Original Link: https://www.anandtech.com/show/10353/investigating-cavium-thunderx-48-arm-cores
Investigating Cavium's ThunderX: The First ARM Server SoC With Ambition
by Johan De Gelas on June 15, 2016 8:00 AM EST- Posted in
- IT Computing
- Enterprise
- SoCs
- Enterprise CPUs
- Microserver
- Cavium

When is a worthy alternative to Intel's Xeon finally going to appear? That is the burning question in the server world. If PowerPoint presentations from various ARM-based SoCs designers released earlier this decade were to be believed, Intel would now be fighting desperately to keep a foothold in the low end server market. But the ARM SoCs so far have always disappointed: the Opteron A1100 was too late, the X-Gene 1 performed poorly, consumed too much power, and Broadcomm's Vulcan project is most likely dead. This Ubuntu page is an excellent illustration of the current state of the ARM server market:
Discontinued products, many announced products which do not even appear on this page (we are in the middle of 2016, after all), and despite the fact that there is an ARM Server Base System Architecture (SBSA) specification, every vendor has its own installation procedure. It is still a somewhat chaotic scene.
Meanwhile, Intel listened to their "hyperscaler customers" (Facebook, Google...) and delivered the Xeon D. We reviewed Intel's Broadwell SoC and we had to conclude that this was one of the best products that Intel made in years. It is set a new performance per watt standard and integrated a lot of I/O. The market agreed: Facebook's new web farms were built upon this new platform, ARM servers SoCs were only successful in the (low end) storage server world. To make matter worse, Intel expanded the Xeon D line with even higher performing 12 and 16 core models.
But losing a battle does not mean you lose the war. Finally, we have a working and available ARM server SoC which has more ambition than beating the old Atom C2000 SoC. In fact, Cavium's ThunderX SoC has been shipping since last year, but you need more than silicon to get a fully working server. Firmware and kernel need to get along, and most libraries need to be compiled with platform-specific optimizations. So the quality assurance teams had a lot of work to do before Cavium could ship a server that could actually run some server software in a production environment. But that work has finally been finished. Cavium send us the Gigabyte R120-T30 running Ubuntu 14.04 server with a ThunderX ready Linux kernel (4.2.0) and ThunderX optimized tools (gcc 5.2.0 etc.).
Cavium?
Who is Cavium anyway? Even for those working in the enterprise IT, it is not a well known semiconductor company. Still, Cavium has proven itself as fabless network/security/storage and video SoC designing company. The company based in San José counts IBM, Juniper, Qualcomm, Netgear, Cisco among its customers.
With a net revenue of about $400 million, Cavium is about one-tenth the size of AMD. But then again, Cavium either reports small losses or smal profits despite heavy investments in the new ARMv8 project ThunderX. In other words, the company's financials look healthy. And Cavium did already design a 16-core MIPS64 Octeon Network Service Processor (NSP) back in 2006. So Cavium does have a lot of experience with high core count SoCs: the network processor Octeon III CN78xx has 48 of them.
Handling server applications is of course very different from network processing. A large amount of independent network packets creates a lot of parallelism, and more complex computation can be offloaded to co-processors. Still, Cavium is the first vendor that delivers an ARMv8 server chip with an impressive core count: no less than 48 cores can be found inside the ThunderX die.
To keep the design effort reasonable, Cavium based their first ARMv8 server processor, ThunderX, on the Octeon III CN78xx. We described this in more detail here, but the main trade-off is that Cavium used a relatively simple dual issue core. As a result, single threaded performance is expected to be relatively low. On the opposite side of the coin however, it is the first ARM SoC that has claimed throughput numbers in the realm of the best Xeon D and even midrange Xeon E5, instead of competing with the Atom C2000. It is the most ambitious ARMv8 SoC that has made it into production.
All of this gives us plenty of reasons to put the Cavium ThunderX through paces. And throwing in the latest Supermicro boards with the latest 12 and 16 core Xeon-Ds made it a lot more interesting ...
The ThunderX SoCs
Below you can see all the building blocks that Cavium has used to build the ThunderX.
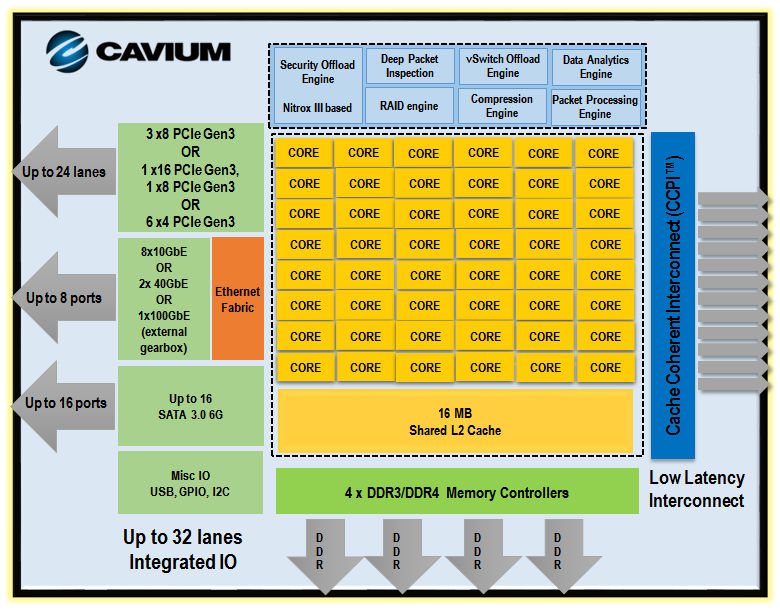
Depending on the target market, some of these building blocks are removed to reduce power consumption or to increase the clockspeed. The "Cloud Compute" version (ThunderX_CP) that we're reviewing today has only one accelerator (vSwitch offload) and 4 SATA ports (out of 16), and no Ethernet fabric.

ThunderX_CP
But even the compute version can still offer an 8 integrated 10 Gbit Ethernet interfaces, which is something you simply don't see in the "affordable" server world. For comparison, the Xeon D has two 10 Gbit interfaces.
The storage version (_ST) of the same chip has more co-processors, more SATA ports (16) and an integrated Ethernet fabric. But the ThunderX_ST cuts back on the number of PCIe lanes and might not reach the same clockspeeds.
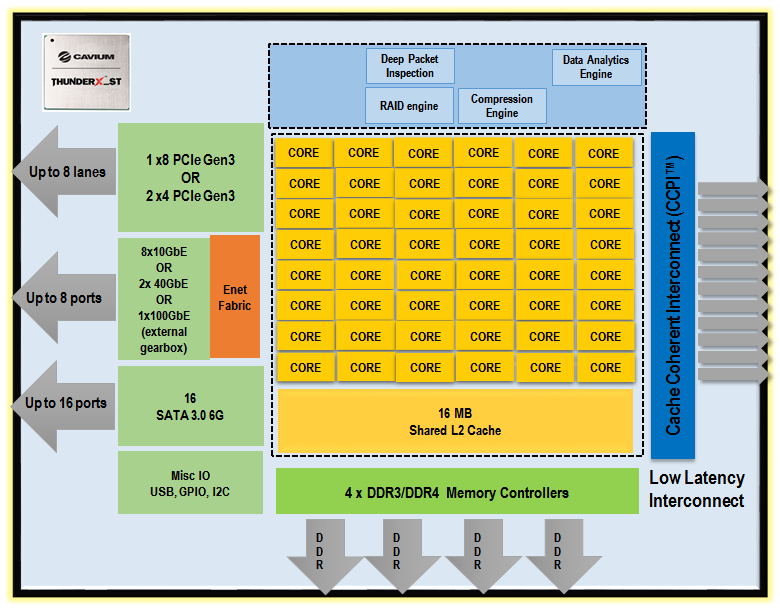
ThunderX_ST
There is also a secure compute version with IP Sec/SSL accelerators (_SC) and network/telco version (_NT). In total there are 4 variants of the same SoC. But in this article, we focus on the version we were able to test: the CP or Cloud Compute.
Xeon D vs ThunderX: Supermicro vs Gigabyte
While SoC is literally stands for a system on a chip, in practice it's still just one component of a whole server. A new SoC cannot make it to the market alone; it needs the backing of server vendors to provide the rest of the hardware to go around it and to make it a complete system.
To that end, Gigabyte has adopted Cavium's ThunderX in quite a few different servers. Meanwhile on the Intel side, Supermicro is the company with the widest range of Xeon D products. 
