Original Link: https://www.anandtech.com/show/14466/intel-xeon-cascade-lake-vs-nvidia-turing
Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM EST
It seems like the new motto for Silicon Valley for the last few years has been “Data is the new oil,” and for good reason. The number of companies employing machine learning-based AI technologies has exploded, and even a few years after all of this has kicked off in earnest, those numbers continue to grow. This form of AI is no longer just an academic thesis or curious research project, but instead machine learning has become an important part of the enterprise market, and the impact on enterprise hardware – both purchasing and development – would be difficult to overstate. This is the era of AI.
At first sight, the hardware choices for these kinds of applications seem simple: Intel Xeon CPUs for storing and preprocessing data, NVIDIA GPUs for (almost) everything AI. And indeed, this has largely been case for the last few years now. However, NVIDIA’s competitors have not been standing idly by the entire time – and that especially goes for Intel, whose enterprise market share all of this ultimately threatens. With everything from dedicated low-power inference processors to purpose-optimized Xeons, Intel is taking aim at every level of the AI market. The net result is that between all of these competitors, we’re seeing AI tackled from many different directions, and the hardware battle for AI era is insanely interesting in our humble opinion.
Today we’re taking a look at what’s perhaps the heart of Intel’s hardware in the AI space, Intel’s second-generation Xeon Scalable processors, better known as "Cascade Lake". Introduced a bit earlier this year, these new processors are still based on the same core Skylake architecture as the first-generation products, but incorporate a number of new instructions to speed up AI performance.
And as far as new technology goes, this is certainly the most interesting aspect of Cascade Lake. While we could talk about the three to six percent general CPU performance improvement, the 56 cores of Intel’s most expensive processor ever, and the "world record benchmarks," these small improvements are close to irrelevant for the near and mid-term future of the IT world. Just look at the very first slide of the Intel press & analyst briefing.

Internet of things, data engineering, and AI. That is where a large part of the growth, the innovation, and the future of IT will be. And this is where Intel wants to be.
Right now, NVIDIA has a virtual monopoly on the “sexiest” part of this market, which is deep learning and “massively parallel HPC” software. Thanks to a confluence of factors on the hardware and software sides, most of this software is run on NVIDIA GPUs and clusters. So to the general public, it looks likes NVIDIA owns the “AI market”, a picture that is not inaccurate, but also not complete. There’s a lot more to the AI market than just neural network inferencing, and in particular, everything that has to happen to feed the AI model with data gets very little attention. As a result, it’s neural networks and Terminator robots that get all the headlines, even though they’re just part of the of the picture. In reality, the processing web for AI applications is much more like the picture below.
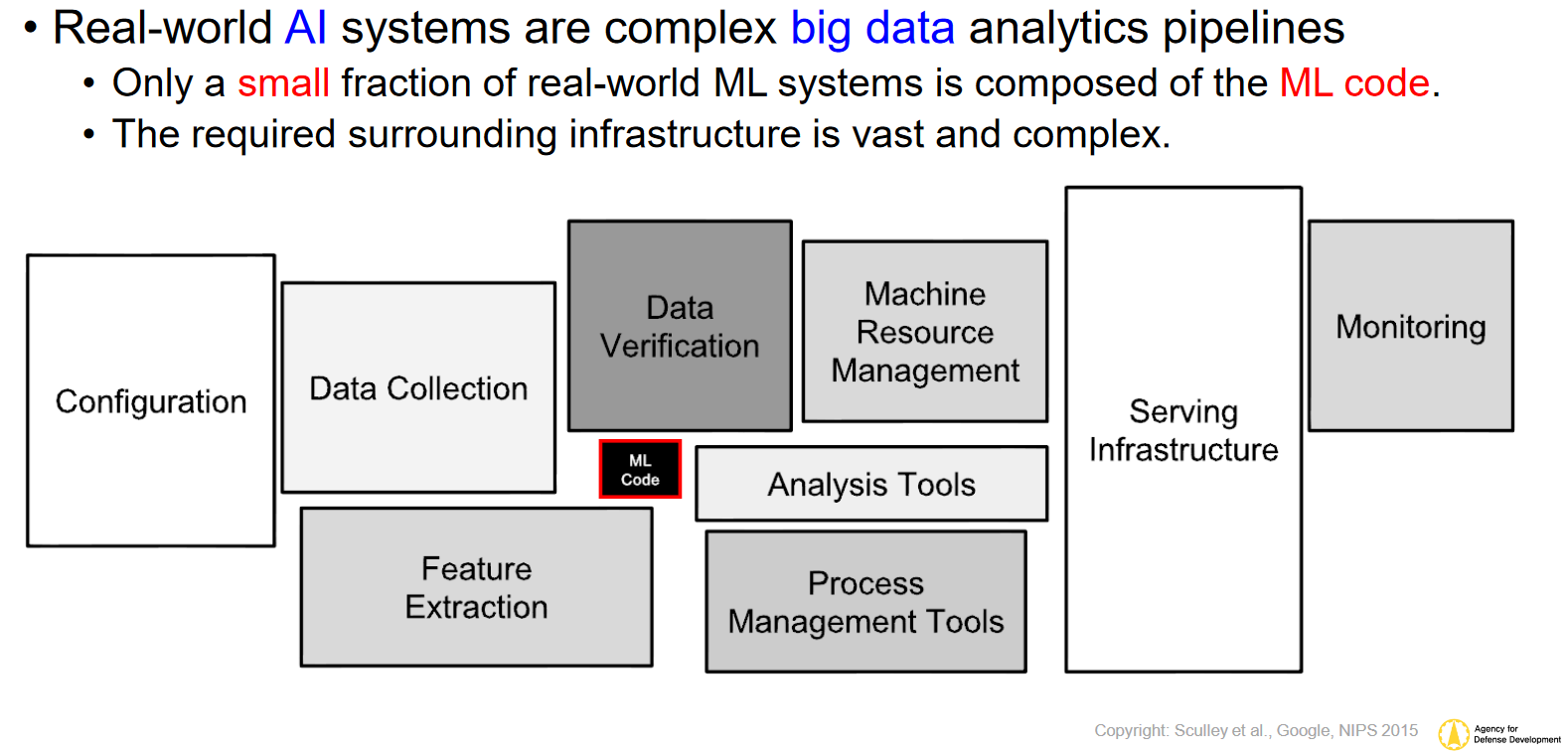
In short, actual machine learning code execution is only a very small part of the software tools necessary to build and AI Application.
Before you can even start, you have to ingest data, decompress, filter, reorder, map, and shuffle it around. Once everything is sorted and shuffled, you have to aggregate the data. As ML algorithms need large amounts of data to produce good predictions, that can be very processing memory intensive. Why? Let us delve a little deeper.
AI Is More Than Deep Learning
At a high level, while deep learning is a form of artificial intelligence, the converse isn't always true; an application implementing AI does not necessarily use deep learning. Many AI applications use “conventional statistical” or “traditional” machine learning. After all, Support Vector Machines, Logistic Regression, K-nearest, Naive Bayes, and decision trees still make a lot of sense to use in automating information classification, especially if you don’t have a lot of data.
For example, Conditional Random Field (CRF) is used in natural language processing, and a lot of recommendation engines are based upon Boltzman Machines, Alternate Least Square (ALS), and so on. Case in point: one of most demanding and unique benchmarks – our "big data" benchmark – uses an ALS algorithm as recommendation engine ("collaborative filtering").
Of course, the use of neural networks – itself a whole field of study – is booming, and their use tends to dominate the latest AI applications. Neural networks are also among the most demanding workloads, requiring lots of processing power and signing expensive (and well-published) hardware contracts. All of which contrasts heavily with logistic regression, which remains the most used machine learning method, and also happens to need much less processing.
