyond the clock speed increase, L2 increase, this memory boost is also very likely to help the M1 differentiate its performance beyond that of the A14, and offer up though competition against the x86 incumbents.
- Page 1: Apple Silicon M1: Recap, Power Consumption
- Page 2: Benchmarks: Whatever Is Available
- Page 3: M1 GPU Performance: Integrated King, Discrete Rival
- Page 4: SPEC2006 & 2017: Industry Standard - ST Performance
- Page 5: SPEC2017 - Multi-Core Performance
- Page 6: Rosetta2: x86-64 Translation Performance
- Page 7: Conclusion & First Impressions
Benchmarks: Whatever Is Available
As we’ve had very little time with the Mac mini, and the fact that this not only is a macOS system, but a new Arm64-based macOS system, our usual benchmark choices that we tend to use aren’t really available to us. We’ve made due with a assortment of available tests at the time of the launch to give us a rough idea of the performance:
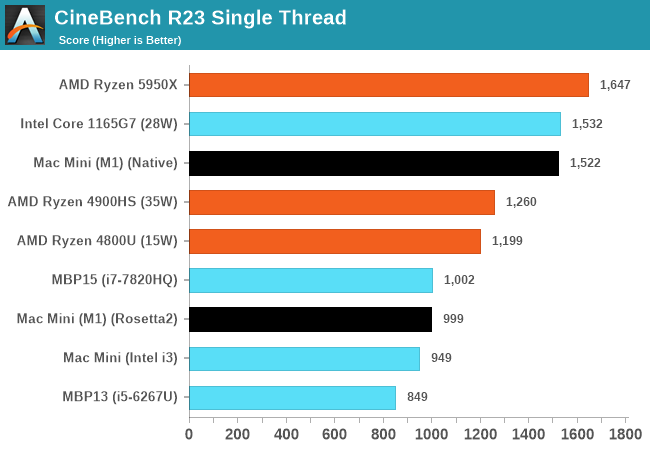
One particular benchmark that sees the first light of day on macOS as well as Apple Silicon is Cinebench. In this first-time view of the popular Cinema4D based benchmark, we see the Apple M1 toe-to-toe with the best-performing x86 CPUs on the market, vastly outperforming past Apple iterations of Intel silicon. The M1 here loses out to Zen3 and Tiger Lake CPUs, which still seem to have an advantage, although we’re not sure of the microarchitectural characteristics of the new benchmark.
What’s notable is the performance of the Rosetta2 run of the benchmark when in x86 mode, which is not only able to keep up with past Mac iterations but still also beat them.
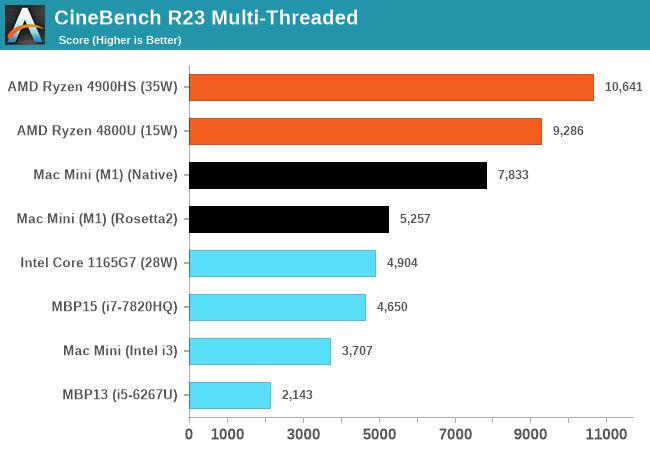
In the multi-threaded R23 runs, the M1 absolutely dominates past Macs with similar low-power CPUs. Just as of note, we’re trying to gather more data on other systems as we have access to them, and expand the graph in further updates of the article past publishing.
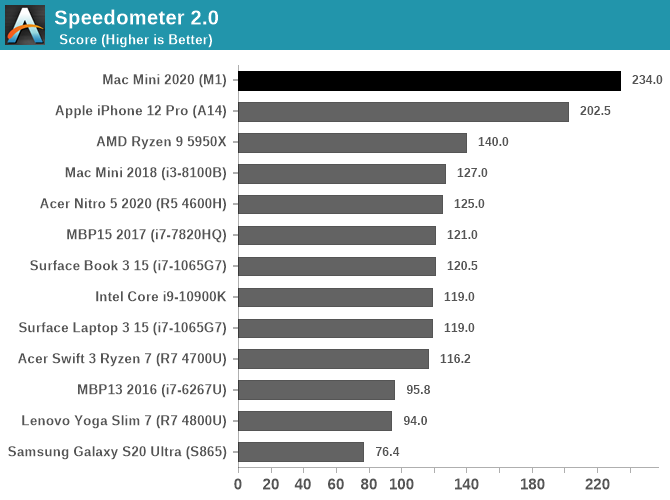
In browser-benchmarks we’ve known Apple’s CPUs to very much dominate across the landscape, but there were doubts as to whether this was due to the CPUs themselves in the iPhone or rather just the browsers and browser engines. Now running on macOS and desktop Safari, being able to compare data to other Intel Mac systems, we can come to the conclusion that the performance advantage is due to Apple’s CPU designs.
Web-browsing performance seems to be an extremely high priority for Apple’s CPU, and this makes sense as it’s the killer workload for mobile SoCs and the workload that one uses the most in everyday life.
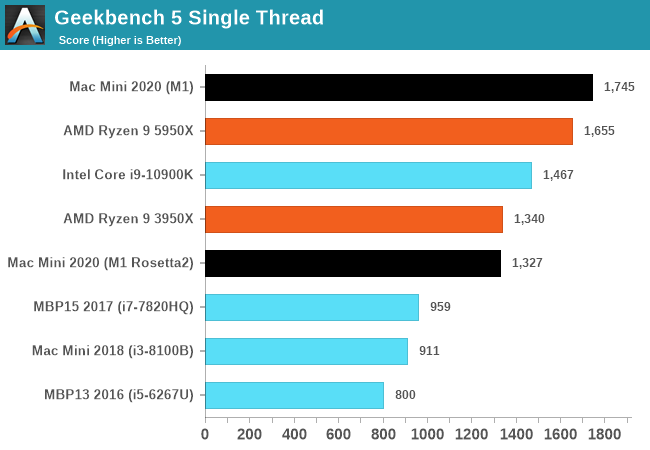
In Geekbench 5, the M1 does again extremely well as it actually takes the lead in our performance figures. Even when running in x86 compatibility mode, the M1 is able to match the top single-threaded performance of last generation’s high-end CPUs, and vastly exceed that of past iterations of the Mac mini and past Macbooks.