There are other server vendors like Pengiun computing and Wistrom that will make use of the ThunderX, and you'll find Xeon D system from over a dozen vendors. But is clear that Gigabyte and Supermicro are the vendors that make the ThunderX and Xeon D available to the widest range of companies respectively.
For today's review we got access to the Gigabyte R120-T30.

Although density is important, we can not say that we are a fan of 1U servers. The small fans in those systems tend to waste a lot of energy.

Eight DIMMs allow the ThunderX SoC to offer up to 512 GB, but realistically 256 GB is probably the maximum practical capacity (8 x 32 GB) in 2016. Still, that is twice as much as the Xeon D, which can be an advantage in caching or big data servers. Of course, Cavium is the intelligent network company, and that is where this server really distinguishes itself. One Quad Small Form-factor Pluggable Plus (QFSP+) link can deliver 40 GB/s, and combined with four 10 Gb/s Small Form-factor Pluggable Plus (SFP+) links, a complete ThunderX system is good for a total of 80 Gbit per second of network bandwidth.

Along with building in an extensive amount of dedicated network I/O, Cavium has also outfit the ThunderX with a large number of SATA host ports, 16 in total. This allows you to use the 3 PCIe 3.0 x8 links for purposes other than storage or network I/O.
That said, the 1U chassis used by the R120-T30 is somewhat at odds with the capabilities of ThunderX here: there are 16 SATA ports, but only 4 hotswap bays are available. Big Data platforms make use of HDFS, and with a typical replication of 3 (each block is copied 3 times) and performance that scales well with the number of disks (and not latency), many people are searching for a system with lots of disk bays.
Finally, we're happy to report that there is no lack of monitoring and remote management capabilities. A Serial port is available for low level debugging and an AST2400 with an out of band gigabit Ethernet port allows you to manage the server from a distance.
Supermicro's Xeon D Solution: X10SDV-12C-TLN4F
The top tier server vendors seem to offer very few Xeon D based servers. For example, there is still no Xeon D server among the HP Moonshot cartridges as far as we know. Supermicro, on the other hand, has an extensive line of Xeon D motherboards and servers, and is basically the vendor that has made the Xeon D accessible to those of us that do not work at Facebook or Google.
The first board we were able to test was the mini-ITX X10SDV-12C-TLN4F. It is a reasonably priced ($1200) model, in the range what the Gigabyte board and Cavium CN8880 -2.0 will cost (+/- $1100).

The Xeon D makes six SATA3 ports and two 10GBase available on this board. An additional i350-AM2 chip offers 2 gigabit Ethernet ports. The board has one PCI-e 3.0 x16 slot for further expansion. We have been testing this board 24/7 for almost 3 months now. We have tried out the different Ethernet ports and different DDR-4 DIMMS: it is a trouble-free.
The one disadvantage of all Supermicro boards remains their Java-based remote management system. It is a hassle to get it working securely (Java security is a user unfriendly mess), and it lacks some features like booting into the BIOS configuration system, which saves time. Furthermore video is sometimes not available, for example we got a black screen when a faulty network configuration caused the Linux bootup procedure to wait for a long time. Remote management solutions from HP and Intel offer better remote consoles.
The Top of the Line Xeon D: 16 Cores At 2.3 GHz
The Xeon D-1557 is a Xeon D with 12 cores running at 1.8 GHz most of the time (1.5 GHz base clock) that can boost to 2.1 GHz in single threaded circumstances. The reason for the modest clockspeed is simply the relatively low 45W TDP.
So if you need more CPU compute power, Intel has recently launched the Xeon D-1581, which contains 16 cores (32 threads) which can run at 2.3 GHz most of the time (1.8 GHz base), and boosts to 2.4 GHz. It does not seem to be available to everybody quite yet, but it is simply the slightly more powerful version of the earlier 1587, which runs one speed grade slower (1.7-2.3 GHz). Intel has not disclosed pricing yet, but it is not too hard to figure out. The Xeon D-1587 costs a daunting $1754, so it is very likely that the slightly faster Xeon D-1581 is around $1850.

To make the Xeon D-1581 equipped Supermicro X10SDV-7TP8F attractive, Supermicro turned it into a very luxurious board. They added the LSI 2116 RoC chip which adds up to 16 SATA3/SAS2 ports, and an Intel i350-AM4 (4 extra gigabit ports) and an Intel I210 (2 extra gigabit ports). So in total you can attach 4x SATA disks, 16x SAS disks, 6x GigE and 2x 10 GbE connections. Although we are impressed with the I/O capabilities, we feel that the Ethernet configuration is a bit too much of a good thing. If you configured something wrong, the fact that 3 different NIC chips are present makes debugging it harder. Nevertheless, it is an interesting alternative for a large part of the server market that does not need a 2 socket Xeon E5 but still needs a lot of local I/O.
ThunderX SKUs: What is Cavium Offering Today?
Cavium has been promising SKUs with 16 cores or 48 cores, with clockspeed ranges between 1.8 GHz and 2.5 GHz, with a TDP of up to 95W. While I am typing this article, Cavium has not published a full spec list of the different SKUs and the real silicon is different from the paper specs. So we will simply jot down what we do know.
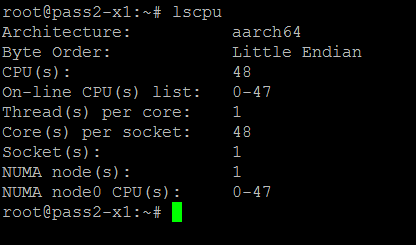
The SKU we tested was the ThunderX-CP CN88xx 2 GHz. It is hard to identify the CPU as the usual Linux CPU identification tools do not tell us anything. Only the BIOS can gave some info:
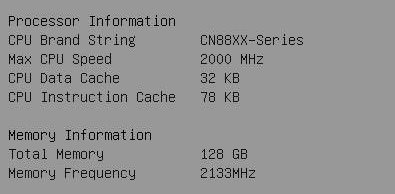
The SKU we tested (CN8890), has 48 cores at 2 GHz, inside a TDP of 120W and costs around $800. This is the SKU that is being produced at mass scale.
What we know so far:
- SKUs available with Clockspeeds of 1.6 GHz and 1.8 GHz with lower TDPs than 120W (2 GHz)
- Highest clock is 2 GHz
- SKUs with 24, 32, and 48 cores
- Available in all families (Cloud, Storage, Security, Networking) and currently in productions
TDP ranges from 65W (low end, 24 cores at 1.8 GHz ?) to 135W (probably a 48-core SKU at 2 GHz with most features turned on).
But it is safe to say that Cavium missed the target of 48-cores at 2.5 GHz inside a 95W power envelope. That probably was too optimistic, given the fact that the chip is baked with a relatively old 28 nm high-k metal-gate process at GlobalFoundries.
The Small Cavium ARM Core
Cavium has not talked much about ThunderX's internals. But since the launch of the Octeon back in 2006, Cavium has continued to build further upon this microarchitecture. Given the similarities in specifications and what we have read and heard so far about the ThunderX, it is safe to assume that the internal architecture of ThunderX is an improved version of the Octeon III.
