Original Link: https://www.anandtech.com/show/12084/epyc-benchmarks-by-intel-our-analysis-
Dissecting Intel's EPYC Benchmarks: Performance Through the Lens of Competitive Analysis
by Johan De Gelas & Ian Cutress on November 28, 2017 9:00 AM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Skylake-SP
- Xeon Platinum
- EPYC
- EPYC 7601
Although the AMD EPYC is definitely a worthy contender in the server space, AMD's technical marketing of the new CPU has been surprisingly absent, as the company not published any real server benchmarks. The only benchmarks published were SPEC CPU and Stream, with AMD preferring for its partners and third parties to promote performance. And, as our long-time readers know, while the SPEC CPU benchmarks have their merits and many people value them, they are a very poor proxy of most server workloads.
In every launch, we expect companies to offer an element of competitive analysis, often to show how their platform is good or better than the rest. At the launch of Intel's latest Xeon-SP platform, analysis to EPYC was limited to a high-level, as the systems were not as freely available as expected. AMD was able to do so on Broadwell-E at the time of the EPYC announcement because it was out and available - Intel wasn't able to do it on EPYC because AMD were several months away from moving it from a cloud-only ramp up program. This is partly the effect of AMD's server market implementation and announcement roadmap, although it didn't stop Intel from hypothesising about the performance deficits in ways that caught the attention of a number of online media.
Throughout all of this, AMD could not resist but to continue to tell the world that the "EPYC SoC Sets World Records on SPEC CPU Benchmarks". In the highly profitable field that is server hardware, this could not be left unanswered by Intel, who responded that the Intel Xeon Scalable has great "momentum" with no less than 110 performance records to date.
Jumping to the present time, in order to to prove Xeon-SP dominance over the competition, Intel's data center engineering group has been able to obtain a few EPYC systems and has started benchmarking. This benchmarking, along with justifications of third-party verification, was distributed to the small set of Xeon-SP launch reviewers as a guide, to follow up on that high-level discussion some time ago. The Intel benchmarking document we received had a good amount of detail however, and the conference call we had relating to it was filled with some good technical tidbits.
Our own benchmarks showed that the EPYC was a very attractive alternative in some workloads (Java applications), while the superior mesh architecture makes Intel's Xeon the best choice in other (Databases for example).
A Side Note About SPEC
A number of these records were achieved through SPEC. As mentioned above, while SPEC is a handy tool for comparing the absolute best tweaked peak performance of the hardware underneath, or if the system wants to be analysed close to the metal because of how well known the code base is, but this has trouble transferring exactly to the real world. A lot of time the software within a system will only vaguely know what system it is being run on, especially if that system is virtualised. Sending AVX-512 commands down the pipe is one thing, but SPEC compilation can be tweaked to make sure that cache locality is maintained whereas in the real-world, that might not be possible. SPEC says a lot about the system, but ultimately most buyers of these high-end systems are probing real-world workloads on development kits to see what their performance (and subsequent scale-out performance) might be.
For the purposes of this discussion, we have glossed over Intel's reported (and verified over at SPEC.org) results.
Pricing Up A System For Comparison
Professionals and the enterprise market will mention, and quite rightly, that Intel has been charging some heavy premiums with the latest generation, with some analysts mentioning a multiple jump up in pricing even for large customers, making it clear that the Xeon enterprise CPU line is their bread and butter. Although Intel's top-end Xeon Platinum 8180 should give the latest EPYC CPU a fit of trouble thanks to its 28 Skylake-SP cores running at 2.5 to 3.8 GHz, the massive price tag ($10009 for the standard version, $13011 for the high-memory model) made sure that Intel's benchmarking team had no other choice than also throwing in a much more modest Xeon Platinum 8160 (24 cores at 2.1 - 3.7 GHz, $4702k) as well as the Xeon Gold 6148 (20 cores at 2.4-3.7 GHz, $3072).