The reason for these difference in processing power requirements is, in turn, actually pretty simple. To quote Wouter Gevaert, an AI expert at the university department I work in:
“Each Neuron in a Neural Network can be considered like a logistic regression unit. Therefore, a Neural Network is like a massive amount of logistic regressions” (When you use sigmoid as activation function)
With all of that said, however, while neural networks are the most processing-intensive of AI technologies (especially with a large number of layers), there are several traditional machine learning techniques that also require a lot of processing power. Support Vector Machines with their complex transformations also tend to require a lot of computational time, for example. And in our Spark test, the Stanford NER system is based on a supervised CRF model using a labeled collection of English data. In that test, it has to crunch through a massive amount of unstructured text – several hundreds of gigabytes.
And of course, most of the analytical queries are still written in good old SQL. For structured and semi-structured data, for OLAP cubes etc., SQL code is still prevalent. As a single SQL query is nowhere near as parallel as Neural Networks – in many cases they are 100% sequential – the CPU is best tool for the job.
So in practice, most data (pre) processing and lots of AI software is still running on a CPU. GPUs mostly run massively parallel HPC applications and neural networks, an important market to be sure, but still only a piece of the larger AI market. This is one of the reasons why NVIDIA closed on $3 Billion of datacenter revenue last year, while Intel’s datacenter group made $20 Billion. Yes, Intel’s number includes Networking and storage. Yes, that includes several other markets than HPC and Data analytics. But still, a significant part of that revenue is going to be based upon servers that store and process data for analytics.

Compounding this whole picture, however, is not just revenue, but opportunities for growth. NVIDIA has been seeing massive growth in the datacenter market, while Intel has only seen single digit growth. Customer needs are continuing to shift as new technologies become available; the battle for the data analytics market has begun, and it is intensifying.
Convolutional, Recurrent, & Scalability: Finding a Balance
Despite the fact that Intel's Xeon Phi was a market failure as an accelerator and has been discontinued, Intel has not given up on the concept. The company still wants a bigger piece of the AI market, including pieces that may otherwise be going to NVIDIA.
To quote Intel’s Naveen Rao:
Customers are discovering that there is no single “best” piece of hardware to run the wide variety of AI applications, because there’s no single type of AI.
And Naveen makes a salient point. Because although NVIDIA has never claimed that they provide the best hardware for all types of AI, superficially looking at the most cited benchmarks in press releases across the industry (ResNet, Inception, etc) you would almost believe there was only one type of AI that matters. Convolutional Neural Networks (CNNs or ConvNets) dominate the benchmarks and product presentations, as they are the most popular technology for analyzing images and video. Anything that can be expressed as “2D input” is a potential candidate for the input layers of these popular neural networks.
Some of the most spectacular breakthroughs in recent years have been made with the CNNs. It’s no mistake that ResNet performance has become so popular, for example. The associated ImageNet database, a collaboration between Stanford University and Princeton University, contains fourteen million images; and until the last decade, AI performance on recognizing those images was very poor. CNNs changed that in quick order, and it has been one of the most popular AI challenges ever since, as companies look to outdo each out in categorizing this database faster and more accurately than ever before.
To put all of this on a timeline, as early as 2012, AlexNet, a relatively simple neural network, achieved significantly better accuracy than the traditional machine learning techniques in an ImageNet classification competition. In that test, it achieved an 85% accuracy rate, which is almost half of the error rate of more traditional approaches, which achieved 73% accuracy.
In 2015, the famous Inception V3 achieved a 3,58% error rate in classifying the images, which is similar to (or even slightly better than) a human. The ImageNet challenge got harder, but CNNs got better even without increasing the number of layers, courtesy of residual learning. This led to the famous “ResNet” CNN, now one of the most popular AI benchmarks. To cut a long story short, CNNs are the rockstars of the AI Universe. They get by far most of the attention, testing, and research.
CNNs are also very scalable: adding more GPUs scales (almost) linearly in lowering a network’s training time. Put bluntly, CNNs are a gift from the heavens for NVIDIA. CNNs are the most common reason for why people invest in NVIDIAs expensive DGX servers ($400k) or buy multiple Tesla GPUs ($7k+).
Still, there is more to AI than CNNs. Recurrent Neural Networks for example are also popular for speech recognition, language translation, and time series.
This is why the MLperf benchmark initiative is so important. For the first time, we are getting a benchmark that is not dominated completely by CNNs.

Taking a quick look at MLperf, the Image and object classification benchmarks are CNNs of course, but RNNs (via Neural machine translation) and collaborative filtering are also represented. Meanwhile, even the recommendation engine test is based on a neural network; so technically speaking there is no "traditional" machine learning test included, which is unfortunate. But as this is version 0.5 and the organization is inviting more feedback, it sure is promising and once it matures, we expect it to be the best benchmark available.

Looking at some of the first data, however, via Dell’s benchmarks, it is crystal clear that not all neural networks are as scalable as CNNs. While the ResNet CNN easily quadruples when you move to four times the number of GPUs (and add a second CPU), the collaborative filtering method offers only 50% higher performance.
In fact, quite a bit of academic research revolves around optimizing and adapting CNNs so they handle these sequence modelling workloads just as well as RNNs, and as result can replace the less scalable RNNs.
Intel’s View on AI: Do What NV Doesn't
On the whole, Intel has a good point that there is "a wide range of AI applications", e.g. there is AI life beyond CNNs. In many real-life scenarios, traditional machine learning techniques outperform CNNs, and not all deep learning is done with the ultra-scalable CNNs. And in other real-world cases, having massive amounts of RAM is another big performance advantage, both while training the model and using it to infer new data.
So despite NVIDIA’s massive advantage in running CNNs, high end Xeons can offer a credible alternative in the data analytics market. To be sure, nobody expects the new Cascade Lake Xeons to outperform NVIDIA GPUs in CNN training, but there are lots of cases where Intel might be able to convince customers to invest in a more potent Xeon instead of an expensive Tesla accelerator:
- Inference of AI models that require a lot of memory
- "Light" AI models that do not require long training times.
- Data architectures where the batch or stream processing time is more important than the model training time.
- AI models that depend on traditional “non-neural network” statistical models
As result, there might be an opportunity for Intel to keep NVIDIA at bay until they have a reasonable alternative for NVIDIA’s GPUs in CNN workloads. Intel has been feverishly adding features to the Xeons Scalable family and optimizing its software stack to combat NVIDIA AI hegemony. Optimized AI software like Intel’s own distribution for Python, the Intel Math Kernel Library for Deep Learning, and even the Intel Data Analytics Acceleration Library – mostly for traditional machine learning...

All told then, for the second generation of Intel’s Xeon Scalable processors, the company has added new AI hardware features under the Deep Learning (DL) Boost name. This primarily includes the Vector Neural Network Instruction (VNNI) set, which can do in one instruction what would have previously taken three. However even farther down the line, Cooper Lake, the third-generation Xeon Scalable processor, will add support for bfloat16, further improving training performance.
In summary, Intel trying to recapture the market for “lighter AI workloads” while making a firm stand in the rest of data analytics market, all the while adding very specialized hardware (FPGA, ASICs) to their portfolio. This is of critical importance to Intel's competitiveness in the IT market. Intel has repeatedly said that the data center group (DCG) or “enterprise part” is expected to be the company's main growth engine in the years ahead.
NVIDIA’s Answer: RAPIDS Bring GPUs to More Than CNNs
NVIDIA’s has proven more than once that it can outmaneuver the competition with excellent vision and strategy. NVIDIA understands that getting all neural networks to scale as CNNs is not going to be easy, and that there are a lot of applications out there that are either running on other methods than neural networks, or which are memory intensive rather than compute intensive.
At GTC Europe, NVIDIA launched a new data science platform for enterprise use, built on NVIDIA’s new “RAPIDS” framework. The basic idea is that the GPU acceleration of the data pipeline should not be limited to deep learning.