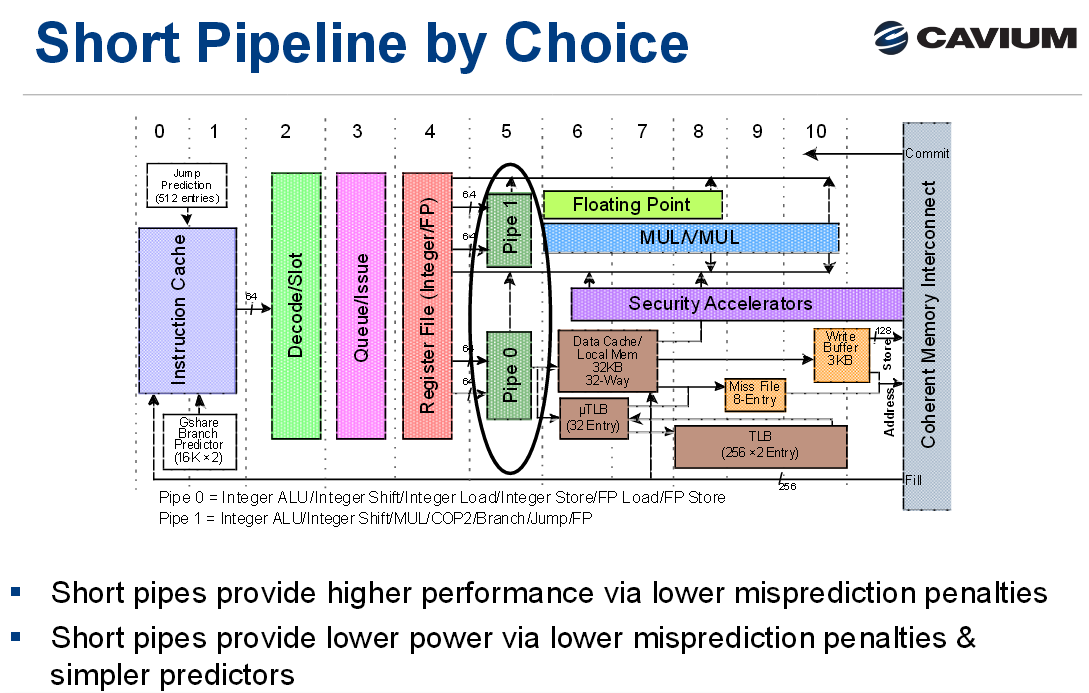
The Cavium core can probably only sustain 2 instructions per clock, with a very simple 4 issue back-end. To put this in perspective: Intel's latest "Broadwell/Skylake" designs can sustain 5-6 instructions per clock and issue up to 8 integer instructions (load/store included). While we are not sure whether there have not been significant changes to the backend, the basic pipeline has remained the same (9 cycles instead of 8). That means that the design might do well in branch intensive low IPC situations, which are very common in lots of server applications. But the consequence is also that it is very unlikely that the Cavium will be able to reach the turbo speeds that the Xeons reach (3.5 GHz and more).
To that end we'll test this in great detail: is the Cavium ThunderX core more like an ARM Cortex-A53, or is it a bit more muscular?
Selecting the Competition
In setting up our benchmarks, we chose four different Intel SKUs to compete with the Cavium ThunderX. Our choices are not ideal (as we only have a limited number of SKUs available) but there is still some logic behind the SKU choice.
The Xeon E5-2640 v4 (10 cores @2.4 GHz, $939) has Intel's latest server core (Broadwell EP) and features a price tag in the ballpark of the ThunderX ($800) along with a low 90W TDP.
The Xeon E5-2690 v3 (12 cores @2.6 GHz, $2090) is a less optimal choice, but we wanted an SKU with a higher TDP, in case that the actual power consumption of the Thunder-X is higher than what can be expected from the official 120W TDP. To be frank, it was the only SKU that was faster than the E5-2640 v4 that we had. The Xeon E5-2699v4 ($4115, 145W TDP) did not make much sense to us in this comparison... so we settled for the Xeon E5-2690v3.
And then we added all the Xeon Ds we had available. At first sight it's not fair to compare a 45W TDP SoC to our 120W ThunderX. But the Xeon D-1557 is in the same price range as the Cavium ThunderX, and is targeted more or less at the same market. And although they offer fewer network and SATA interfaces, Cavium has to beat these kind of Xeon Ds performance wise, otherwise Intel's performance per watt advantage will steal Cavium's thunder.
The Xeon D-1581 is the most expensive Xeon D, but it is Intel's current server SoC flagship. But if the ARM Server SoCs start beating competitively priced Xeon Ds, Intel can always throw this one in the fray with a lower price. It is the SoC the ARM server vendors have to watch.
Configuration
Most of our testing was conducted on Ubuntu Server 14.04 LTS. We did upgrade this distribution to the latest release (14.04.4), which gives us more extensive hardware support. However, to ensure support for the ThunderX, the gcc compiler was upgraded to 5.2. In case of the ThunderX, the kernel was also 4.2.0, while the Intel systems still used kernel 3.19.
The reason why we did not upgrade the kernel is simply that we know from experience that this can generate all kinds of problems. In the case of the ThunderX using a newer kernel was necessary, while for the Intel CPUs we simply checked that there were no big differences with the new Ubuntu 16.04. The only difference that we could see there is that some of our software now does not compile on 16.04 (Sysbench, Perlbench). As we already waste a lot of time with debugging all kinds of dependency trouble, we kept it simple.
Gigabyte R120-T30 (1U)
The full specs of the server can be found here.
| CPU | One ThunderX CN8890 |
| RAM | 128GB (4x32GB) DDR4-2133 |
| Internal Disks | 2x SanDisk CloudSpeed Ultra 800GB |
| Motherboard | Gigabyte MT30-GS0 |
| BIOS version | 1/28/2016 |
| PSU | Delta Electronics 400w 80 Plus Gold |
Supermicro X10SDV-7TP8F and X10SDV-12C-TLN4F (2U case)
| CPU | Xeon D-1557 (1.5 GHz, 12 cores, 45 W TDP) Xeon D-1581 (1.8 GHz, 16 cores, 65 W TDP) |
| RAM | 64 GB (4x16 GB) DDR4-2133 |
| Internal Disks | 2x Intel SSD3500 400GB |
| Motherboard | Supermicro X10SDV-7TP8F Supermicro X10SDV-12C-TLN4F |
| BIOS version | 5/5/2016 |
| PSU | Delta Electronics 400w 80 Plus Gold |
Hyperthreading, Turbo Boost, C1 and C6 were enabled in the BIOS.
Intel's Xeon E5 Server – S2600WT (2U Chassis)
This is the same server that we used in our latest Xeon v4 review.
| CPU | Xeon E5-2640 v4 (2.4 GHz, 10 cores, 90 W TDP) Xeon E5-2690 v3 (2.6 GHz, 12 cores, 135 W TDP) |
| RAM | 128GB (8x16GB) Kingston DDR-2400 |
| Internal Disks | 2x Intel SSD3500 400GB |
| Motherboard | Intel Server Board Wildcat Pass |
| BIOS version | 1/28/2016 |
| PSU | Delta Electronics 750W DPS-750XB A (80+ Platinum) |
Hyperthreading, Turboost, C1 and C6 were enabled in the BIOS.
Other Notes
All servers are fed by a standard European 230V (16 Amps max.) power line. The room temperature is monitored and kept at 23°C by our Airwell CRACs in our Sizing Servers Lab.
Memory Subsystem: Bandwidth
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array size which are not cacheable by the Xeon's huge L3-caches nowadays.
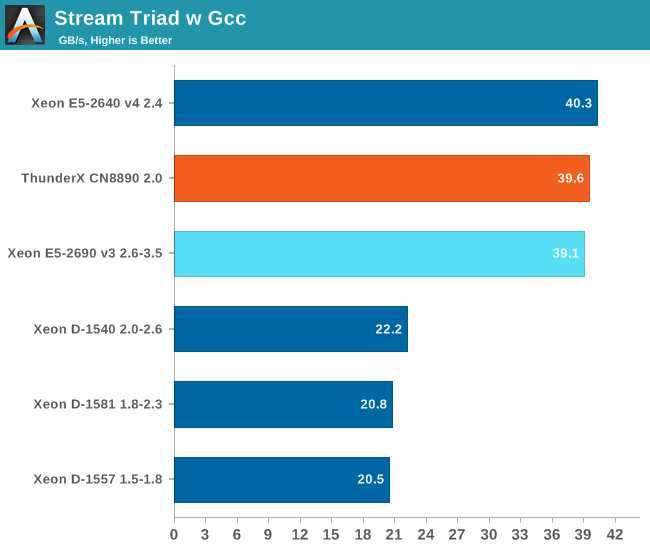
The ThunderX keeps up with the midrange Xeon E5s. The relatively low numbers might surprise a lot of people, as Stream benchmarks now hit 100 GB/s and beyond easily these days. First of all, these are of course single socket measurements, as opposed to the typical dual socket stream tests. Secondly, only the "high-end" and "segment optimized" Intel SKUs support DDR-2400, many SKUs are "limited" to DDR4-2133. With DDR4-2400, Xeon E5's score would increase to 48 GB/s per socket.
Last but not least: we do not use the icc compiler. Using the icc compiler boosts the performance of this benchmark by 33% (to 64 GB/s). That raw bandwidth is most likely only useful in some AVX-optimized HPC applications, a market that the ThunderX does not target. So far, so good: the ThunderX memory controller delivers twice as much bandwidth as Intel's Xeon D SoC. It is the first time the Xeon D gets beaten by an ARM v8 SoC...
Memory Subsystem: Latency Measurements
There is no doubt about it: the performance of modern CPUs depends heavily on the cache subsystem, and some application depend heavily on the DRAM subsystem too. Since the ThunderX is a totally new architecture, we decided to invest some time to understand the cache system. We used LMBench and Tinymembench in an effort to try to measure the latency.