| SKUS Tested | |||||
| Intel Xeon Platinum 8180 |
Intel Xeon Platinum 8160 |
Intel Xeon Gold 6148 |
AMD EPYC 7601 |
||
| Release Date | Early Q3, 2017 | Late Q2, 2017* | |||
| Microarchitecture | Skylake-SP with AVX-512 | Zen | |||
| Process Node | Intel 14nm (14+) | GloFo 14nm | |||
| Cores / Threads | 28 / 56 | 24 / 48 | 20 / 40 | 32 / 64 | |
| Base Frequency | 2.5 GHz | 2.1 GHz | 2.4 GHz | 2.2 GHz | |
| Turbo | 3.8 GHz | 3.7 GHz | 3.7 GHz | 3.2 GHz | |
| L2 Cache | 28 MB | 24 MB | 20 MB | 16 MB | |
| L3 Cache | 38.5 MB | 33.0 MB | 27.5 MB | 64 MB | |
| TDP | 205 W | 150 W | 150 W | 180 W | |
| PCIe Lanes | 48 (Technically 64 w/ Omni-Path Versions) | 128 | |||
| DRAM | 6-channel DDR4 | 8ch DDR4 | |||
| Max Memory | 768 GB | 2048 GB | |||
| Price | $10009 | $4702 | $3072 | $4200 | |
As a result of this pricing, one of the major humps for Intel in any comparison will be performance per dollar. In order to demonstrate that systems can be equivalent, Intel offered up this comparison from a single retailer. Ideally Intel should have offered multiple configurations options for this comparison, given that a single retailer can intend for different margins on different sets of products (or have different levels of partnership/ecosystem with the manufacturers).

Even then, price parity could only be reached by giving the Intel system less DRAM. Luckily this was the best way to configure the Intel based system anyway. We can only guess how much the benchmarking engineers swore at the people who set the price tags: "this could have been so much easier...". All joking apart, the document we received had a good amount of detail, and similar to how we looked into AMD's benchmarking numbers at their launch, we investigated Intel's newest benchmark numbers as well.
Enterprise & Cloud Benchmarks
Below you can find Intel's internal benchmarking numbers. The EPYC 7601 is the reference (performance=1), the 8160 is represented by the light blue bars, the top of the line 8180 numbers are dark blue. On a performance per dollar metric, it is the light blue worth observing.
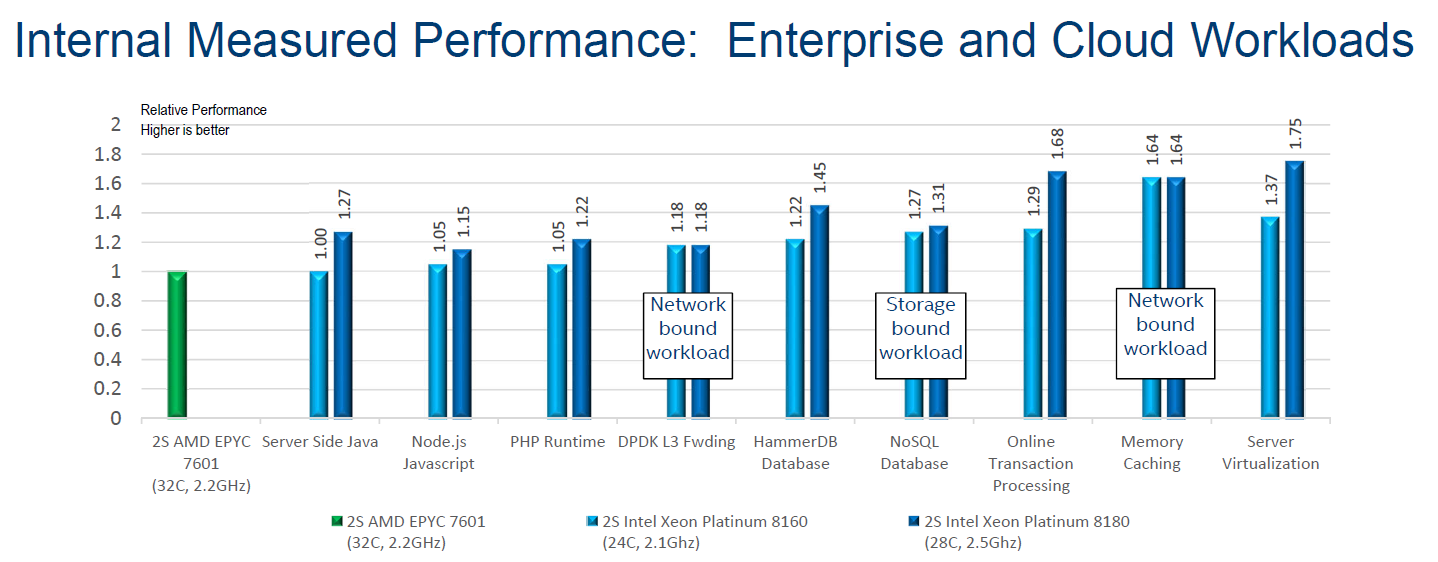
Java benchmarks are typically unrealistically tuned, so it is a sign on the wall when an experienced benchmark team is not capable to make the Intel 8160 shine: it is highly likely that the AMD 7601 is faster in real life.