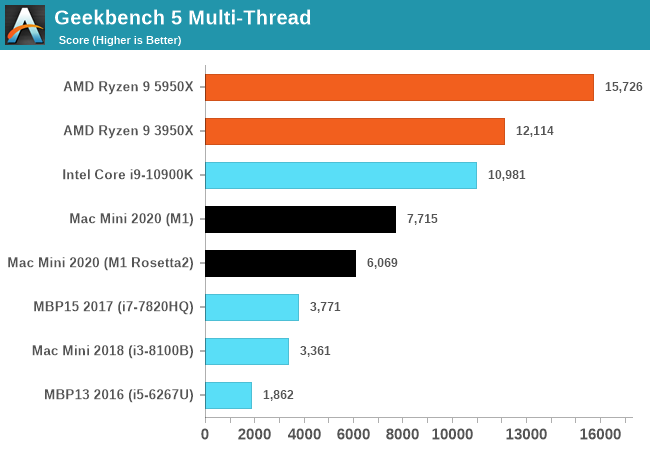
Multi-threaded performance is a matter of core-count and power efficiency of a design. The M1 here demolishes a 2017 15-inch Macbook Pro with an Intel i7-7820HQ with 4 cores and 8 threads, posting over double the score. We’ll be adding more data-points as we collect them.
Section by Ryan Smith
M1 GPU Performance: Integrated King, Discrete Rival
While the bulk of the focus from the switch to Apple’s chips is on the CPU cores, and for good reason – changing the underlying CPU architecture if your computers is no trivial matter – the GPU aspects of the M1 are not to be ignored. Like their CPU cores, Apple has been developing their own GPU technology for a number of years now, and with the shift to Apple Silicon, those GPU designs are coming to the Mac for the very first time. And from a performance standpoint, it’s arguably an even bigger deal than Apple’s CPU.
Apple, of course, has long held a reputation for demanding better GPU performance than the average PC OEM. Whereas many of Intel’s partners were happy to ship systems with Intel UHD graphics and other baseline solutions even in some of their 15-inch laptops, Apple opted to ship a discrete GPU in their 15-inch MacBook Pro. And when they couldn’t fit a dGPU in the 13-inch model, they instead used Intel’s premium Iris GPU configurations with larger GPUs and an on-chip eDRAM cache, becoming one of the only regular customers for those more powerful chips.
So it’s been clear for some time now that Apple has long-wanted better GPU performance than what Intel offers by default. By switching to their own silicon, Apple finally gets to put their money where their mouth is, so to speak, by building a laptop SoC with all the GPU performance they’ve ever wanted.
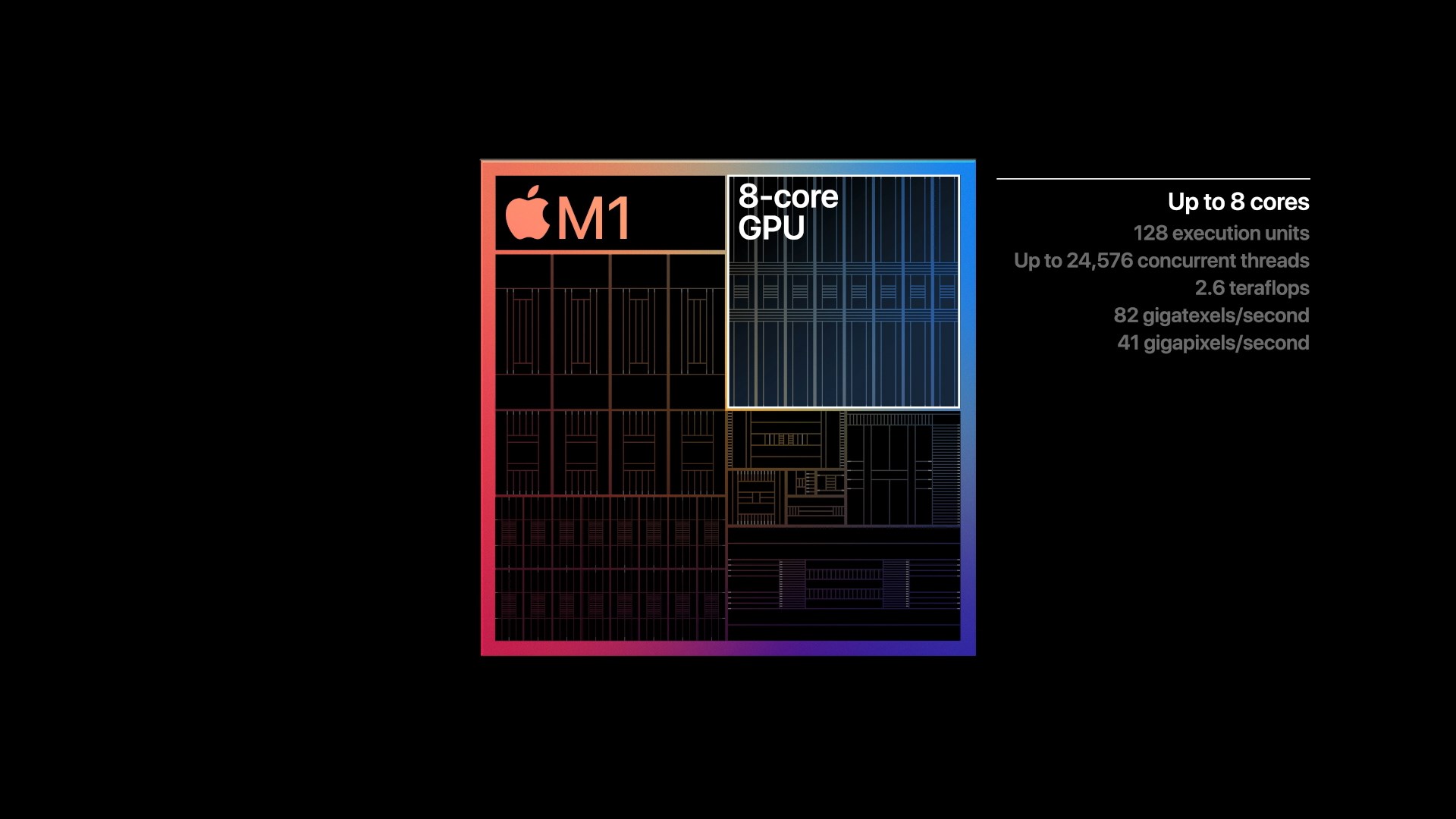
Meanwhile, unlike the CPU side of this transition to Apple Silicon, the higher-level nature of graphics programming means that Apple isn’t nearly as reliant on devs to immediately prepare universal applications to take advantage of Apple’s GPU. To be sure, native CPU code is still going to produce better results since a workload that’s purely GPU-limited is almost unheard of, but the fact that existing Metal (and even OpenGL) code can be run on top of Apple’s GPU today means that it immediately benefits all games and other GPU-bound workloads.