The numbers we looked at were "Random load latency stride=16 Bytes" (LMBench). Tinymembench was compiled with -O2 on each server. We looked at both "single random read" and "dual random read".
LMbench offers a test of L1, while Tinymembench does not. So the L1-readings are measured with LMBench. LMbench consistently measured 20-30% higher latency for L2, L3 cache, and 10% higher readings for memory latency. Since Tinymembench allowed us to compare both latency with one (1 req in the table) or two outstanding requests (2 req in the table), we used the numbers measured by Tinymembench.
| Mem Hierarchy |
Cavium ThunderX 2.0 DDR4-2133 |
Intel Xeon D DDR4-2133 |
Intel Broadwell Xeon E5-2640v4 DDR4-2133 |
Intel Broadwell Xeon E5-2699v4 DDR4-2400 |
| L1-cache (cycles) | 3 | 4 | 4 | 4 |
| L2-cache 1 / 2 req (cycles) | 40/80 | 12 | 12 | 12 |
| L3-cache 1 / 2 req (cycles) | N/A | 40/44 | 38/43 | 48/57 |
| Memory 1 / 2 req (ns) | 103/206 | 64/80 | 66/81 | 57/75 |
The ThunderX's shallow pipeline and relatively modest OOO capabilities is best served with a low latency L1-cache, and Cavium does not disappoint with a 3 cycle L1. Intel's L1 needs a cycle more, but considering that the Broadwell core has massive OOO buffers, this is not a problem at all.
But then things get really interesting. The L1-cache of the ThunderX does not seem to support multiple outstanding L1 misses. As a result, a second cache miss needs to wait until the first one was handled. Things get ugly when accessing the memory: not only is the latency of accessing the DDR4-2133 much higher, again the second miss needs to wait for the first one. So a second cache miss results in twice as much latency.
The Intel cores do not have this problem, a second request gets only a 20 to 30% higher latency.
So how bad is this? The more complex the core gets, the more important a non-blocking cache gets. The 5/6 wide Intel cores need this badly, as running many instructions in parallel, prefetching data, and SMT all increase the pressure on the cache system, and increase the chance of getting multiple cache misses at once.
The simpler two way issue ThunderX core is probably less hampered by a blocking cache, but it still a disadvantage. And this is something the Cavium engineers will need to fix if they want to build a more potent core and achieve better single threaded performance. This also means that it is very likely that there is no hardware prefetcher present: otherwise the prefetcher would get in the way of the normal memory accesses.
And there is no doubt that the performance of applications with big datasets will suffer. The same is true for applications that require a lot of data synchronization. To be more specific we do not think the 48 cores will scale well when handling transactional databases (too much pressure on the L2) or fluid dynamics (high latency memory) applications.
Benchmarks Versus Reality
Ever run into the problem that your manager wants a clear and short answer, while the real story has lots of nuances? (ed: and hence AnandTech) The short but inaccurate answer almost always wins. It is human nature to ignore complex stories and to prefer easy to grasp answers. The graph below is a perfect illustration of that. Although this one has been produced by Intel, almost everybody in the industry, including the ARM SoC companies, love the simplicity it affords in describing the competitive situation.
The graph compares the ICC compiled & published results for SPECint_rate_base2006 with some of the claimed (gcc compiled?) results of the ARM server SoC vendors.
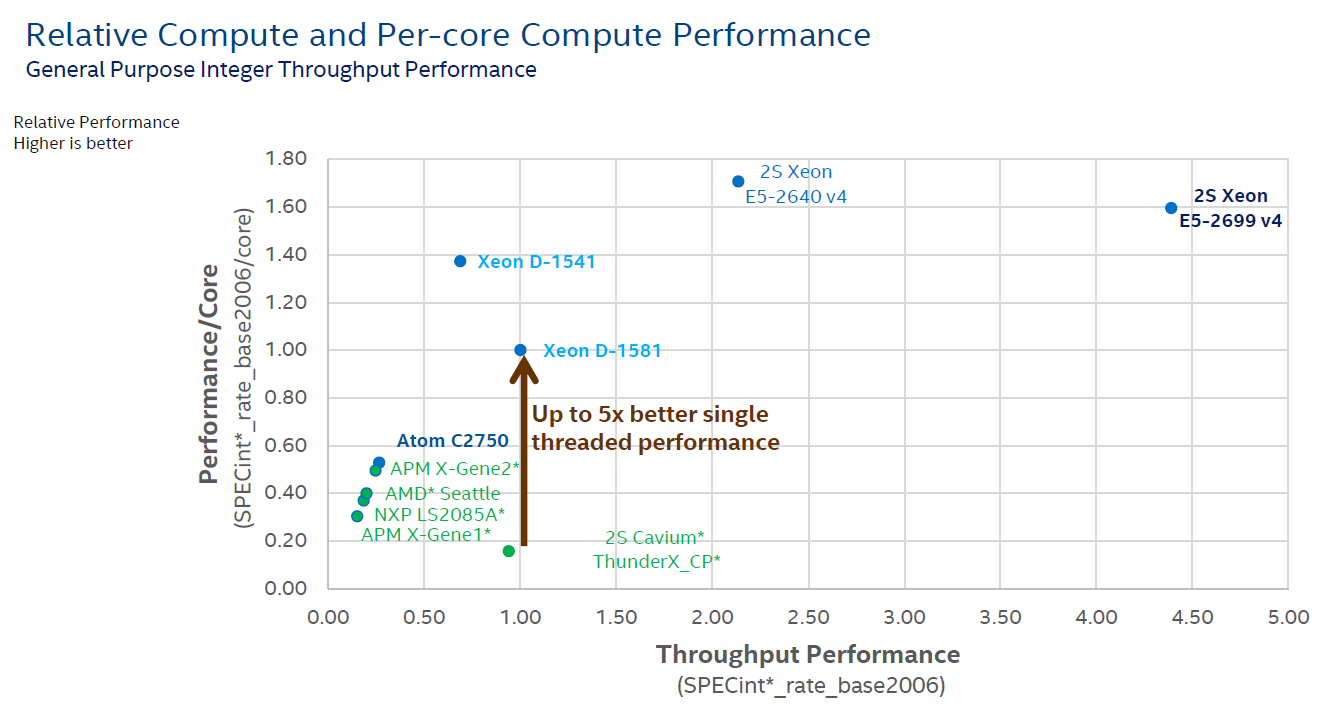
The graph shows two important performance vectors: throughput and single core performance. The former (X-axis) is self-explanatory, the latter (Y-axis) should give an indication of response times (latency). The two combined (x, y coordinate) should give you an idea on how the SoC/CPU performs in most applications that are not perfectly parallel. It is a very elegant way to give a short and crystal clear answer to anyone with a technical or scientific background.
But there are many drawbacks. The main problem is "single core performance". Since this is just diving the score by the number of cores, this favors the CPUs with some form of hardware multi-threading. But in many cases, the extra threads only help with throughput and not with latency. For example, if there are a few heavy SQL requests that keep you waiting, adding threads to a core does not help at all, on the contrary. So the graph above gives a 20% advantage to the SMT capable cores of Intel on y-axis, while hyperthreading is most of the time a feature that boosts throughput.
Secondly, dividing throughput by the number of cores means also that you favor the architectures that are able to run many instances of SPECint. In other words, it is all about memory bandwidth and cache size. So if a CPU does not scale well, the graph will show a lower per core performance. So basically this kind of graph creates the illusion of showing two performance parameters (throughput and latency), but it is in fact showing throughput and something that is more related to throughput (throughput normalized per core?) than latency. And of course, SPECint_rate is only a very inaccurate proxy for server compute performance: IPC is higher than in most server applications and there is too much emphasis on cache size and memory bandwidth. Running 32 parallel instances of an application is totally different from running one application with 32 threads.
This is definitely not written to defend or attack any vendor: many vendors publish and abuse these kind of graphs to make their point. Our point is that it is very likely that this kind of graph gives you a very inaccurate and incomplete view of the competition.
But as the saying goes, the proof is in the pudding, so let's put together a framework for comparing these high level overviews with real world testing. First step, let's pretend the graph above is accurate. So the Cavium ThunderX has absolutely terrible single threaded performance: one-fifth that of the best Xeon D, not even close to any of the other ARM SoCs. A ThunderX core cannot even deliver half the performance of an ARM Cortex-A57 core (+/- 10 points per core), which is worse than the humble Cortex-A53. It does not get any better: the throughput of a single ThunderX SoC is less than half of the Xeon D-1581. The single threaded performance of the Xeon D-1581 is only 57% of the Xeon E5-2640's and it cannot compete with the throughput of even a single Xeon E5-2640 (2S = 2.2 times the Xeon-D 1581).