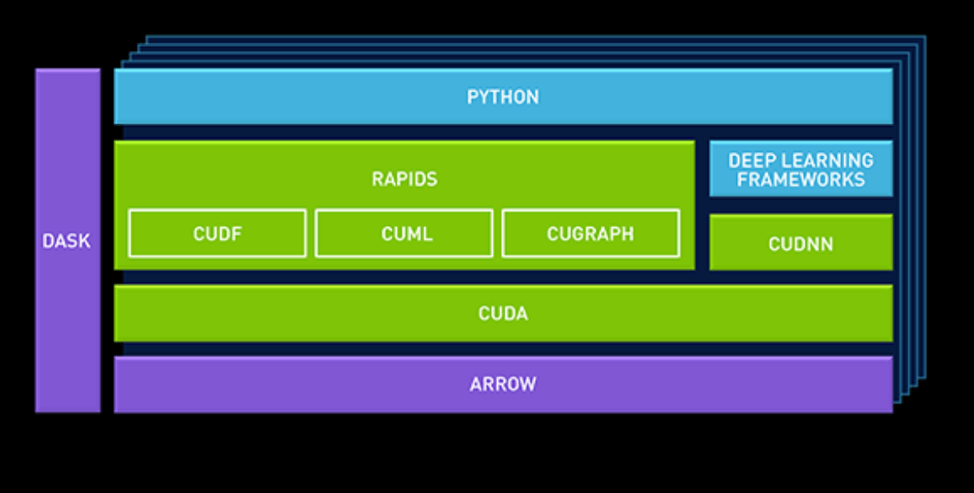
CuDF, for example, allows data scientists to load data into GPU memory and batch process it, similar to Pandas (the python library for manipulating data). cuML is a currently limited collection of GPU-accelerated machine learning libraries. Eventually most (all?) machine learning algorithms available in Scikit-Learn toolkit should be GPU accelerated and available in cuML.
NVIDIA also added Apache Arrow, a columnar in-memory database. This is because GPUs operate on vectors, and as a result favor a columnar layout in memory.
By leveraging Apache arrow as a “central database”, NVIDIA avoids a lot of overhead.
Making sure that there are GPU accelerated versions of the typical Python libraries such as Sci-Kit and Pandas is one step in right direction. But Pandas is only suited for the lighter “data science exploration” tasks. By working with Databricks to make sure that RAPIDS is also used in the heavy duty, distributed “data processing” framework Spark, NVIDIA is taking the next step, breaking out of the "Deep learning mostly" role and towards "NVIDIA in the rest of the data pipeline".
However, the devil is in the details. Adding GPUs to a framework that has been optimized for years to make optimal use of CPU cores and the massive amounts of RAM available in servers is not easy. Spark is built to run on a few tens of powerful server cores, not thousands of wimpy GPU cores. Spark has been optimized to run on clusters of server nodes, making it seem like one big lump of RAM memory and cores. Mixing two kinds of memory – RAM and GPU VRAM – and keeping the distributed compute nature of Spark intact will not be easy.
Secondly, cherry picking the most GPU-friendly machine learning algorithms is one thing, but making sure most of them run fine in GPU-based machine is another thing. Lastly, GPUs will still have less memory than CPUs for the foreseeable future; and even coherent platforms won’t solve the problem that system RAM is a fraction of the speed of local VRAM
Who Will Win the Next Enterprise Market?
At their last investors day, one of NVIDIA’s slides made it clear what the next battle in the enterprise space will be all about: data analytics. Note how an expensive dual Xeon “Skylake” Scalable is considered as baseline. That is quite a statement; reducing one of the latest Intel powered systems to a completely outperformed humble baseline.
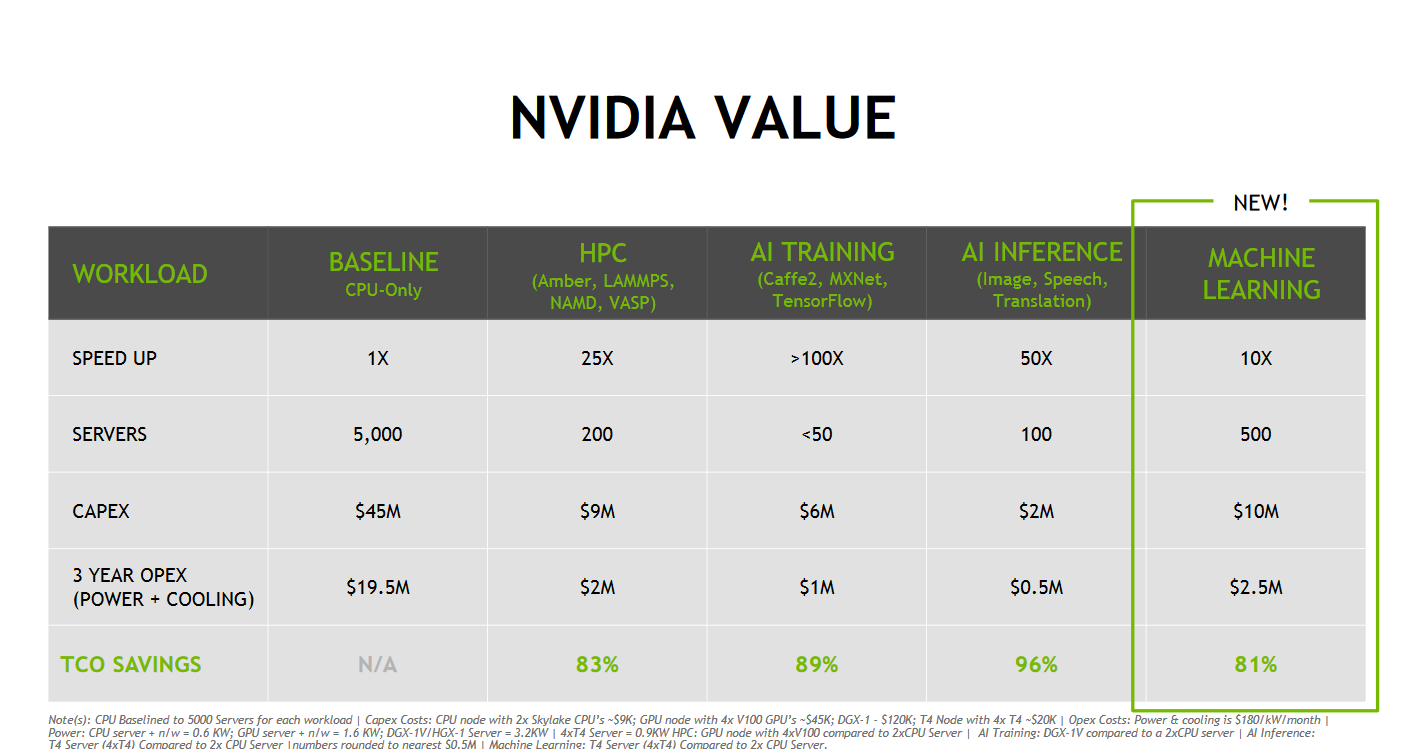
NVIDIA’s entire business model revolves around the theory that buying expensive hardware like DGXs and Teslas is good for your TCO (“the more you buy, the more you save”). Don’t buy 5000 servers, buy 50 DGXes. Despite the fact that a DGX consumes 5 times more power, and costs $120k instead of $9k, you will be much better off. Of course, this is marketing at its best – or at its worst, depending on how you look at it. But even if the numbers are slightly exaggerated, it is a strong message: “from our deep learning stronghold to the Intel’s current growth market (Inference, HPC and machine learning), we will beat Intel by a large margin”.
Not convinced? This is how NVIDIA and IDC see the market evolving.