As for the M1 SoC’s GPU, unsurprisingly it looks a lot like the GPU from the A14. Apple will have needed to tweak their design a bit to account for Mac sensibilities (e.g. various GPU texture and surface formats), but by and large the difference is abstracted away at the API level. Overall, with M1 being A14-but-bigger, Apple has scaled up their 4 core GPU design from that SoC to 8 cores for the M1. Unfortunately we have even less insight into GPU clockspeeds than we do CPU clockspeeds, so it’s not clear if Apple has increased those at all; but I would be a bit surprised if the GPU clocks haven’t at least gone up a small amount. Overall, A14’s 4 core GPU design was already quite potent by smartphone standards, so an 8 core design is even more so. M1’s integrated GPU isn’t just designed to outpace AMD and Intel’s integrated GPUs, but it’s designed to chase after discrete GPUs as well.
| A Educated Guess At Apple GPU Specifications | |||
| M1 | |||
| ALUs | 1024 (128 EUs/8 Cores) |
||
| Texture Units | 64 | ||
| ROPs | 32 | ||
| Peak Clock | 1278MHz | ||
| Throughput (FP32) | 2.6 TFLOPS | ||
| Memory Clock | LPDDR4X-4266 | ||
| Memory Bus Width | 128-bit (IMC) |
||
Finally, it should be noted that Apple is shipping two different GPU configurations for the M1. The Mac Mini and MacBook Pro get chips with all 8 GPU cores enabled. Meanwhile for the Macbook Air, it depends on the SKU: the entry-level model gets a 7-core configuration, while the higher-tier model gets 8 cores. This means the entry-level Air gets the weakest GPU on paper – trailing a full M1 by around 12% – but it will be interesting to see how the shut-off core influences thermal throttling on that passively-cooled laptop.
Kicking off our look at GPU performance, let’s start with GFXBench 5.0. This is one of our regular benchmarks for laptop reviews as well, so it gives us a good opportunity to compare the M1-based Mac Mini to a variety of other CPU/GPU combinations inside and outside the Mac ecosystem. Overall this isn’t an entirely fair test since the Mac Mini is a small desktop rather than a laptop, but as M1 is a laptop-focused chip, this at least gives us an idea of how M1 performs when it gets to put its best foot forward.
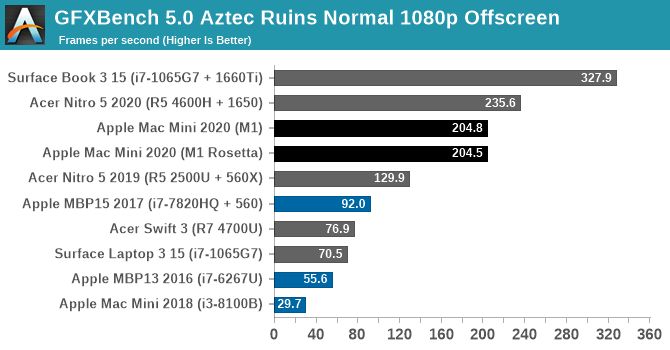
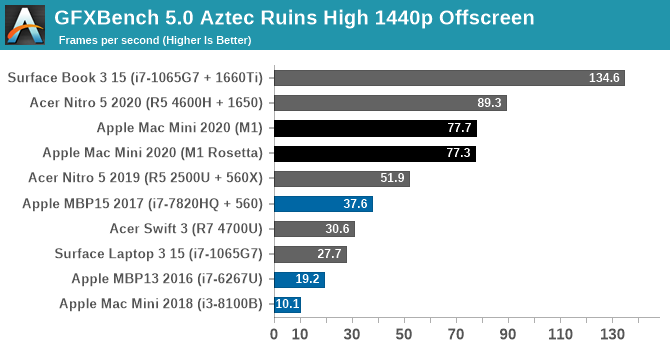
Overall, the M1’s GPU starts off very strong here. At both Normal and High settings it’s well ahead of any other integrated GPU, and even a discrete Radeon RX 560X. Only once we get to NVIDIA’s GTX 1650 and better does the M1 finally run out of gas.
The difference compared to the 2018 Intel Mac Mini is especially night-and-day. The Intel UHD graphics (Gen 9.5) GPU in that system is vastly outclassed to the point of near-absurdity, delivering a performance gain over 6x. And even other configurations such as the 13-inch MBP with Iris graphics, or a PC with a Ryzen 4700U (Vega 7 graphics) are all handily surpassed. In short, the M1 in the new Mac Mini is delivering discrete GPU-levels of performance.
As an aside, I also took the liberty of running the x86 version of the benchmark through Rosetta, in order to take a look at the performance penalty. In GFXBench Aztec Ruins, at least, there is none. GPU performance is all but identical with both the native binary and with binary translation.
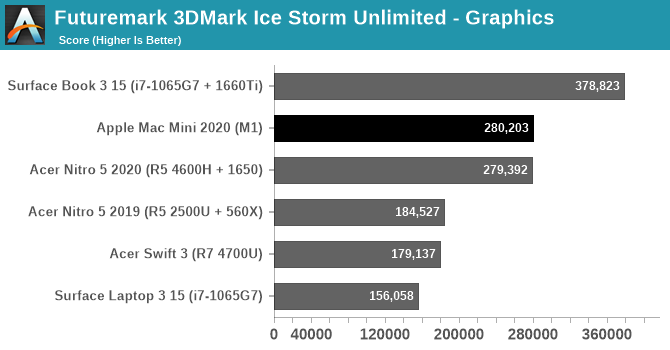
Taking one last quick look at the wider field with an utterly silly synthetic benchmark, we have 3DMark Ice Storm Unlimited. Thanks to the ability for Apple Silicon Macs to run iPhone/iPad applications, we’re able to run this benchmark on a Mac for the first time by running the iOS version. This is a very old benchmark, built for the OpenGL ES 2.0 era, but it’s interesting that it fares even better than GFXBench. The Mac Mini performs just well enough to slide past a GTX 1650 equipped laptop here, and while this won’t be a regular occurrence, it goes to show just how potent M1 can be.


Another GPU benchmark that’s been updated for the launch of Apple’s new Macs is BaseMark GPU. This isn’t a regular benchmark for us, so we don’t have scores for other, non-Mac laptops on hand, but it gives us another look at how M1 compares to other Mac GPU offerings. The 2020 Mac Mini still leaves the 2018 Intel-based Mac Mini in the dust, and for that matter it’s at least 50% faster than the 2017 MacBook Pro with a Radeon Pro 560 as well. Newer MacBook Pros will do better, of course, but keep in mind that this is an integrated GPU with the entire chip drawing less power than just a MacBook Pro’s CPU, never mind the discrete GPU.