The node.js and PHP runtime benchmarks are very different. Both are open source server frameworks to generate for example dynamic page content. Intel uses a client load generator to generate a real workload. In the case of the PHP runtime, MariaDB (MySQL derivative) 10.2.8 is the backend.
In the case of Node.js, mongo db is the database. A node.js server spawns many different single threaded processes, which is rather ideal for the AMD EPYC processor: all data is kept close to a certain core. These benchmarks are much harder to skew towards a certain CPU family. In fact, Intel's benchmarks seem to indicate that the AMD EPYC processors are pretty interesting alternatives. Surely if Intel can only show a 5% advantage with a 10% more expensive processor, chances are that they perform very much alike in the real world. In that case, AMD has a small but tangible performance per dollar advantage.
The DPDK layer 3 Network Packet Forwarding is what most of us know as routing IP packets. This benchmark is based upon Intel own Data Plane Developer Kit, so it is not a valid benchmark to use for an AMD/Intel comparison.
We'll discuss the database HammerDB, NoSQL and Transaction Processing workloads in a moment.
The second largest performance advantage has been recorded by Intel testing the distributed object caching layer memcached. As Intel notes, the benchmark was not a processing-intensive workload, but rather a network-bound workload. As AMD's dual socket system is seen as a virtual 8-socket system, due to the way that AMD has put four dies onto each processor and each die has a sub-set of PCIe lanes linked to it, AMD is likely at a disadvantage.
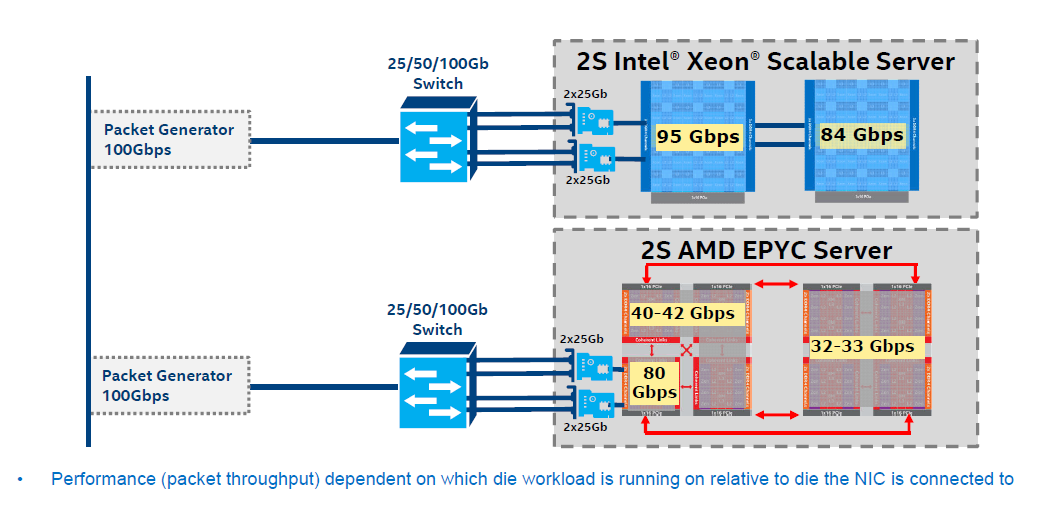
Intel's example of network bandwidth limitations in a pseudo-socket configuration
Suppose you have two NICs, which is very common. The data of the first NIC will, for example, arrive in NUMA node 1, Socket 1, only to be accessed by NUMA node 4, Socket 1. As a result, there is some additional latency incurred. In Intel's case, you can redirect a NIC to each socket. With AMD, this has to be locally programmed, to ensure that the packets that are sent to each NICs are processed on each virtual node, although this might incur additional slowdown.