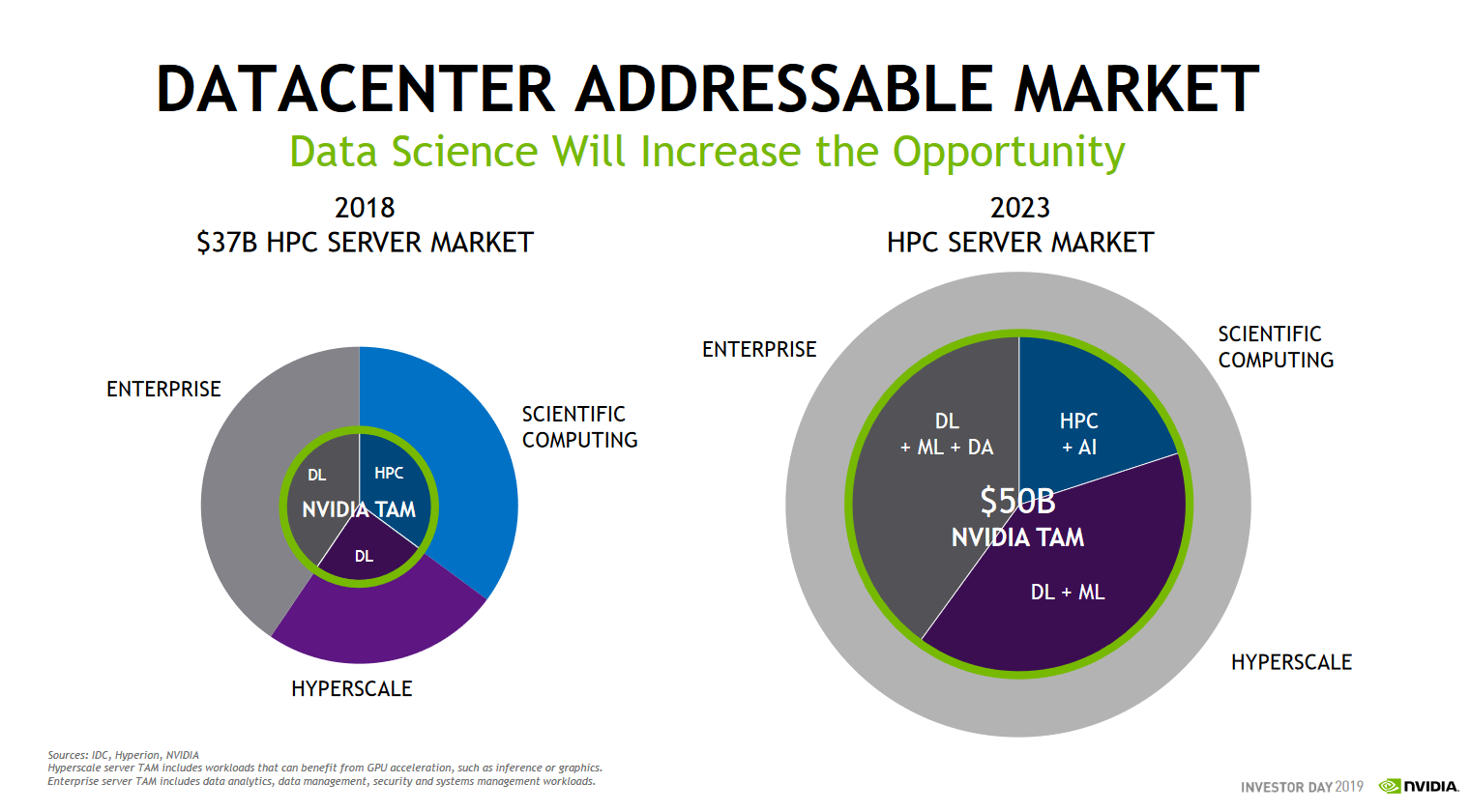
Currently the compute intensive or high-performance sub-market is about $37 billion out of a total $100 billion market. NVIDIA believes that this sub-market will double by 2023 and that they will be able to address $50 billion. In other words, the data analytics market – in a broad sense – will be almost half of the complete server market.
Even if this is an overestimation, it is clear that times are changing, and the stakes are very high. Neural networks are much better suited to GPUs, but if Intel can make sure that most of data pipeline runs better on CPUs and you only need a GPU for the most intensive and scalable neural networks, it will push NVIDIA back to a more niche role. On the other hand, if NVIDIA can accelerate a much larger part of the data pipeline, it will conquer markets that mostly belong to Intel and expand rapidly. And in the midst of this heated battle, IBM and AMD must make sure they get their share of the market. IBM will be offering better NVIDIA GPU based servers, and AMD will try building the right software ecosystem.
Testing Notes
As the market stands, it is clear that alongside AMD and ARM, NVIDIA's professional offerings are a real threat to Intel's dominance in the datacenter and beyond. So for our testing today, we're going to focus on machine learning, and see just how Intel's new DL Boosted wares fare against the competition in the ML space.
On the Intel side of matters, of course, we're looking at the company's new Cascade Lake Xeon Scalable CPUs. The company provided two of their 28 core models, with the 165 Watt Xeon Platinum 8176, as well as the even faster 205 Watt Xeon Platinum 8280.
As for Cascade Lake's GPU competition, we've tapped NVIDIA's latest "Turing" Titan RTX card. While these aren't truly datacenter cards, the fact that they're based Turing means that they offer NVIDIA's very latest features. At the university that I work for, our deep learning researchers use these GPUs for training AI models as the Titan cards are affordable and have a lot of GPU memory available.
As an added bonus, Titan RTX cards can be used for both training (Hybrid FP32/16) as inference (FP16 and INT8). The current Tesla is still based on NVIDIA's Volta architecture, which does not have INT8 available for inference.
Finally, not to be excluded, we've also included AMD's first-generation EPYC platform in all of our testing. AMD doesn't have a hardware strategy quite like Intel – or specific instructions like VNNI – but as of late the company has offered all sorts of surprises.
Benchmark Configuration and Methodology
All of our testing was conducted on Ubuntu Server 18.04 LTS. You will notice that the DRAM capacity varies among our server configurations. This is of course a result of the fact that Xeons have access to six memory channels while EPYC CPUs have eight channels. As far as we know, all of our tests fit in 128 GB, so DRAM capacity should not have much influence on performance. But it will have a impact on total energy consumption, which we will discuss.
Last but not least, we want to note how the performance graphs have been color-coded. Orange is AMD's EPYC, dark blue is Intel's best (Cascade Lake/Skylake-SP), and light blue is the previous generation Xeons (Xeon E5-v4) . Gray has been used for the soon-to-be-replaced Xeon v1.
Intel's Xeon "Purley" Server – S2P2SY3Q (2U Chassis)
| CPU | Two Intel Xeon Platinum 8280 (2.7 GHz, 28c, 38.5MB L3, 205W) Two Intel Xeon Platinum 8176 (2.1 GHz, 28c, 38.5MB L3, 165W) |
| RAM | 384 GB (12x32 GB) Hynix DDR4-2666 |
| Internal Disks | SAMSUNG MZ7LM240 (bootdisk) Intel SSD3710 800 GB (data) |
| Motherboard | Intel S2600WF (Wolf Pass baseboard) |
| Chipset | Intel Wellsburg B0 |
| PSU | 1100W PSU (80+ Platinum) |
We enabled hyper-threading and Intel virtualization acceleration.
Xeon - NVIDIA Titan RTX Workstation
With some diplomacy, our AI researcher Pieter Bovijn at MCT was so kind to test his deep learning workstation. Below you can find the specs.
| CPU | Intel Xeon Gold 6152 (2.1 GHz, 22c, 30.25MB L3, 140W) |
| RAM | 192 GB (6x32 GB) Samsung DDR4-2666 |
| Internal Disks | SAMSUNG MZ7LM240 (bootdisk) Intel SSD3710 800 GB (data) |
| Motherboard | Supermicro SYS-7049A-T (Intel C621 chipset) |
| GPU | PNY TITAN RTX 24 GB GDDR6 |
| PSU | PWS-865-PQ |
This is the only server in the test with a discrete GPU.