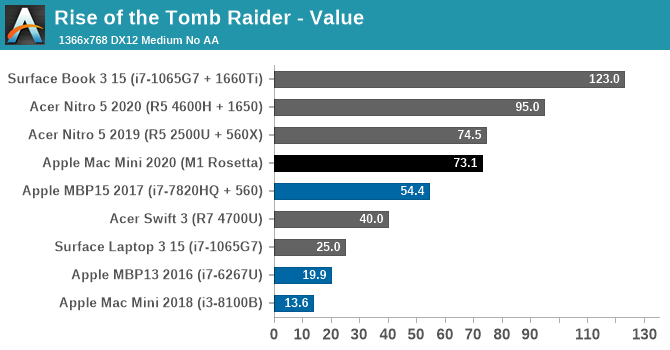
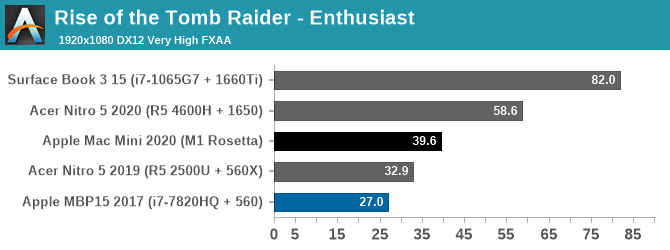
Finally, putting theory to practice, we have Rise of the Tomb Raider. Released in 2016, this game has a proper Mac port and a built-in benchmark, allowing us to look at the M1 in a gaming scenario and compare it to some other Windows laptops. This game is admittedly slightly older, but its performance requirements are a good match for the kind of performance the M1 is designed to offer. Finally, it should be noted that this is an x86 game – it hasn’t been ported over to Arm – so the CPU side of the game is running through Rosetta.
At our 768p Value settings, the Mac Mini is delivering well over 60fps here. Once again it’s vastly ahead of the 2018 Intel-based Mac Mini, as well as every other integrated GPU in this stack. Even the 15-inch MBP and its Radeon Pro 560 are still trailing the Mac Mini by over 25%, and it takes a Ryzen laptop with a Radeon 560X to finally pull even with the Mac Mini.
Meanwhile cranking things up to 1080p with Enthusiast settings finds that the M1-based Mac Mini is still delivering just shy of 40fps, and it’s now over 20% ahead of the aforementioned Ryzen + 560X system. This does leave the Mini well behind the GTX 1650 here – with Rosetta and general API inefficiencies likely playing a part – but it goes to show what it takes to beat Apple’s integrated GPU. At 39.6fps, the Mac Mini is quite playable at 1080p with good image quality settings, and it would be fairly easy to knock down either the resolution or image quality a bit to get that back above 60fps. All on an integrated GPU.
Update 11-17, 7pm: Since the publication of this article, we've been able to get access to the necessary tools to measure the power consumption of Apple's SoC at the package and core level. So I've gone back and captured power data for GFXBench Aztec Ruins at High, and Rise of the Tomb Raider at Enthusiast settings.
| Power Consumption - Mac Mini 2020 (M1) | ||||
| Rise of the Tomb Raider (Enthusiast) | GFXBench Aztec (High) |
|||
| Package Power | 16.5 Watts | 11.5 Watts | ||
| GPU Power | 7 Watts | 10 Watts | ||
| CPU Power | 7.5 Watts | 0.16 Watts | ||
| DRAM Power | 1.5 Watts | 0.75 Watts | ||
The two workloads are significantly different in what they're doing under the hood. Aztec is a synthetic test that's run offscreen in order to be as pure of a GPU test as possible. As a result it records the highest GPU power consumption – 10 Watts – but it also barely scratches the CPU cores virtually untouched (and for that matter other elements like the display controlller). Meanwhile Rise of the Tomb Raider is a workload from an actual game, and we can see that it's giving the entire SoC a workout. GPU power consumption hovers around 7 Watts, and while CPU power consumption is much more variable, it too tops out just a bit higher.
But regardless of the benchmark used, the end result is the same: the M1 SoC is delivering all of this performance at ultrabook-levels of power consumption. Delivering low-end discrete GPU performance in 10 Watts (or less) is a significant part of why M1 is so potent: it means Apple is able to give their small devices far more GPU horsepower than they (or PC OEMs) otherwise could.
Ultimately, these benchmarks are very solid proof that the M1’s integrated GPU is going to live up to Apple’s reputation for high-performing GPUs. The first Apple-built GPU for a Mac is significantly faster than any integrated GPU we’ve been able to get our hands on, and will no doubt set a new high bar for GPU performance in a laptop. Based on Apple’s own die shots, it’s clear that they spent a sizable portion of the M1’s die on the GPU and associated hardware, and the payoff is a GPU that can rival even low-end discrete GPUs. Given that the M1 is merely the baseline of things to come – Apple will need even more powerful GPUs for high-end laptops and their remaining desktops – it’s going to be very interesting to see what Apple and its developer ecosystem can do when the baseline GPU performance for even the cheapest Mac is this high.
SPEC2006 & 2017: Industry Standard - ST Performance
Single-threaded performance of the new M1 is certainly one of its key aspects, where the new Firestorm cores definitely punch far above their power class. We had hinted in our preview A14 analysis article that the M1 may well be ending up as not only the top-performing low-power mobile CPU out there, but actually end up as the top-performing absolute performance amongst all CPUs in the market. The A14 fell short of that designation, but the M1 is an even faster implementation of the new Firestorm cores.
It’s to be noted that we’re comparing the M1 to the absolute best desktop and laptop platforms on the market right now, solely looking at absolute best single-threaded performance.
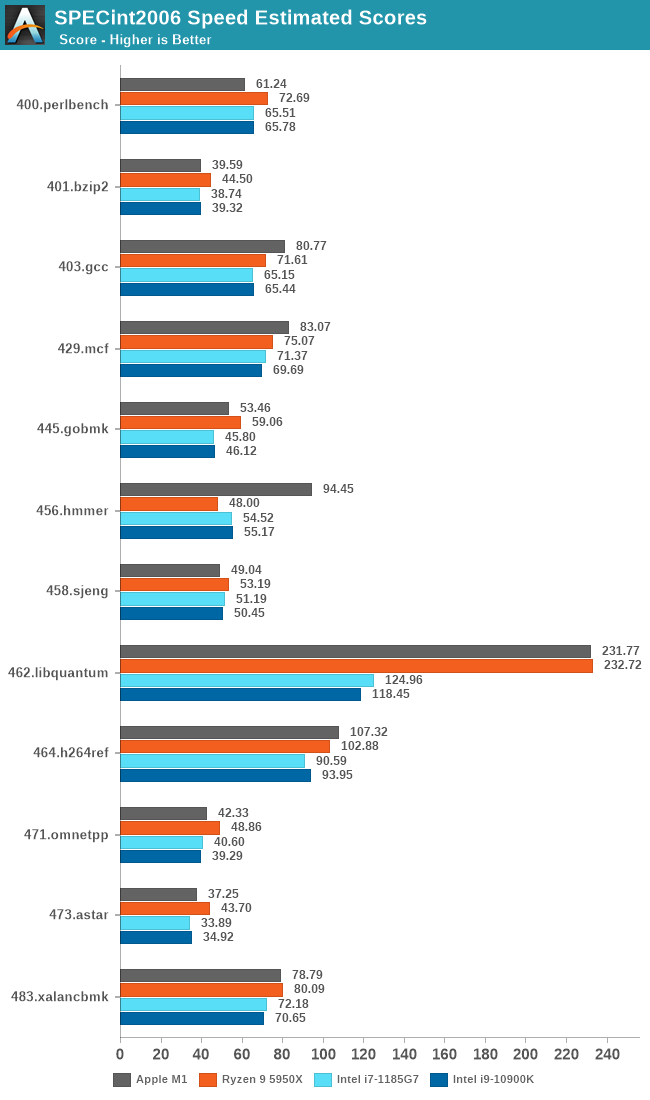
In SPECint2006, we’re now seeing the M1 close the gap to AMD’s Zen3, beating it in several workloads now, which increasing the gap to Intel’s new Tiger Lake design as well as their top-performing desktop CPU, which the M1 now beats in the majority of workloads.