The real question is whether you should bother to use a 2S system for Memached. After all, it is distributed cache layer that scales well over many nodes, so we would prefer a more compact 1S system anyway. In fact, AMD might have an advantage as in the real world, Memcached systems are more about RAM capacity than network or CPU bottlenecks. Missing the additional RAM-as-cache is much more dramatic than waiting a bit longer for a cache hit from another server.
The virtualization benchmark is the most impressive for the Intel CPUs: the 8160 shows a 37% performance improvement. We are willing to believe that all the virtualization improvements have found their way inside the ESXi kernel and that Intel's Xeon can deliver more performance. However, in most cases, most virtualization systems run out of DRAM before they run out of CPU processing power. The benchmarking scenario also has a big question mark, as in the footnotes to the slides Intel achieved this victory by placing 58 VMs on the Xeon 8160 setup versus 42 VMs on the EPYC 7601 setup. This is a highly odd approach to this benchmark.
Of course, the fact that the EPYC CPU has no track record is a disadvantage in the more conservative (VMware based) virtualization world anyway.
Database Performance & Variability
Results are very different with respect to transactional database benchmarks (HammerDB & OLTP). Intel's 8160 has an advantage of 22 to 29%, which is very similar to what we saw in our own independent benchmarking.

One of the main reasons is data locality: data is distributed over the many NUMA nodes causing extra latency for data access. Especially when data is locked, this can cause performance degradation.

Intel measured this with their own Memory Latency Checker (version 3.4), but you do not have rely on Intel alone. AMD reported similar results on the Linley Processor conference, and we saw similar results too.
There is more: Intel's engineers noticed quite a bit of performance variation between different runs.
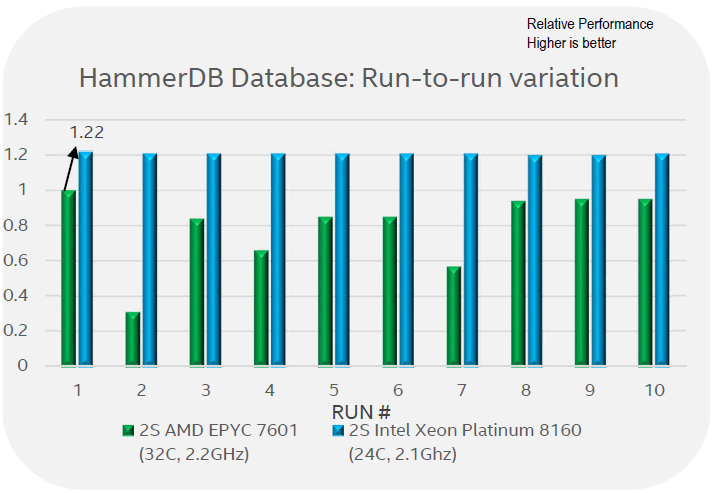
Intel engineers claim that what they reported in the first graph on this page is, in fact, the best of 10 runs. Between the 10 runs, it is claimed there was a lot of variability: ignoring the outlier number 2, there are several occasions where performance was around 60% of the best reported value. Although we can not confirm that the performance of the EPYC system varies precisely that much, we have definitely seen more variation in our EPYC benchmarks than on a comparable Intel system.
HPC Benchmarks
Discussing HPC benchmarks feels always like opening a can of worms to me. Each benchmark requires a thorough understanding of the software and performance can be tuned massively by using the right compiler settings. And to make matters worse: in many cases, these workloads can be run much faster on a GPU or MIC, making CPU benchmarking in some situations irrelevant.