AMD EPYC 7601 – (2U Chassis)

| CPU | Two EPYC 7601 (2.2 GHz, 32c, 8x8MB L3, 180W) |
| RAM | 512 GB (16x32 GB) Samsung DDR4-2666 @2400 |
| Internal Disks | SAMSUNG MZ7LM240 (bootdisk) Intel SSD3710 800 GB (data) |
| Motherboard | AMD Speedway |
| PSU | 1100W PSU (80+ Platinum) |
Other Notes
Both servers are fed by a standard European 230V (16 Amps max.) power line. The room temperature is monitored and kept at 23°C by our Airwell CRACs.
CPU Performance: Intel's Own Claims
Before we get into the new AI benchmarks, let’s take a quick look at the usual CPU benchmarks and performance claims made available by Intel.

For this comparison we’ll focus on the second row – the first row is comparing the insanely priced 400W dual-die Intel Platinum 9282 to a much more reasonable and available to everyone Intel Platinum 8180. The second row tells it all: a few MHz and slightly higher RAM speeds result in a 3% (Integer) to 5% (FP) performance increase compared to the first-generation Xeon Scalable parts. The higher boost in floating point performance is probably the result of the fact that Intel's second generation parts can use faster DDR4-2933 DIMMs and hence offer more bandwidth to the cores.
The midrange SKUs get a bigger boost as some of x2xx Xeon Scalable parts get more cores and more L3 cache than the previous x1xx parts. For example, the 6252 has 24 cores and 35.75 MB L3, while the 6152 had 22 cores and 30.25 MB L3.

The comparison with AMD's EPYC 7601 however deserves our attention, as there’s some interesting data here. Again, the comparison of a 400W, $50k chiplet CPU with a 180W $4k one does not make any sense whatsoever, so we ignore the first line.
The Linpack numbers are not surprising: the more expensive Skylake SKUs add a 512-bit FMAC to the already existing dual 256-bit FMACs, offering up to 4 times more AVX throughput than AMD's EPYC. AMD's next generation will be a lot more competitive in this area as the each FP unit is now capable of doing 256-bit AVX instead of 128-bit.
The image classification results clearly show that Intel is trying to convince people that some AI applications should simply run on a CPU, no GPU needed. Well, at least for now…
The fact that Intel claims that database performance is a lot better than on the EPYC is quite interesting, as we’ve previously pointed out that AMD's four NUMA dies on a chip does have drawbacks. Quoting our Xeon Skylake vs EPYC review:
Out of the box, the EPYC CPU is a rather mediocre transactional database CPU ... transactional databases will remain Intel territory for now.
In databases, cache (coherency) latency plays an important role. It will be interesting to see how well AMD has addressed this weakness in the second generation EPYC server chips.
SAP S&D
One last stop before we start with our data analytics/ML benchmarks: SAP. Enterprise Resource Planning software is the perfect example of "traditional" enterprise software.
The SAP S&D 2-Tier benchmark is probably the most real-world benchmark of all the server benchmarks done by the vendors. It is a full-blown application living on top of a heavy relational database.
We analyzed the SAP Benchmark in-depth in one of our earlier articles:
- Very parallel resulting in excellent scaling
- Low to medium IPC, mostly due to "branchy" code
- Somewhat limited by memory bandwidth
- Likes large caches (memory latency)
- Very sensitive to sync ("cache coherency") latency
There are lots of benchmarks result available from different vendors. To get a (more or less) apples-to-apples comparison, we limited ourselves to the "SAPS results" running on top of SQL Server 2012 Enterprise.
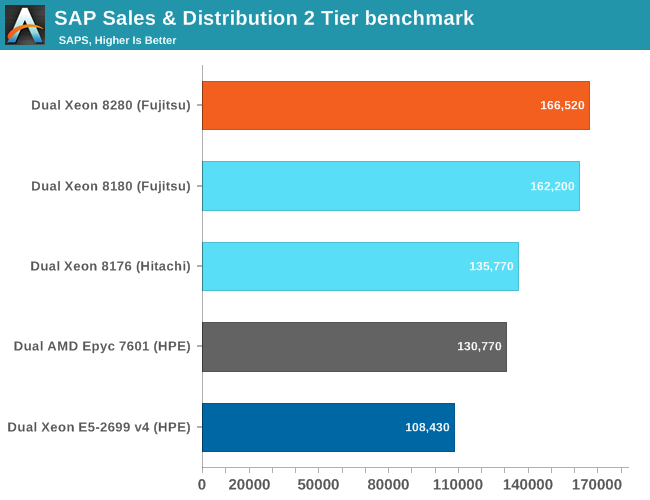
The Fujitsu benchmarks with the Xeon 8180 and 8280-based servers are as apples-to-apples as we can get: the same people who did the testing and tuning, the same OS and database. The slightly higher clocks (+200 Mhz, +8%) result in 3% higher performance. Both CPUs have 28 cores, but the 8280 has an 8% higher clockspeed, and in some senses it’s surprising that this bump in clockspeeds didn’t result in a larger performance increase. We get the impression that Cascade Lake might even be slightly slower clock per clock than Skylake, as both SPEC CPU benchmarks also increased by only three to five percent.
So in the typical enterprise stack, you’re looking at getting around 3% higher performance for the same price/energy consumption. However, AMD's much cheaper (ed: and soon to be updated) $4k EPYC 7601 is not that far behind. Considering that the EPYC is already within a margin of error of the twice as expensive 8176 (2.1 GHz, 28 cores), the 8276 with its slightly higher clockspeed (2.2 Ghz) does not significantly improve matters. Even the Xeon 8164 (26 cores at 2 GHz) offers about the same performance as the EPYC 7601, but still costs 50% more.
Considering how much progress AMD has made with the Zen 2 architecture, and the fact that the top SKUs will double the amount of cores (64 vs 32), it looks like AMD Rome will put even more pressure on Xeon sales.
Apache Spark 2.1 Benchmarking
Apache Spark is the poster child of Big Data processing. Speeding up Big Data applications is the top priority project at the university lab I work for (Sizing Servers Lab of the University College of West-Flanders), so we produced a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large number of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We our newest servers into virtual clusters to make better use of all those core. We run with 8 executors. Researcher Esli Heyvaert also upgraded our Spark benchmark so it could run on Apache Spark 2.1.1.