Since our A14 results, we’ve been able to track down Apple’s compiler setting which increases the 456.hmmer by such a dramatic amount – Apple defaults the “-mllvm -enable-loop-distribute=true” in their newest compiler toolchain whilst it needs to be enabled on third-party LLVM compilers. A 5950X with the flag enabled increases its score to 91.64, but also while seeing some regressions in other tests. We haven’t had time to re-test further platforms.
The M1’s performance boost in 462.libquantum is due to the increased L2 cache, as well as the doubled memory bandwidth of the system, something that this workload is very hungry of.
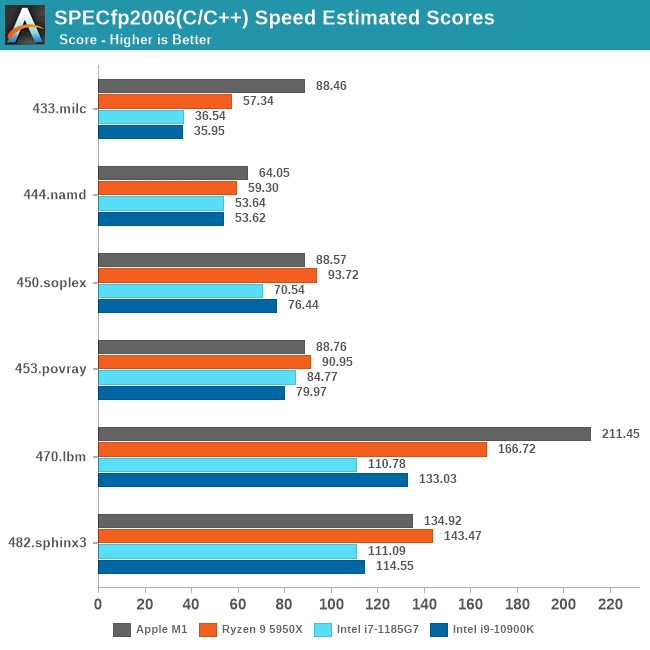
In the fp2006 workloads, we’re seeing the M1 post very large performance boosts relative to the A14, meaning that it now is able to claim the best performance out of all CPUs being compared here.
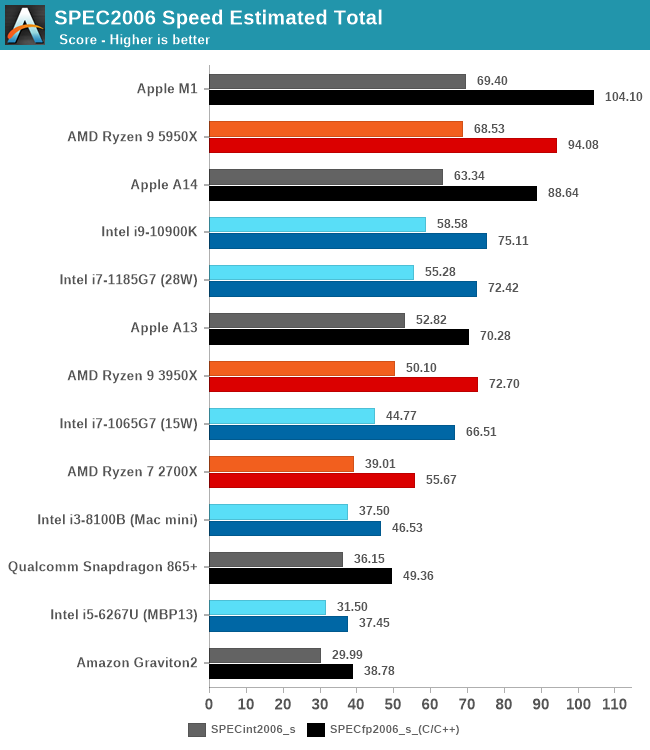
In the overall score, the M1 increases the scores by 9.5% and 17% over the A14. In the integer score, the M1 takes the lead here, although if we were to account for the 456.hmmer discrepancy it would still favour the Zen3-based 5950X. In the floating-point score however, the Apple M1 now takes a large lead ahead, making it the best performing CPU core.
We’ve had a lot arguments about whether 2006 is relevant or not in today’s landscape. We have practical reasons for not yet running SPEC2017 on mobile devices, but given that the new Apple Silicon M1 runs on macOS, these concerns are not valid, thus enabling us to also run the more modern benchmark suite.
It’s to be noted that currently we do not have a functional Fortran compiler on Apple Silicon macOS systems, thus we have to skip several workloads in the 2017 suite, which is why they’re missing from the graphs. We’re concentrating on the remaining C/C++ workloads.
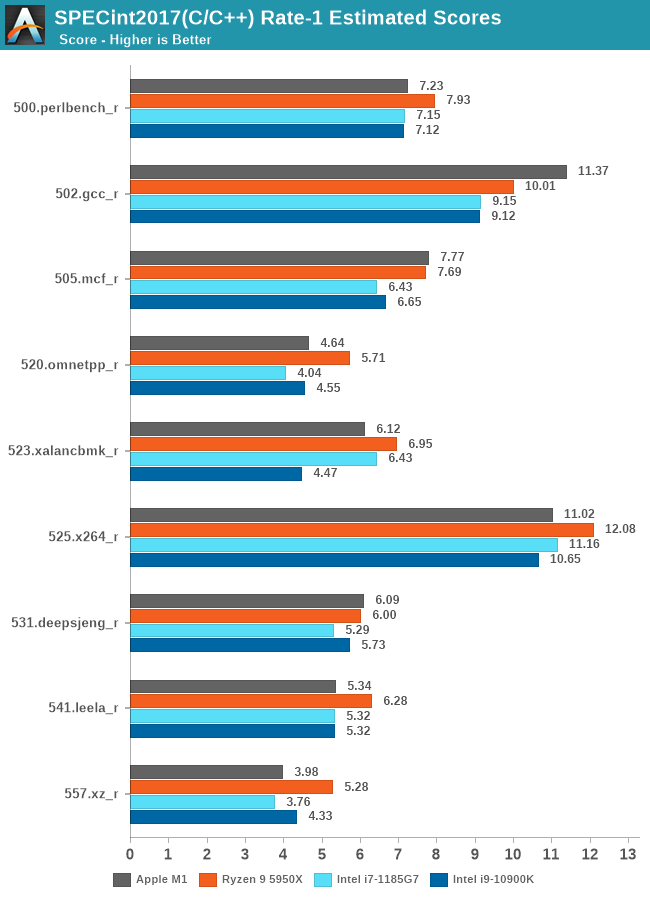
The situation doesn’t change too much with the newer SPECint2017 suite. Apple’s Firestorm core here remains extremely impressive, at worst matching up Intel’s new Tiger Lake CPU in single-threaded performance, and at best, keeping up and sometimes beating AMD’s new Zen3 CPU in the new Ryzen 5000 chips.