Second step, do some testing instead of believing vendor claims or published results from SPEC CPU2006. Third step, compare the graph above with our test results...
Single-Threaded Integer Performance: SPEC CPU2006
Even though SPEC CPU2006 is more HPC and workstation oriented, it contains a good variety of integer workloads. Running SPEC CPU2006 is a good way to evaluate single threaded (or core) performance. The main problem is that the results submitted are "overengineered" and it is very hard to make any fair comparisons.
So we wanted to keep the settings as "real world" as possible. We welcome constructive criticism to reach that goal. So we used:
- 64 bit gcc: most used compiler on Linux, good all round compiler that does not try to "break" benchmarks (libquantum...)
- -Ofast: compiler optimization that many developers may use
- -fno-strict-aliasing: necessary to compile some of the subtests
- base run: every subtest is compiled in the same way.
The ultimate objective is to measure performance in applications where for some reason – as is frequently the case – a "multi thread unfriendly" task keeps us waiting.
Nobody expect the ThunderX to be a single threaded performance wonder. Cavium clearly stated that they deliberately went for a high core count with pretty simple cores. As a result, single threaded performance was not a priority.
However, Facebook and other hyperscalers have indicated that they definitely prefer to get the single threaded performance of a Xeon D. So any competitor challenging Intel should try to keep up with the Xeon D in single threaded performance and offer a throughput-per-dollar/watt bonus. So it is very interesting to measure what single threaded performance the current ThunderX can offer.
| Subtest SPEC CPU2006 Integer |
Application Type | Cavium ThunderX 2 GHz |
Xeon D-1557 1.5-2.1 |
Xeon D-1587 1.8-2.4 |
Xeon E5-2640 v4 2.4-2.6 |
Xeon E5-2690 v3 2.6-3.5 |
Xeon E5-2699 v4 2.2-3.6 |
Xeon E5-2699 v4 2.2-3.6 (+HT) |
| 400.perlbench | Spam filter | 8.3 | 24.7 | 29 | 33.4 | 39 | 32.2 | 36.6 |
| 401.bzip2 | Compression | 6.5 | 15.1 | 17.2 | 19.8 | 24.2 | 19.2 | 25.3 |
| 403.gcc | Compiling | 10.8 | 23.1 | 27.2 | 30 | 37.2 | 28.9 | 33.3 |
| 429.mcf | Vehicle scheduling | 10.2 | 32.6 | 38.4 | 40.4 | 44.8 | 39 | 43.9 |
| 445.gobmk | Game AI | 9.2 | 17.4 | 20.2 | 22.7 | 28.1 | 22.4 | 27.7 |
| 456.hmmer | Protein seq. analyses | 4.8 | 19 | 21.7 | 25.1 | 28 | 24.2 | 28.4 |
| 458.sjeng | Chess | 8.8 | 19.8 | 22.8 | 25.6 | 31.5 | 24.8 | 28.3 |
| 462.libquantum | Quantum sim | 5.8 | 47.9 | 58.2 | 60.3 | 78 | 59.2 | 67.3 |
| 464.h264ref | Video encoding | 11.9 | 32 | 36.6 | 41.9 | 56 | 40.7 | 40.7 |
| 471.omnetpp | Network sim | 7 | 17.3 | 23 | 23.6 | 30.9 | 23.5 | 29.9 |
| 473.astar | Pathfinding | 7.9 | 14.7 | 17.2 | 19.8 | 24.4 | 18.9 | 23.6 |
| 483.xalancbmk | XML processing | 8.4 | 27.8 | 33.3 | 36.2 | 45.1 | 35.4 | 41.8 |
Although some of you have a mathematical mind and are able to easily decipher these kinds of tables, let the rest of us be lazy and translate this into percentages. We make the Xeon D-1581 the baseline. The Xeon D-1557's performance is more or less the single threaded performance some of the important customers such as Facebook like to have.
| Subtest SPEC CPU2006 Integer |
Application Type | Cavium ThunderX 2 GHz |
Xeon D-1557 1.5-2.1 |
Xeon D-1581 1.5-2.1 |
Xeon E5-2640 2.4-2.6 |
| 400.perlbench | Spam filter | 29% | 85% | 100% | 115% |
| 401.bzip2 | Compression | 38% | 88% | 100% | 115% |
| 403.gcc | Compiling | 40% | 85% | 100% | 110% |
| 429.mcf | Vehicle scheduling | 27% | 85% | 100% | 105% |
| 445.gobmk | Game AI | 46% | 86% | 100% | 112% |
| 456.hmmer | Protein seq. analyses | 22% | 88% | 100% | 116% |
| 458.sjeng | Chess | 39% | 87% | 100% | 112% |
| 462.libquantum | Quantum sim | 10% | 82% | 100% | 104% |
| 464.h264ref | Video encoding | 33% | 87% | 100% | 114% |
| 471.omnetpp | Network sim | 30% | 75% | 100% | 103% |
| 473.astar | Pathfinding | 46% | 85% | 100% | 115% |
| 483.xalancbmk | XML processing | 25% | 83% | 100% | 109% |
First of all, single threaded is somewhat better than we expected when we received the first architectural details (a very simple dual issue core with high latency shared L2). However, this is still a fraction of the Xeon D's single threaded performance, which means that ThunderX doesn't look very impressive to companies which feel that single threaded performance should not be lower than a low end Xeon D. The latter is 2 to 4 times faster. On average, the Xeon D-1581 delivers 3 times faster single threaded performance than the ThunderX, but not 5!
SPEC CPU2006 allows us to characterize the ThunderX core a bit better. We ignore libquantum because it has a very special profile: you can triple the score with specific compiler settings, but those settings reduce performance by 2-30%(!) in some other subtests. Those compiler settings optimize cache utilization by splitting records of an array in separate arrays. Combine this with software loop prefetching and libquantum numbers can indeed double or triple. Since libquantum is hardly relevant for the server world and is known for being a target for all kind of benchmark trickery, we ignore it in our comparison.
Mcf exhibits a large amount of data cache misses and memory controller usage. Mcf is also "horribly low IPC" software, so beefy execution backends do not help. Despite those facts, the ThunderX does not do well in mcf. Mcf does a lot of pointer chasing, so the high latency L2-cache and the high latency DRAM access are slowing things down. That is probably also true for XML processing and the network simulator: those subtests have the highest data cache misses.
The shallow pipeline and relatively powerful gshare branch predictor make the ThunderX a better than expected performer in the chess (sjeng), pathfinding (astar), compiling (gcc) and AI (gobmk). Although the gobmk has a relatively high branch misprediction rate on a gshare branch predictor (the highest of all subtests), the ThunderX core can recover very quickly thanks to its 9 stage pipeline. Notice also that gobmk and gcc have relatively large instruction footprints, which gives the ThunderX and its 78 KB I-cache an advantage.
That is also true for the perl, but that benchmark has a relatively high IPC and needs a beefier execution backend. Indeed, the more compute intensive (and thus high IPC sub tests) perlbench and hmmer perform badly relative to the Intel core. In these benchmarks, the wide architecture of the Intel cores pays off.
Multi-Threaded Integer Performance: SPEC CPU2006
The value of SPEC CPU2006 int rate is questionable as it puts too much emphasis on bandwidth and way too little emphasis on data synchronization. However, it does give some indication of the total "raw" integer compute power available.
| Subtest SPECCPU2006 integer |
Application type | Cavium ThunderX 2 GHz |
Xeon D-1587 1.8-2.4 |
Xeon E5-2640 v4 2.4-2.6 |
| 400.perlbench | Spam filter | 372 | 394 | 322 |
| 401.bzip2 | Compression | 166 | 225 | 216 |
| 403.gcc | Compiling | 257 | 218 | 265 |
| 429.mcf | Vehicle scheduling | 110 | 130 | 224 |
| 445.gobmk | Game AI | 411 | 337 | 269 |
| 456.hmmer | Protein seq. analyses | 198 | 299 | 281 |
| 458.sjeng | Chess | 412 | 362 | 283 |
| 462.libquantum | Quantum sim | 139 | 126 | 231 |
| 464.h264ref | Video encoding | 528 | 487 | 421 |
| 471.omnetpp | Network sim | 121 | 127 | 172 |
| 473.astar | Pathfinding | 143 | 165 | 195 |
| 483.xalancbmk | XML processing | 227 | 219 | 266 |
On average, the ThunderX delivers the throughput of an Xeon D1581 or Xeon E5-2640. There are some noticeable differences between the subtest though, especially if you check the scalability.