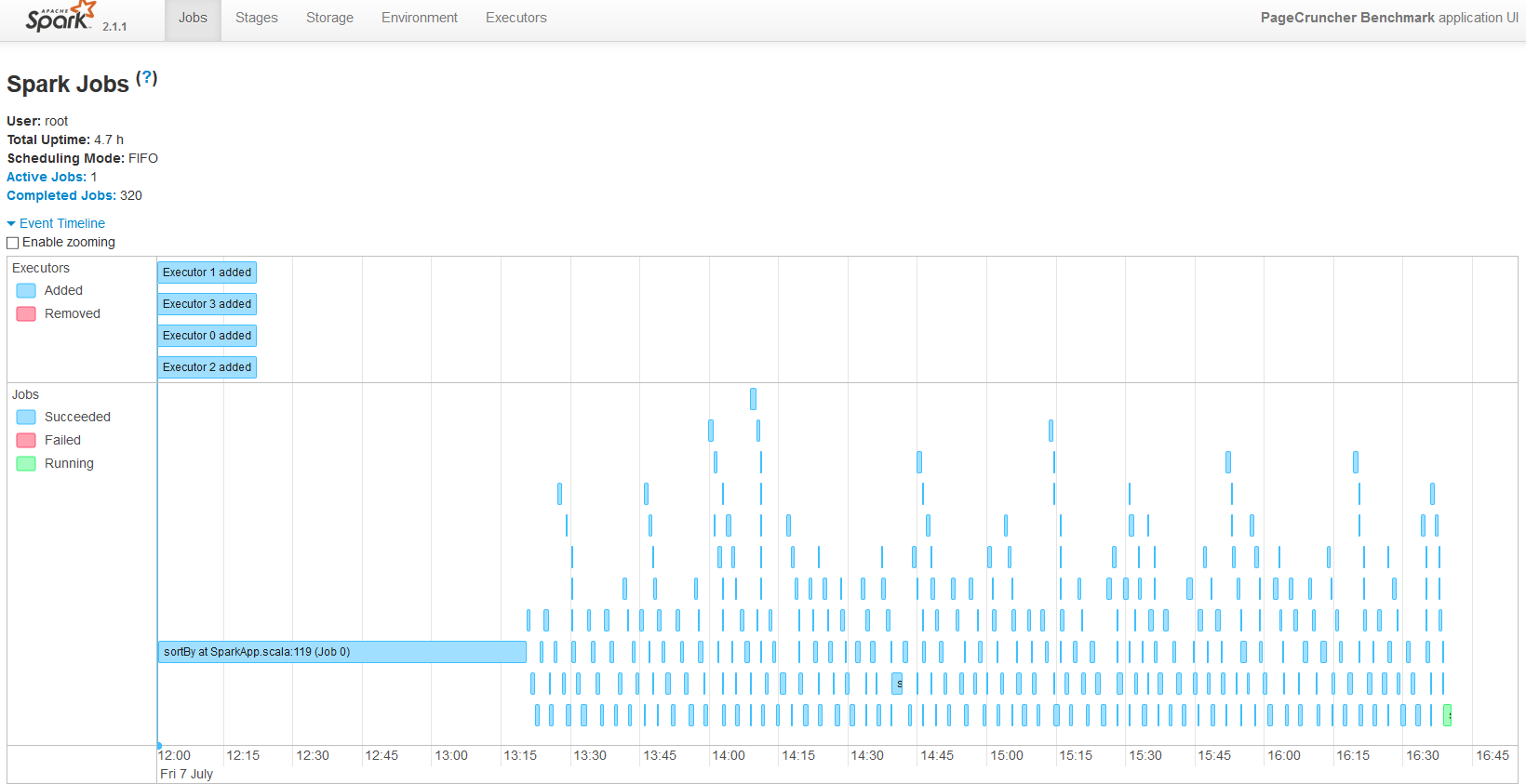
Here are the results:
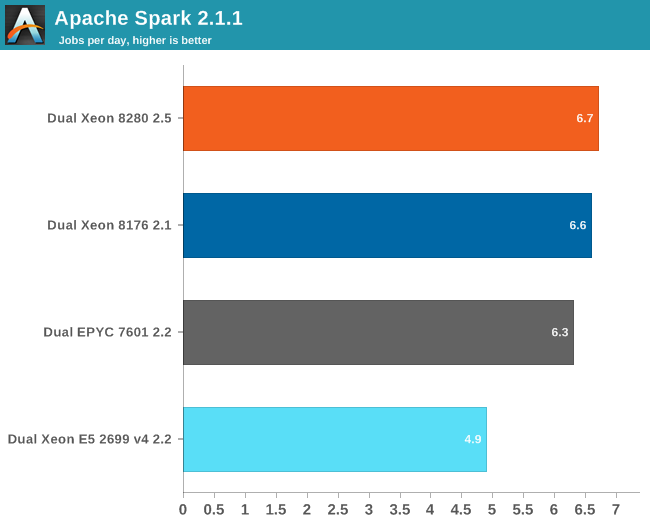
Our Spark benchmark needs about 120 GB of RAM to run. The time spent on storage I/O is negligible. Data processing is very parallel, but the shuffle phases require a lot of memory interaction. The ALS phase does not scale well over many threads, but it is less than 4% of the total testing time.
For reasons unknown to us, we could get our 2.7 GHz 8280 to perform much better than the 2.1 GHz Xeon 8176. We suspect that the fact that we used the new Xeon chips with an older (Skylake-SP) server could be the reason, as trying different Spark configurations (executors, JVM settings) did not help. A BIOS update did not help us either.
Ok, this was big data processing combined with mostly "traditional" Machine learning: NER and ALS. How about some "deep learning"?
Convolutional Neural Network Training
For a long time, the way forward in CNNs was to increase the number of layers – increasing the network depth for "even deeper learning". As you can probably guess, this resulted in diminishing returns and made the already complex neural networks even harder to tune, leading to more training errors.
The ResNet-50 benchmark is based upon residual networks (hence ResNet), which have the merit of fewer training errors as the network gets deeper.
Meanwhile, as a little bit of internal housekeeping here, for regular readers I’ll note that the benchmark below is not directly comparable to the one that Nate ran for our Titan V review. It is the same benchmark, but Nate ran the standard ResNet-50 training implementation that is included in NVIDIA's Caffe2 Docker image. However, since my group is mostly using TensorFlow as a deep learning framework, we tend to with stick with it. All benchmarking
tf_cnn_benchmarks.py --num_gpus=1 --model=resnet50 --variable_update=parameter_server
The model trains on ImageNet and gives us throughput data.
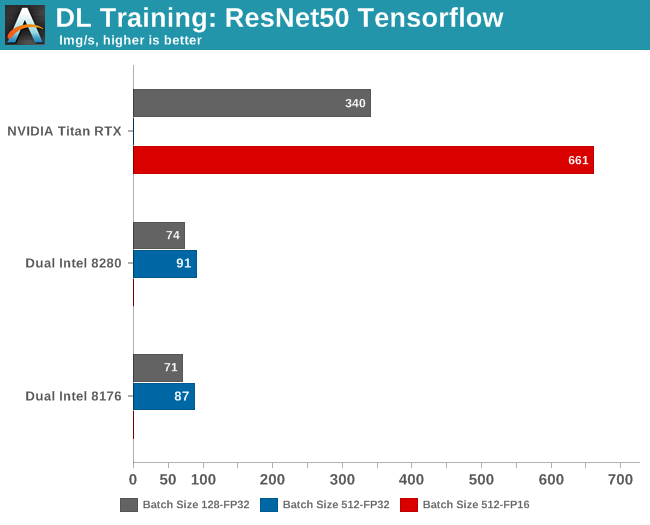
Several benchmarks are missing, and for a good reason. Running a batch size of 512 training samples at FP32 precision on the Titan RTX results in an "out of memory" error, as the card "only" has 24 GB available.
Meanwhile on the Intel CPUs, half precision (FP16) is not (yet) available. AVX512_BF16 (bfloat16) will be available in the Cascade Lake's successor, Cooper Lake.
It has been observed that using a larger batch can causes significant degradation in the quality of the model, as measured by its ability to generalize. So although larger batch sizes (512) make better use of the massive parallelism inside the GPU, the results with the lower batch sizes (128) are useful too. The accuracy of the model loses only a few percent, but in many applications a loss of even a few percent is a significant.
So while you could quickly conclude that Titan RTX is seven times faster than the best CPU, it is more accurate to say that it is between 4.5 and 7 times faster depending on the accuracy you want.
Inception (v3)
Inception is based upon GoogLeNet. Contrary to the earlier dense neural networks, GoogLeNet was based on the idea that neural networks can be much more efficient if you do not connect every neuron in every layer to the next one. The downside of this optimization is that this results in sparse matrices, which are far from optimal for the typical SIMD/GPU architectures and their BLAS software.
Overall, the main goal of "Inception" was to turn GoogLeNet into a neural network that would result in dense matrix multiplication. Or in other words, something that ran a lot faster on a GPU or SIMD hardware. In the end, version 3 of this neural network has proven to be even more accurate than ResNet-50.