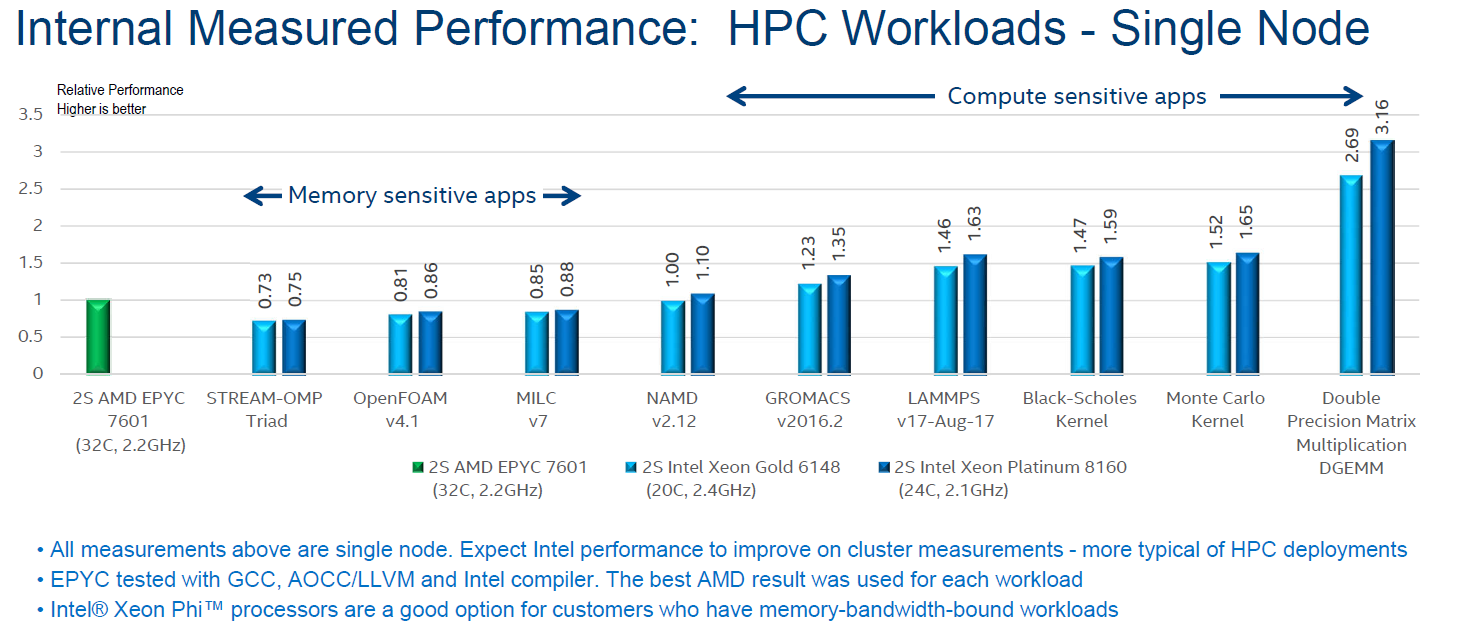
NAMD (NAnoscale Molecular Dynamics) is a molecular dynamics application designed for high-performance simulation of large biomolecular systems. It is rather memory bandwidth limited, as even with the advantage of an AVX-512 binary, the Xeon 8160 does not defeat the AVX2-equipped AMD EPYC 7601.
LAMMPS is classical molecular dynamics code, and an acronym for Large-scale Atomic/Molecular Massively Parallel Simulator. GROMACS (for GROningen MAchine for Chemical Simulations) primarily does simulations for biochemical molecules (bonded interactions). Intel compiled the AMD version with the Intel compiler and AVX2. The Intel machines were running AVX-512 binaries.
For these three tests, the CPU benchmarks results do not really matter. NAMD runs about 8 times faster on an NVIDIA P100. LAMMPS and GROMACS run about 3 times faster on a GPU, and also scale out with multiple GPUs.
Monte Carlo is a numerical method that uses statistical sampling techniques to approximate solutions to quantitative problems. In finance, Monte Carlo algorithms are used to evaluate complex instruments, portfolios, and investments. This is a compute bound, double precision workload that does not run faster on a GPU than on Intel's AVX-512 capable Xeons. In fact, as far as we know the best dual socket Xeons are quite a bit faster than the P100 based Tesla. Some of these tests are also FP latency sensitive.