| Subtest SPECCPU2006 integer |
Application type | Cavium ThunderX 2 GHz (48 copies) |
Xeon D-1587 1.8-2.3 (32 copies) |
Xeon E5-2640 v4 2.4-2.6 (20 copies) |
| 400.perlbench | Spam filter | 43x | 14x | 10x |
| 401.bzip2 | Compression | 25x | 13x | 11x |
| 403.gcc | Compiling | 22x | 8x | 9x |
| 429.mcf | Vehicle scheduling | 15x | 3x | 6x |
| 445.gobmk | Game AI | 41x | 17x | 12x |
| 456.hmmer | Protein seq. analyses | 42x | 14x | 11x |
| 458.sjeng | Chess | 47x | 16x | 11x |
| 462.libquantum | Quantum sim | 8x | 2x | 4x |
| 464.h264ref | Video encoding | 42x | 13x | 10x |
| 471.omnetpp | Network sim | 17x | 6x | 7x |
| 473.astar | Pathfinding | 16x | 10x | 10x |
| 483.xalancbmk | XML processing | 27x | 7x | 7x |
Mcf is memory latency bound, but if you run 32 threads on the Xeon D, you completely swamp its memory subsystem. The ThunderX and Xeon E5 scale better simply because they can deliver better bandwidth... but one has to wonder if this has anything to do with what people who actually use mcf will experience, as mcf is mostly latency bound. It seems like a corner case.
The XML processing testis probably a lot closer to the real world: it is much easier to split XML (or JSON) processing into many parallel parts (one per request). This is something that fits the ThunderX very well, it edges out the best Xeon D. The same is true for the video encoding tests. This indicates that the ThunderX is most likely a capable Content Delivery Network (CDN) server.
Gcc and sjeng scale well and as a result, the Thunder-X really shines in these subtests.
Comparing With the Other ARMs
We did not have access to any recent Cortex-A57 or X-Gene platform to run the full SPEC CPU2006 suite. But we can still combine our previous findings with those that have been published on the 7-cpu.com. The first X-Gene 1 result is our own measurement, the second one is the best we could find.
| SKU | Clock | Baseline Xeon D Compress | Baseline Xeon D Decompress |
| Atom C2720 | 2.4 | 1687 | 2114 |
| X-Gene 1 (AT bench) | 2.4 | 1580 | 1864 |
| X-Gene 1 (best) | 2.4 | 1770 | 1980 |
| Cortex-A57 | 1.9 | 1500 | 2330 |
| ThunderX | 2.0 | 1547 | 2042 |
| Xeon D1557 | 1.5-2.1 | 3079 | 2320 |
| Xeon E5-2640 v4 | 2.4-2.6 | 3755 | 2943 |
| Xeon E5-2690 v3 | 2.6-3.5 | 4599 | 3811 |
Let's translate this to percentages, where we compare the Thunder-X performance to the Xeon D and the Cortex-A57, two architectures it must try to beat. The first one is to open a broader market, the second one to justify the development of a homegrown ARMv8 microarchitecture.
| SKU | Clock | Baseline Xeon D Compress | Baseline Xeon D Decompress | Baseline A57 Compress | Baseline A57 Decompress |
| Atom C2720 | 2.4 | 55% | 91% | 112% | 91% |
| X-Gene (AT bench) | 2.4 | 51% | 80% | 105% | 80% |
| X-Gene (best) | 2.4 | 57% | 85% | 118% | 85% |
| Cortex-A57 | 1.9 | 49% | 100% | 100% | 100% |
| ThunderX | 2.0 | 50% | 88% | 103% | 88% |
| Xeon D1557 | 2.1 | 100% | 100% | 205% | 100% |
| Xeon E5-2640 v4 | 2.4 | 122% | 127% | 250% | 126% |
| Xeon E5-2690 v3 | 3.5 | 149% | 164% | 307% | 164% |
First of all, these benchmarks should be placed in perspective: they tend to have a different profile than most server applications. For example compression relies a lot on memory latency and TLB efficiency. Decompression relies on integer instructions (shift, multiply). Since this test has unpredictable branches, the ThunderX has an advantage.
The ThunderX at 2 GHz performs more or less like an A57 core at the same speed. Considering that AMD only got eight A57 cores inside a power envelope of 32W using similar process technology, you could imagine that a A57 chip would be able to fit 32 cores at the most in a 120W TDP envelope. So Cavium did quite well fitting about 50% more cores inside the same power envelope using an old 28 nm high-k metal gate process.
Nevertheless, a 120W Xeon E5 offers about 2.5-3 times higher compression performance. The gap is indeed much smaller in decompression, where the wide Broadwell core is only 13% (!) faster than the narrow ThunderX core (compare the Xeon D-1557 with the ThunderX).
Compression & Decompression
While compression and decompression are not real world benchmarks in and of themselves (at least as far as servers go), more and more servers have to perform these tasks as part of a larger role (e.g. database compression, website optimization).
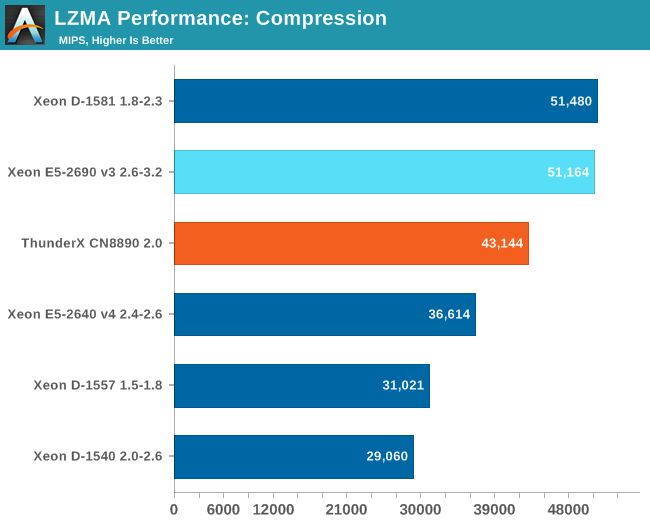
Although the ThunderX suffers from very high memory latency and a relatively modest TLB architecture, the Broadwell CPUs have one-quarter the cores. Secondly, once 20+ threads hit the memory, memory bandwidth becomes just as important as latency.
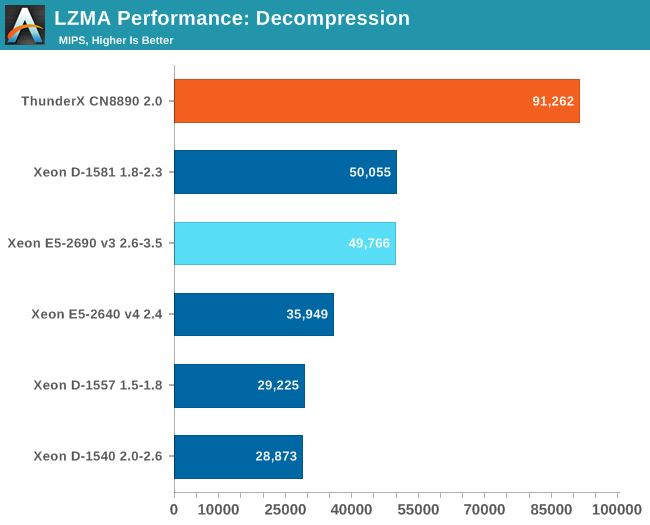
The ThunderX blows the Intel competition of the charts in decompression. However, this is an extremely ideal scenario for the ThunderX cores. First of all, the high amount of unpredictable branches of course favor the 9 stage pipeline. Secondly, ARM supports conditional instructions which might eliminate some of the branches. Thirdly, this is a very low IPC software. Remember that the complex Broadwell core had little IPC advantage over the ThunderX. So many small cores pays off big time... but this is not a full blown server benchmark.
MySQL 5.6.0
Last time we made a small error in our script, causing the Sysbench test to write to our SSDs anyway. That did not make the test invalid, but as we really want to isolate the CPU performance. However due to these changes, you cannot compare this with any similar Sysbench based benchmarking we have done before.
The Intel servers were running Percona Server 5.6 (the best-optimized MySQL server for x86), the ThunderX system was running a special ThunderX optimized version of MySQL 5.6. We used sysbench 0.5 (instead of 0.4) and we implemented the (lua) scripts that allow us to use multiple tables (8 in our case) instead of the default one. According to Cavium, there is still a lot headroom to improve MySQL performance. A ThunderX optimized version of Percona Server 5.7 should improved performance quite a bit.