Apple’s performance is extremely balanced across the board, but what stands out is the excellent 502.gcc_r performance where it takes a considerable leap ahead of the competition, meaning that the new Apple core does extremely well on very complex code and code compiling.
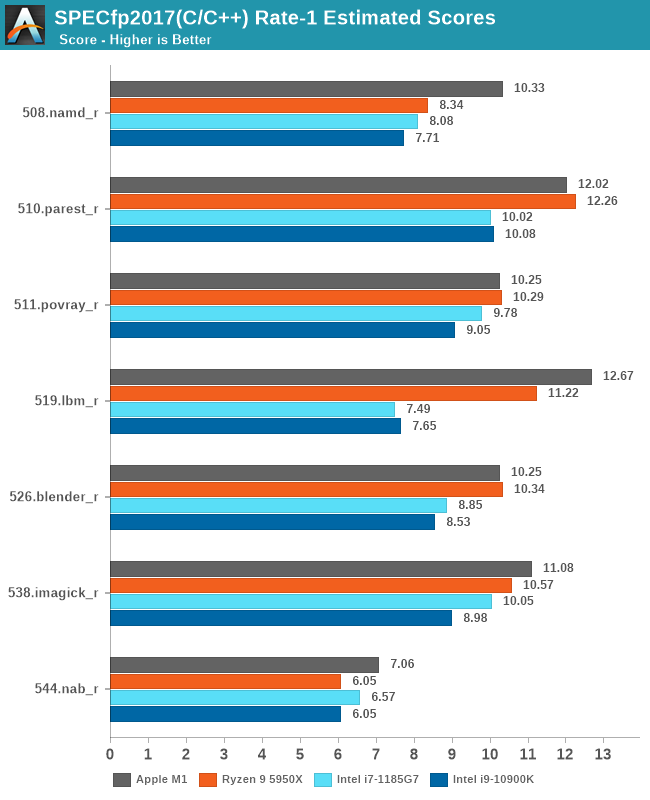
In SPECfp2017, we’re seeing something quite drastic in terms of the scores. The M1 here at worst is a hair-width’s behind AMD’s Zen3, and at best is posting the best absolute performance of any CPU in the market. These are incredible scores.
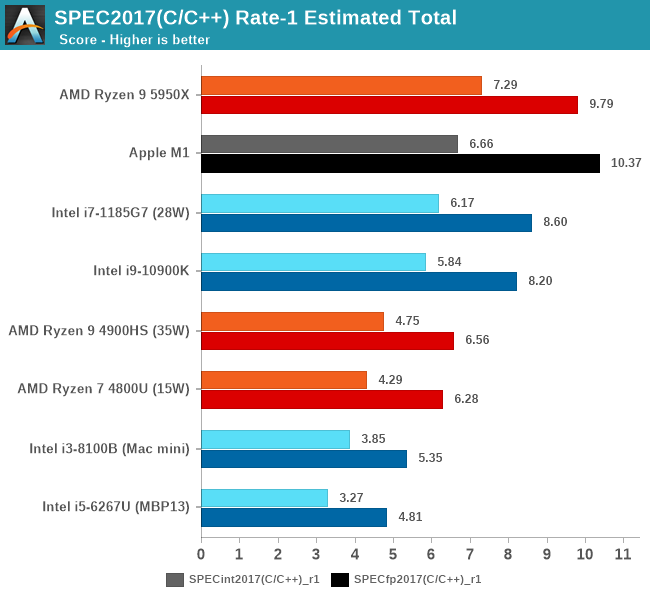
In the overall new SPEC2017 int and fp charts, the Apple Silicon M1 falls behind AMD’s Zen3 in the integer performance, however takes an undisputable lead in the floating-point suite.
Compared to the Intel contemporary designs, the Apple M1 is able to showcase a performance leap ahead of the best the company has to offer, with again a considerable strength in the FP score.
While AMD’s Zen3 still holds the leads in several workloads, we need to remind ourselves that this comes at a great cost in power consumption in the +49W range while the Apple M1 here is using 7-8W total device active power.
SPEC2017 - Multi-Core Performance
While we knew that the Apple M1 would do extremely well in single-threaded performance, the design’s strengths are also in its power-efficiency which should directly translate to exceptionally good multi-threaded performance in power limited designs. We noted that although Apple doesn’t really publish any TDP figure, we estimate that the M1 here in the Mac mini behaves like a 20-24W TDP chip.
We’re including Intel’s newest Tiger Lake system with an i7-1185G7 at 28W, an AMD Ryzen 7 4800U at 15W, and a Ryzen 9 4900HS at 35W as comparison points. It’s to be noted that the actual power consumption of these devices should exceed that of their advertised TDPs, as it doesn’t account for DRAM or VRMs.
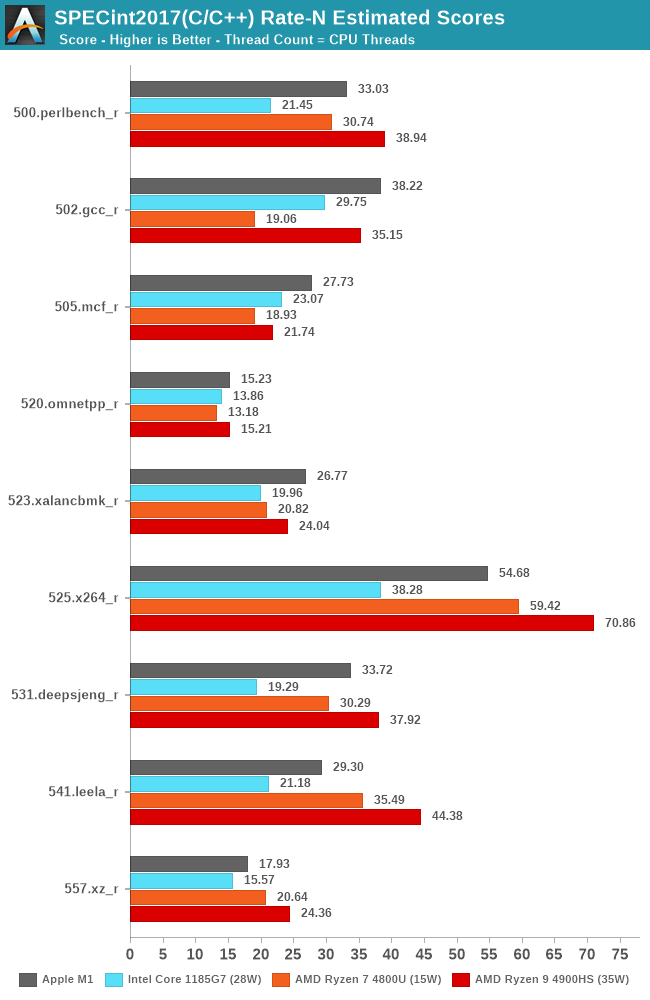
In SPECint2017 rate, the Apple M1 battles with AMD’s chipsets, with the results differing depending on the workload, sometimes winning, sometimes losing.