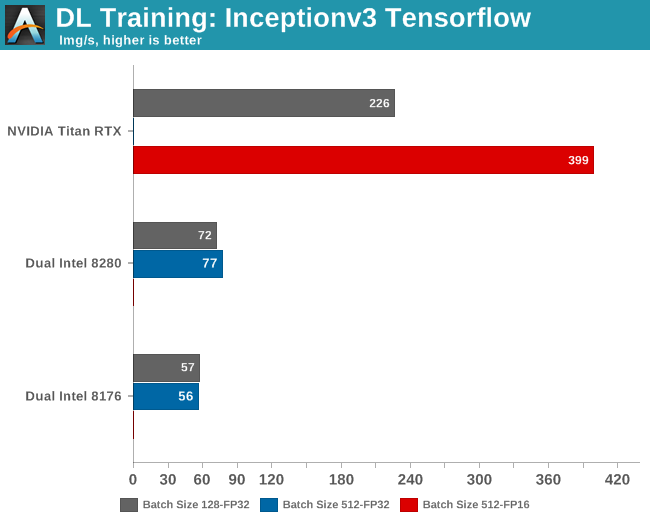
This time, the GPU is about 3 to 5 times faster, depending on the batch size. It is interesting to note that ResNet is more GPU friendly than Inception. But of course, this only matters for academics and hardware enthusiasts.
Software engineers who have to build AI models will however remark quickly that a $3k GPU is at least 3 times faster than a $20k+ (or worse) CPU configuration. And they are right: there is no contest. When it comes to Convolutional Neural Networks, the rock stars of AI, a good GPU (with a good software stack) will mop the floor with even the best CPUs. In a datacenter you typically encounter the NVIDIA Tesla GPUs which cost around four times more, but offer anywhere from 1.5x to 2x the performance of similar Titan cards.
Recurrent Neural Networks: LSTM
Our loyal readers know that we love real-world enterprise benchmarks. So in our quest for better benchmarks and better data, Pieter Bovijn, the head of research at the MCT IT Bachelor (dutch), turned a real-world AI model into a benchmark.
The input of the model is time series data, which is used to make predictions on how the time series will behave in the future. As this is a typical sequence prediction problem, we used a Long Short-Term Memory (LSTM) network as neural network. A type of RNN, LSTM selectively "remembers" patterns over a certain duration of time.
LSTM however come with the disadvantage that they are a lot more bandwidth intensive. We quote a recent paper on the topic:
LSTMs exhibit quite inefficient memory access pattern when executed on mobile GPUs due to the redundant data movements and limited off-chip bandwidth.
So we were very curious about how the LSTM network would behave. After all, our server Xeons have ample bandwidth, with a massive 38.5 MB of L3 and six channels of DDR4-2666/2933 (128-141 GB/s per socket). We run this test with 50 GB of data, and train the model for 5 epochs.
Of course, you have the make the most of the available AVX/AVX2/AVX512 SIMD power. That is why we tested with 3 different setups
- We used out of the box TensorFlow with conda
- We tested with the Intel optimized TensorFlow from PyPi repo
- We optimized from source using Bazel. This allowed us to use the very latest version of TensorFlow.
The results are very interesting.
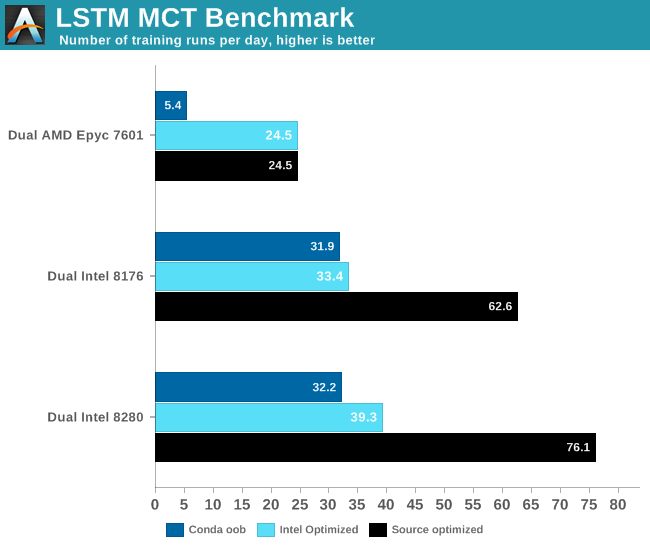
The most intensive TensorFlow applications are typically run on GPUs, so extra care must be taken when you test on a CPU. AMD's Zen core only has two 128-bit FMACs, and is limited to (256-bit) AVX2. Intel's high-end Xeons have two 256-bit FMACs and one 512-bit FMAC. In other words, on paper Intel's Xeon can deliver four times more FLOPs per clock cycle than AMD. But only if the software is right. Intel has been working intensively with Google to optimize TensorFlow for Intel new Xeons out of necessity: it has to offer a credible alternative in those situations where an NVIDIA Tesla is simply too expensive. Meanwhile, AMD hopes that ROCm catches on and that in the future software engineers run TensorFlow on a Radeon Pro.
Of course, the big question is how this compares to a GPU. Let us see how our NVIDIA Titan RTX deals with this workload.
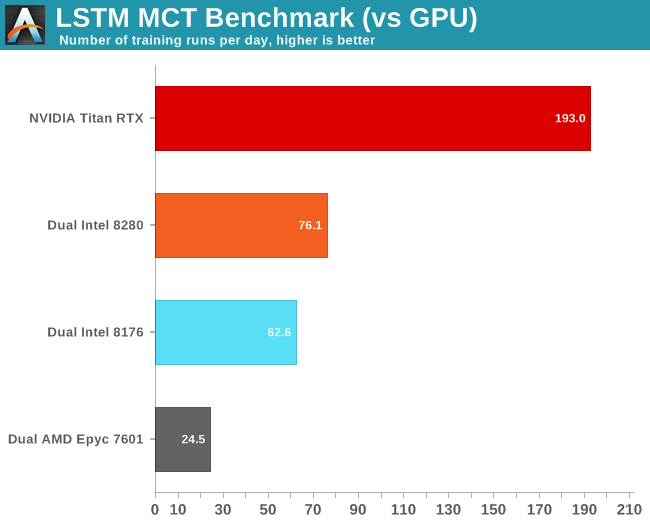
First of all, we noticed that FP16 did not make much of a difference. Secondly, we were quite amazed that our Titan RTX was less than 3 times faster than our dual Xeon setup.
Investigating further with NVIDIA's System Management Interface (SMI), we found out that GPU did run at a its highest turbo speed: 1.9 GHz, which is higher than the expected 1.775 GHz. Meanwhile utilization dropped to 40% from time to time.
Ultimately this is another example of how real-world applications behave differently from benchmarks, and how important software optimization is. If we would have just used conda, the results above would be very different. Using the right optimized software made the application run 2 to 6 times faster. Also, this another data point that proves that CNNs might be one of the best use cases for GPUs. You should use a GPU to decrease training times of complex LSTMs of course. Still, this kind of neural network is a bit more tricky - you cannot simply add more GPUs to further decrease training time.
Inference: ResNet-50
After training your model on training data, the real test awaits. Your AI model should now be able to apply those learnings in the real world and do the same for new real-world data. That process is called inference. Inference requires no back propagation as the model is already trained – the model has already determined the weights. Inference also can make use of lower numerical precision, and it has been shown that even the accuracy from using 8-bit integers is sometimes acceptable.
From a high-level workflow perfspective, a working AI model is basically controlled by a service that, in turn, is called from another software service. So the model should respond very quickly, but the total latency of the application will be determined by the different services. To cut a long story short: if inference performance is high enough, the perceived latency might shift to another software component. As a result, Intel's task is to make sure that Xeons can offer high enough inference performance.