For our testing we used the read-only OLTP benchmark, which is slightly less realistic, but a good first indication for MySQL Select performance.
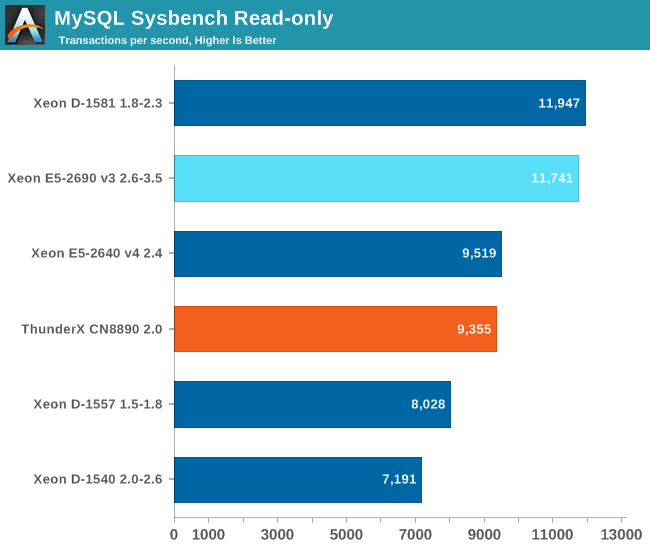
A single ThunderX core is capable of 270 transactions/s and scales well: with 32 threads and one thread per core we still get about 8000 tr/s (or 250 tr/s/core). But beyond that point, scaling is much more worse: add another 16 cores and we only get 17% more performance.
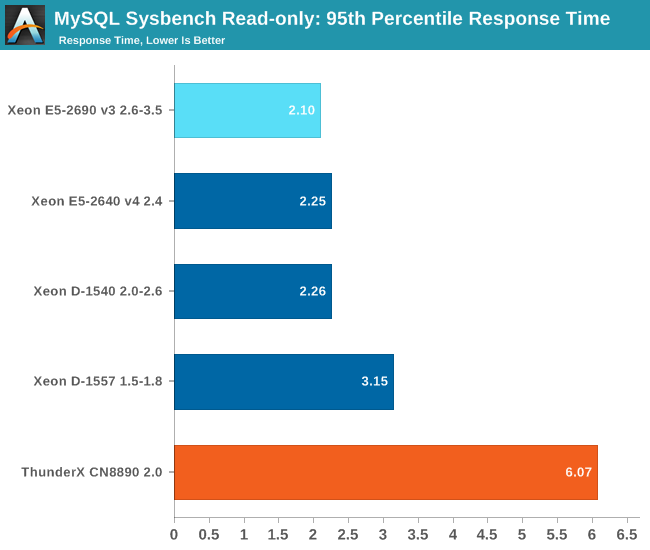
But when we look at the response times, things look a lot less rosy. The ThunderX is a lot slower when handling the more heavy SQL statements.
It is clear that the ThunderX is no match for high frequency trading and other database intensive applications. However, when MySQL serves as just a backend for a website and satisfies simple "get data x or y" requests, the 4 extra ms are a small nuisance.
Java Performance
The SPECjbb 2015 benchmark has "a usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations." It uses the latest Java 7 features and makes use of XML, compressed communication, and messaging with security.
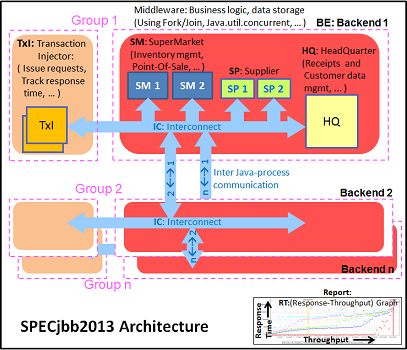
We tested with four groups of transaction injectors and backends. The Java version was OpenJDK 1.8.0_91.
We applied relatively basic tuning to mimic real-world use, while aiming to fit everything inside a server with 64 GB of RAM (to be able to compare to lower end systems):
"-server -Xmx8G -Xms8G -Xmn4G -XX:+AlwaysPreTouch -XX:+UseLargePages"
With these settings, the benchmark takes about 43-55GB of RAM. Java tends to consume more RAM as more core/threads are involved. Therefore, we also tested the Xeon E5-2640v4 and ThunderX with these settings:
"-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:+UseLargePages"
The setting above uses about 115 GB. The labels "large" ("large memory footprint") report the performance of these settings. We did not give the Xeon D-1581 the same treatment as we wanted to mimic the fact that the Xeon has only 4 DIMM slots, while the Xeon E5 and ThunderX have (at least) eight.
The first metric is basically maximum throughput.
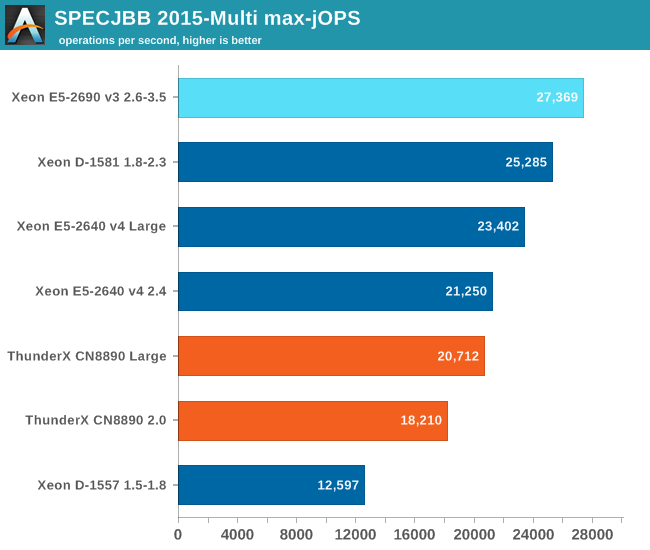
Notice how the Xeon D-1581 beats the Xeon E5-2640 in a typical throughput situation by 8%, while the SPECint_rate numbers told us that the Xeon E5 would be slightly faster. It is a typical example of how running parallel instances overemphasizes bandwidth. The extra 6 cores (@2.1 GHz) push the Xeon D past the Xeon E5 (10 cores@ 2.6 GHz) despite the fact that the Xeon D has only half the bandwidth available.
The ThunderX offers low end Xeon E5 performance, but that still a lot better than what we would have expected from the SPECint_rate numbers (Dual socket ThunderX = Xeon-D). Once we offer more memory to ThunderX, performance goes up by 14%. The Xeon E5 gets a 10% performance boost.
The Critical-jOPS metric is a throughput metric under response time constraint.
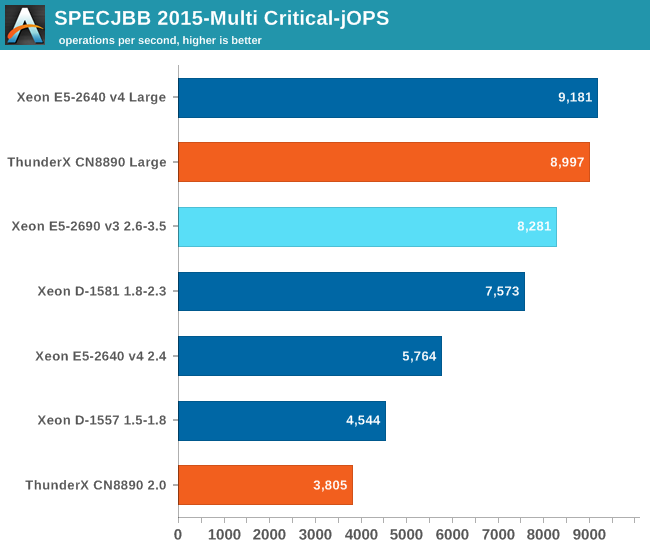
The critical jOPS is the most important metric as it shows how many requests can be served in a timely manner. At first we though that the lack of single threaded performance to run the heavier pieces of Java code fast enough is what made the ThunderX so much slower than the rest of the pack.
However, the 48 threads were mostly hindered by the lack of memory per thread. Once we offer enough memory to the 48-headed ThunderX, performance explodes: it is multiplied by 2.4x! The Xeon E5 benefits too, but performance is "only" 60% higher. Thanks to the DRAM breathing room, the ThunderX moves from "slower than low end Xeon D" to "midrange Xeon E5" territory.