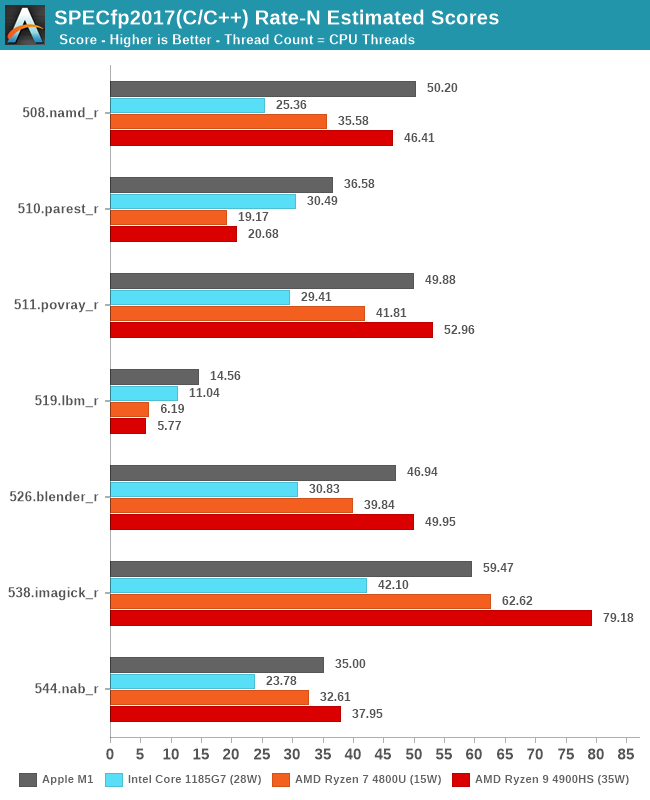
In the fp2017 rate results, we see similar results, with the Apple M1 battling it out with AMD’s higher-end laptop chip, able to beat the lower TDP part and clearly stay ahead of Intel’s design.
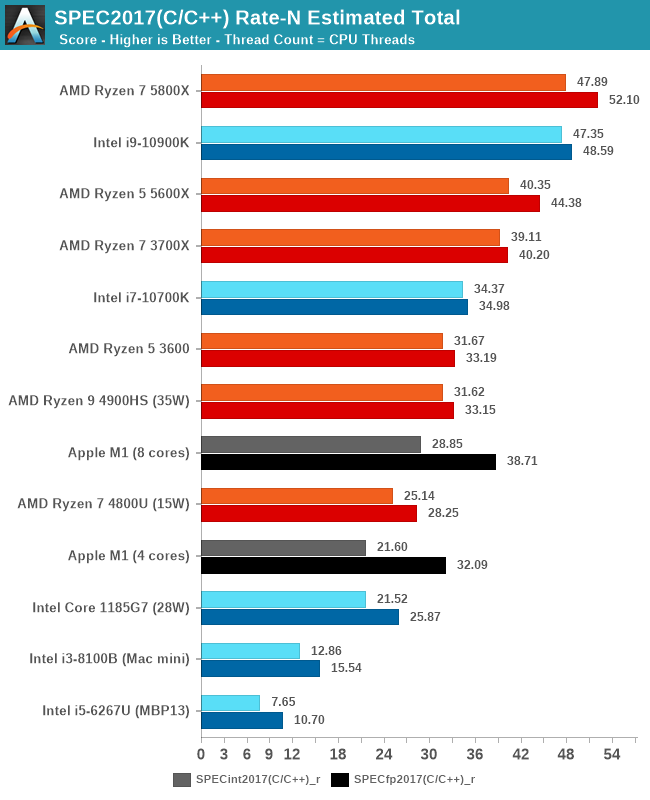
In the overall multi-core scores, the Apple M1 is extremely impressive. On integer workloads, it still seems that AMD’s more recent Renoir-based designs beat the M1 in performance, but only in the integer workloads and at a notably higher TDP and power consumption.
Apple’s lead against Intel’s Tiger Lake SoC at 28W here is indisputable, and shows the reason as to why Apple chose to abandon their long-term silicon partner of 15 years. The M1 not only beats the best Intel has to offer in this market-segment, but does so at less power.
I also included multi-threaded scores of the M1 when ignoring the 4 efficiency cores of the system. Here although it’s an “8-core” design, the heterogeneous nature of the CPUs means that performance is lop-sided towards the big cores. That doesn’t mean that the efficiency cores are absolutely weak: Using them still increases total throughput by 20-33%, depending on the workload, favouring compute-heavy tasks.
Overall, Apple doesn’t just deliver a viable silicon alternative to AMD and Intel, but actually something that’s well outperforms them both in absolute performance as well as power efficiency. Naturally, in higher power-level, higher-core count systems, the M1 can’t keep up to AMD and Intel designs, but that’s something Apple likely will want to address with subsequent designs in that category over the next 2 years.
Rosetta2: x86-64 Translation Performance
The new Apple Silicon Macs being based on a new ISA means that the hardware isn’t capable of running existing x86-based software that has been developed over the past 15 years. At least, not without help.
Apple’s new Rosetta2 is a new ahead-of-time binary translation system which is able to translate old x86-64 software to AArch64, and then run that code on the new Apple Silicon CPUs.
So, what do you have to do to run Rosetta2 and x86 apps? The answer is pretty much nothing. As long as a given application has a x86-64 code-path with at most SSE4.2 instructions, Rosetta2 and the new macOS Big Sur will take care of everything in the background, without you noticing any difference to a native application beyond its performance.
Actually, Apple’s transparent handling of things are maybe a little too transparent, as currently there’s no way to even tell if an application on the App Store actually supports the new Apple Silicon or not. Hopefully this is something that we’ll see improved in future updates, serving also as an incentive for developers to port their applications to native code. Of course, it’s now possible for developers to target both x86-64 and AArch64 applications via “universal binaries”, essentially just glued together variants of the respective architecture binaries.
We didn’t have time to investigate what software runs well and what doesn’t, I’m sure other publications out there will do a much better job and variety of workloads out there, but I did want to post some more concrete numbers as to how the performance scales across different time of workloads by running SPEC both in native, and in x86-64 binary form through Rosetta2:
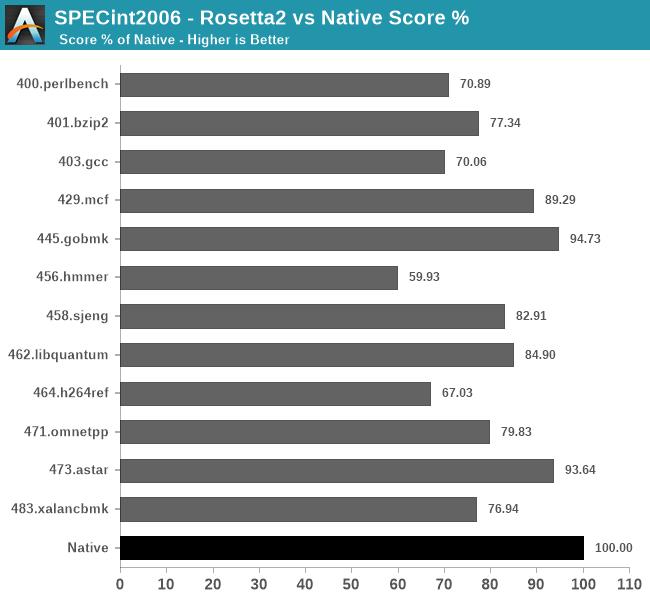
In SPECint2006, there’s a wide range of performance scaling depending on the workloads, some doing quite well, while other not so much.