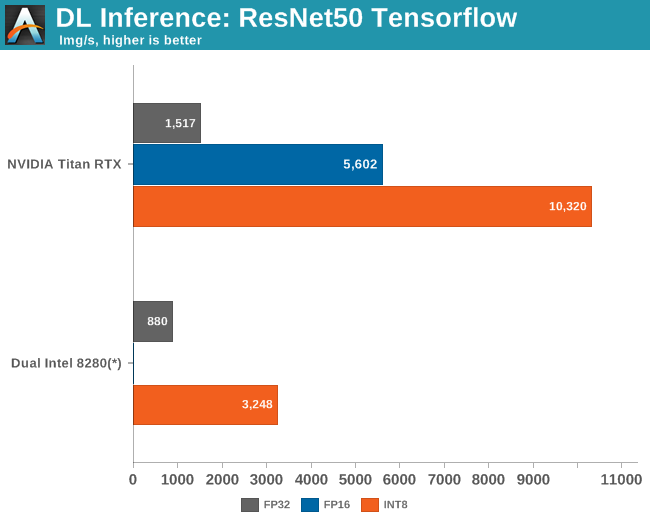
Intel has a special "recipe" for reaching top inference performance on the Cascade Lake, courtesy of the DL Boost technology. DLBoost includes the Vector Neural Network Instructions, which allows the use of INT8 ops instead of FP32. Integer operations are intrinsically faster, and by using only 8 bits, you get a theoretical peak, which is four times higher.
Complicating matters, we were experimenting with inference when our Cascade Lake server crashed. For what it is worth, we never reached more than 2000 images per second. But since we could not experiment any further, we gave Intel the benefit of the doubt and used their numbers.
Meanwhile the publication of the 9282 caused quite a stir, as Intel claimed that the latest Xeons outperformed NVIDIA's flagship accelerator (Tesla V100) by a small margin: 7844 vs 7636 images per second. NVIDIA reacted immediately by emphasizing performance/watt/dollar and got a lot of coverage in the press. However, the most important point in our humble opinion is that the Tesla V100 results are not comparable, as those 7600 images per second were obtained in mixed mode (FP32/16) and not INT8.
Once we enable INT8, the $2500 Titan RTX is no less than 3 times faster than a pair of $10k Xeons 8280s.
Intel cannot win this fight, not by a long shot. Still, Intel's efforts and NIVIDA’s poking in response show how important it is for Intel to improve both inference and training performance; to convince people to invest in high end Xeons instead of a low end Xeon with a Tesla V100. In some cases, 3 times slower than NVIDIA's offering might be good enough as the inference software component is just one part of the software stack.
In fact, to really analyze all of the angles of the situation, we should also measure the latency on a full-blown AI application instead of just measuring inference throughput. But that will take us some more time to get that one right....
Exploring Parallel HPC
HPC benchmarking, just like server software benchmarking, requires a lot of research. We are definitely not HPC experts, so we will limit ourselves to one HPC benchmark.
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP.
To be fair, NAMD is mostly single precision. And, as you probably know, the Titan RTX was designed to excel at single precision workloads; so the NAMD benchmark is a good match for the Titan RTX. Especially now that the NAMD authors reveal that:
Performance is markedly improved when running on Pascal (P100) or newer CUDA-capable GPUs.
Still, it is an interesting benchmark as the NAMD binary is compiled with Intel ICC and optimized for AVX. For our testing, we used the "NAMD_2.13_Linux-x86_64-multicore" binary. This binary supports AVX instructions, but only the "special” AVX-512 instructions for the Intel Xeon Phi. Therefore, we also compiled an AVX-512 ICC optimized binary. This way we can really measure how well the AVX-512 crunching power of the Xeon compares to NVIDIA’s GPU acceleration.
We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
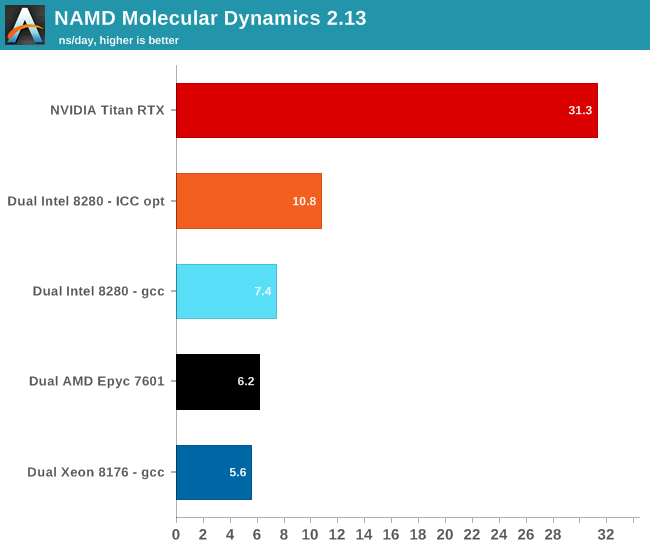
Using AVX-512 boosts performance in this benchmark by 46%. But again, this software runs so much faster on a GPU, which is of course understandable. At best, the Xeon has 28 cores running at 2.3 GHz. Each cycle 32 single precision floating operations can be done. All in all, the Xeon can do 2 TFLOPs (2.3 G*28*32). So a dual Xeon setup can do 4 TFLOPs at the most. The Titan RTX, on the other hand, can do 16 TFLOPs, or 4 times as much. The end result is that NAMD runs 3 times faster on the Titan than on the dual Intel Xeon.
Analyzing Intel's Cascade Lake in the New Era of AI
Wrapping things up, let’s take stock of the second-generation Xeon Scalable’s performance, and what it brings to the table in terms of features. With Cascade Lake Intel has improved performance by 3 to 6%, improved security, fixed some incredibly important bugs/exploits, added some SIMD instructions, and improved the overall server platform. This is nothing earth shattering, but you get more for the same price and power envelope, so what’s not to like?
That would be fine 5 years ago, when AMD did not have anything like the Zen(2) architecture, ARM vendors were still struggling with cores that offered painfully slow single-threaded performance, and deep learning was in the early stages. But this is not 2014, when Intel outperformed the nearest competition by a factor 3! Ultimately Cascade Lake delivers in areas where CPUs – and only CPUs – do well. But even with Intel’s DL Boost efforts, it’s not enough if the new chips have to go head-to-head with a GPU in a task the latter doesn’t completely suck at.
The reality is that Intel's datacenter group is under tremendous pressure from all sides, and the numbers are showing it. For the first time in years, the datacenter experienced a revenue drop, despite the fact that the overall server market is growing.
It is been going on for a while, but as we’ve experienced firsthand, machine learning-based AI applications are being rolled out successfully, and they are a game changer for both software and hardware. As a result, future server CPU reviews will never quite be the same: it is not Intel versus AMD or even ARM anymore, but NVIDIA too. NVIDIA is extremely successful in the deep learning market, and they are confident enough to take on Intel in areas where Intel dominated for years: HPC, machine learning, and even data processing. NVIDIA is ready to accelerate a much larger part of the data pipeline and a wider range of AI applications.
Features found in Intel Cascade Lake like DL Boost (VNNI) are the first attempts by Intel to push back – to cut away at the massive advantage that NVIDIA has in inference performance. Meanwhile, the next Xeon – Cooper Lake – will try to get closer to NVIDIA in training performance.
Moving on, when we saw this slide, we were gasping for air.

This slide boasting "leadership performance" also conveniently describes the markets where Intel is a very vulnerable position, despite Intel's current dominant position in the datacenter. Although the slide focuses on the Intel Xeon 9200, this could easily be a slide for the high-end Platinum 8200 Xeons too.
Intel points towards HPC, AI, and high-density infrastructure to sell their massively expensive Xeons. But as the market shifts towards less traditional business intelligence and more machine learning, and more GPU-accelerated HPC, the market for high end Xeons is shrinking. Intel has a very broad AI portfolio from Movidius (edge inference) to Nervana NNP (ASIC for DL training), and they’re going to need it to replace the Xeon in those segments where it falls out.
A midrange Xeon combined with a Nervana NNP coprocessor might work out well – and it would definitely be a better solution for most AI applications than a Xeon 9200. And the same is true for HPC: we are willing to bet that you are much better off with midrange Xeons and a fast NVIDIA GPU. And depending on where AMD's EPYC 2 pricing goes, even that might end up being debatable...