Black-Scholes is another popular mathematical model used in finance. As this benchmark is also double precision, the dual socket Xeons should be quite competitive compared to GPUs.
So only the Monte Carlo and Black Scholes are really relevant, showing that AVX-512 binaries give the Intel Xeons the edge in a limited number of HPC applications. In most HPC cases, it is probably better to buy a much more affordable CPU and to add a GPU or even a MIC.
The Caveats
Intel drops three big caveats when reporting these numbers, as shown in the bullet points at the bottom of the slide.
Firstly is that these are single node measurements: One 32-core EPYC vs 20/24-core Intel processors. Both of these CPUs, the Gold 6148 and the Platinum 8160, are in the ball-park pricing of the EPYC. This is different to the 8160/8180 numbers that Intel has provided throughout the rest of the benchmarking numbers.
The second is the compiler situation: in each benchmark, Intel used the Intel compiler for Intel CPUs, but compiled the AMD code on GCC, LLVM and the Intel compiler, choosing the best result. Because Intel is going for peak hardware performance, there is no obvious need for Intel to ensure compiler parity here. Compiler choice, as always, can have a substantial effect on a real-world HPC can of worms.
The third caveat is that Intel even admits that in some of these tests, they have different products oriented to these workloads because they offer faster memory. But as we point out on most tests, GPUs also work well here.
Conclusion
First of all, Intel's benchmarks lend further support to what we already suspected: Intel's Scalable Xeon is better at serving databases for a number of reasons: better data locality (fewer NUMA nodes), better single-threaded performance, and a more "useable" cache. The claim that Intel offers much more predictable database performance seems very reasonable to us: the EPYC platform is much younger and much more complex to tune as it is a "virtual 8 socket" system.
Secondly it is true that the Intel Scalable Xeon is more versatile: the past 5 years AMD's presence in the server market was neglible, while Intel has been steadily adding virtualization features (posted interrupts), I/O features and more (TSX for example). Many of these features are now supported by the hypervisor and OSes out there.

The EPYC platform has some catching up to do. Firmware updates and other software updates were necessary to run a hypervisor, and only relatively recent versions of the Linux kernel (February 2017 w/4.10+) have support for the EPYC processor. So even if we doubt that the 8160 can really deliver 37% better performance than the AMD EPYC in the real world, there is no denying that the Intel Xeon is a "safer bet" for VMware virtualization.
Nevertheless, it is interesting to see that Intel admits that there are quite a few use cases out there where AMD has an advantage. The AMD EPYC has a performance per dollar advantage in webserving and Java servers, for example.
Otherwise, there is some merit to the claim that AVX-512 allows Intel to offer excellent HPC performance without the use of a GPU in compute intensive applications. At the same time, if you are after the best performance on these very parallel workloads, a GPU almost always offers several times higher performance. AVX-512 can also not save Intel in several bandwidth-intensive benchmarks such, as in fluid dynamics.

Intel Xeon-SP CPUs (Left: with Omni-Path)
One interesting element to the whole scenario is that at no point does Intel ever approach the performance per watt angle in these discussions. It leaves a big question unanswered from Intel - perhaps we should invoke Hanlon's Razor at this point and call it a missed opportunity, rather than suggest that Intel does not want to speak about power. Our own results showed a win for AMD's EPYC here though, when comparing two 145W Xeon 8176 parts to two 180W EPYC 7601 parts. More testing on specific workloads is needed.
In summary, Intel makes several good points, even when those points aren't always in their own favor. The company clearly has an interest in ensuring that the Xeon's performance leadership remains well-known in light of AMD's EPYC-fueled resurgence, and while there's nothing altruistic about Intel's benchmarking, they are working from a sound position. Still, in defending their position – and by extension their high margins – Intel does highlight the Xeon's biggest weakness versus the EPYC in this newly competitive market: the Skylake Xeon can offer excellent performance, but that performance comes with an equally heavy price tag.