The workloads that do best with Rosetta2 primarily look to be those which have a more important memory footprint and interact more with memory, scaling perf even above 90% compared to the native AArch64 binaries.
The workloads that do the worst are execution and compute heavy workloads, with the absolute worst scaling in the L1 resident 456.hmmer test, followed by 464.h264ref.
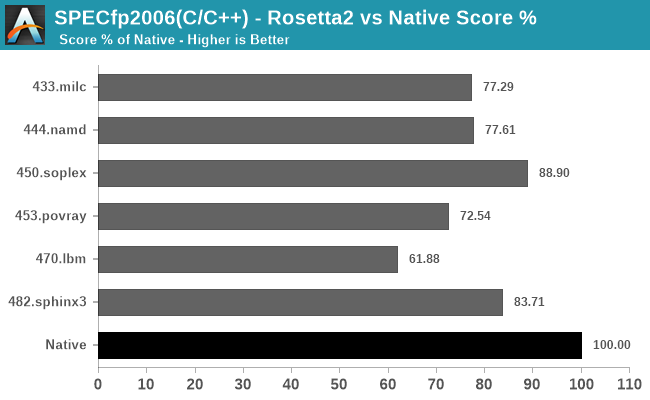
In the fp2006 workloads, things are doing relatively well except for 470.lbm which has a tight instruction loop.
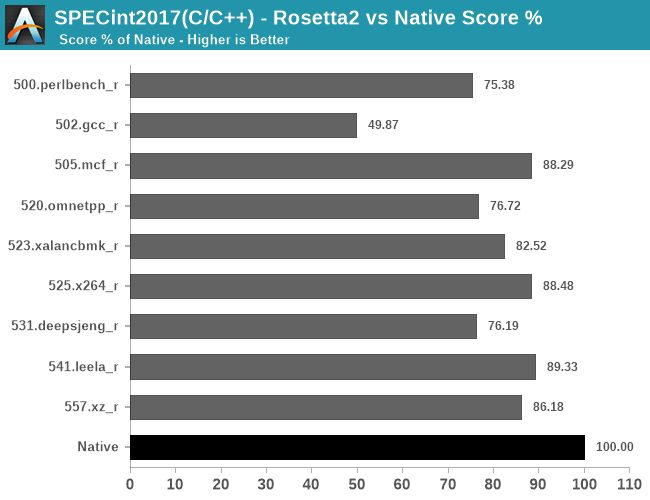
In the int2017 tests, what stands out is the horrible performance of 502.gcc_r which only showcases 49.87% performance of the native workload – probably due to high code complexity and just overall uncommon code patterns.
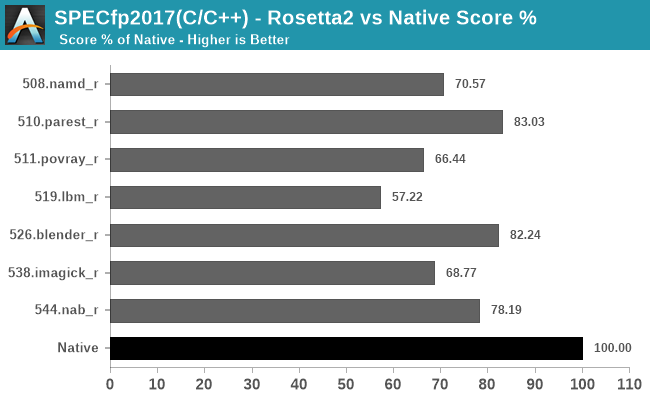
Finally, in fp2017, it looks like we’re again averaging in the 70-80% performance scale, depending on the workload’s code.
Generally, all of these results should be considered outstanding just given the feat that Apple is achieving here in terms of code translation technology. This is not a lacklustre emulator, but a full-fledged compatibility layer that when combined with the outstanding performance of the Apple M1, allows for very real and usable performance of the existing software application repertoire in Apple’s existing macOS ecosystem.
Conclusion & First Impressions
Today’s piece was less of a review on the new Mac mini as it was testing out Apple’s new M1 chip. We’ve had very little time with the device but hopefully were able to manage to showcase the key aspects of the new chip, and boy, it’s impressive.
For years now we’ve seen Apple’s custom CPU microarchitecture in A-series phone SoCs post impressive and repeated performance jumps generation after generation, and it today’s new Apple Silicon devices are essentially the culmination of the inevitable trajectory that Apple has been on.
In terms of power, the Apple M1 inside of the new Mac mini fills up a thermal budget up to around 20-24W from the SoC side. This is still clearly a low-power design, and Apple takes advantage of that to implement it into machines such as the now fan-less Macbook Air. We haven’t had opportunity to test that device yet, but we expect the same peak performance, although with more heavy throttling once the SoC saturates the heat dissipation of that design.
In the new Macbook Pro, we expect the M1 to showcase similar, if not identical performance to what we’ve seen on the new Mac mini. Frankly, I suspect Apple could have down-sized the Mini, although we don’t exactly now the internal layout of the piece as we weren’t allowed to disassemble it.

The performance of the new M1 in this “maximum performance” design with a small fan is outstandingly good. The M1 undisputedly outperforms the core performance of everything Intel has to offer, and battles it with AMD’s new Zen3, winning some, losing some. And in the mobile space in particular, there doesn’t seem to be an equivalent in either ST or MT performance – at least within the same power budgets.
What’s really important for the general public and Apple’s success is the fact that the performance of the M1 doesn’t feel any different than if you were using a very high-end Intel or AMD CPU. Apple achieving this in-house with their own design is a paradigm shift, and in the future will allow them to achieve a certain level of software-hardware vertical integration that just hasn’t been seen before and isn’t achieved yet by anybody else.
The software side of things already look good on day 1 due to Apple’s Rosetta2. Whilst the software doesn’t offer the best the hardware can offer, with time, as developers migrate their applications to native Apple Silicon support, the ecosystem will flourish. And in the meantime, the M1 is fast enough that it can absorb the performance hit from Rosetta2 and still deliver solid performance for all but the most CPU-critical x86 applications.
For developers, the Apple Silicon Macs also represent the very first full-fledged Arm machines on the market that have few-to-no compromises. This is a massive boost not just for Apple, but for the larger Arm ecosystem and the growing Arm cloud-computing business.
Overall, Apple hit it out of the park with the M1.