SPECJBB®2015 is a registered trademark of the Standard Performance Evaluation Corporation (SPEC).
Floating Point: C-ray
Shifting over from integer to floating point benchmarks we have C-ray. C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out the L1-cache. That said, it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing. We use this benchmark because it allows us to isolate the FP performance and the energy consumption from other factors such as L2/L3 cache/memory subsystem.
We compiled the C-ray multi-threaded version with -O3 -ffast-math. Real floating point intensive applications tend to put the memory subsystem under pressure, and running a second thread makes it only worse. So we are used to seeing that many HPC applications perform worse with multi-threading on. But since C-ray runs mostly out of the L1-cache, we get different behavior.
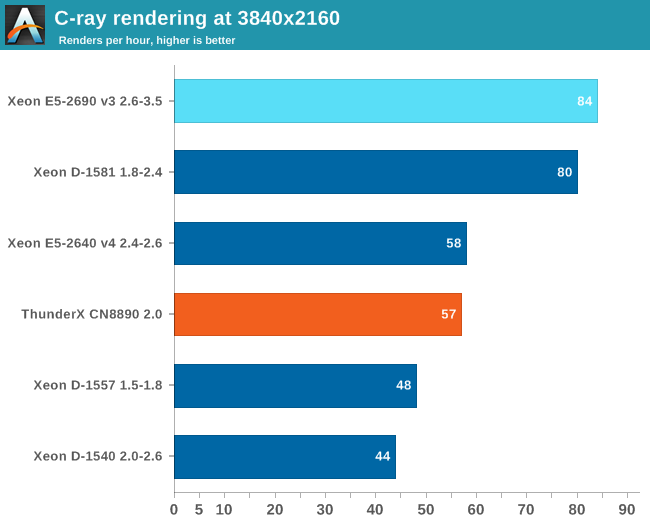
This is the most favorable floating point benchmark that we could run on the ThunderX: it does not use the high latency blocking L2-cache, nor does it needs to access the DRAMs. Also, the Xeons cannot really fully flex their AVX muscles. So take this with a large grain of salt.
In these situations, the ThunderX performs like the midrange Xeon E5-2640 v4.
Energy Consumption
A large part of the server market is very sensitive to performance-per-watt. That includes the cloud vendors. For a smaller part of the market, top performance is more important than the performance/watt ratio. Indeed for financial trading, big data analyses, database, and some simulation servers, performance is the top priority. Energy consumption should not be outrageous, but it is not the most important concern.
We tested the energy consumption for a one-minute period in several situations. The first one is the point where the tested server performs best in MySQL: the highest throughput just before the response time goes up significantly. Then we look at the point where throughput is the highest (no matter what response time). This is is the situation where the CPU is fully loaded. And lastly we compare with a situation where the floating point units are working hard (C-ray).
| SKU | TDP (on paper) spec |
Idle W |
MySQL Best throughput at lowest resp time (W) |
MySQL Max Throughput (W) |
Peak vs idle (W) |
Transactions per watt |
C-ray W |
| Xeon D-1557 | 45 W | 54 | 99 | 100 | 46 | 73 | 99 |
| Xeon D-1581 | 65 W | 59 | 123 | 125 | 66 | 97 | 124 |
| Xeon E5-2640 v4 | 90 W | 76 | 135 | 143 | 67 | 71 | 138 |
| ThunderX | 120 W | 141 | 204 | 223 | 82 | 46 | 190 |
| Xeon E5-2690 v3 | 135 W | 84 | 249 | 254 | 170 | 47 | 241 |
Intel allowed the Xeon "Haswell" E5 v3 to consume quite a bit of power when turbo boost was on. There is a 170W difference between idle and max throughput, and if you assume that 15 W is consumed by the CPU in idle, you get a total under load of 185W. Some of that power has to be attributed to the PSU losses, memory activity (not much) or fan speed. Still we think Intel allowed the Xeon E5 "Haswell" to consume more than the specified TDP. We have noticed the same behavior on the Xeon E5-2699 v3 and 2667 v3: Haswell EP consumes little at low load, but is relatively power hungry at peak load.
The 90W TDP Xeon E5-2640v4 consumes 67W more at peak than in idle. Even if you add 15W to that number, you get only 82W. Considering that the 67W is measured at the wall, it is clear that Intel has been quite conservative with the "Broadwell" parts. We get the same impression when we tried out the Xeon E5-2699 v4. This confirms our suspicion that with Broadwell EP, Intel prioritized performance per watt over throughput and single threaded performance. The Xeon D, as a result, is simply the performance per watt champion.
The Cavium ThunderX does pretty badly here, and one of the reason is that power management either did not work, or at least did not work very well. Changing the power governor was not possible: the cpufreq driver was not recognized. The difference between peak and idle (+/- 80W) makes us suspect that the chip is consuming between 40 and 50W at idle, as measured at the wall. Whether is just a matter of software support or a real lack of good hardware power management is not clear. It is quite possibly both.
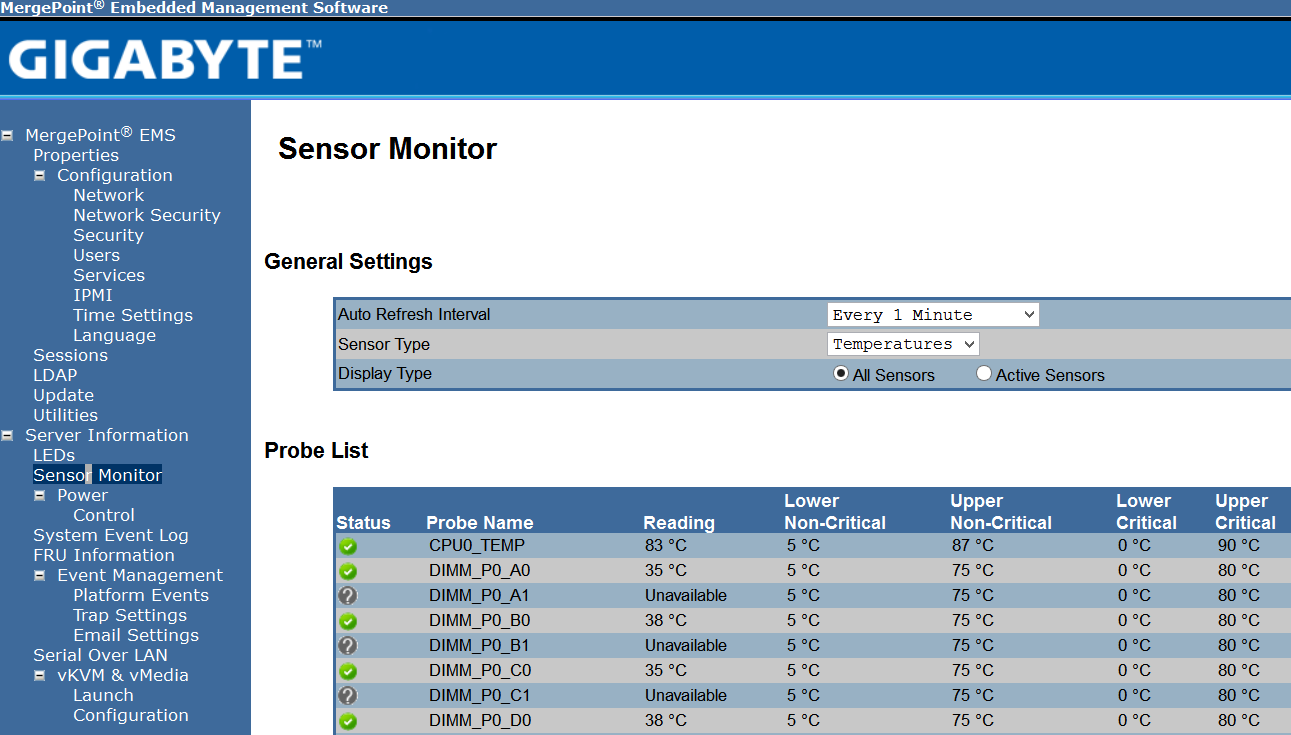
We would also advise Gigabyte to use a better performing heatsink for the fastest ThunderX SKUs. At full load, the reported CPU temperature is 83 °C, which leaves little thermal headroom (90°C is critical). When we stopped our CRAC cooling, the gigabyte R120-T30 server forced a full shutdown after only a few minutes while the Xeon D systems were still humming along.
Limitations of This Review
Before we get to our closing thoughts, I want to talk a bit about what we were and weren't able to do in our testing, and in what ways this limits our review. The still somewhat "rough on the edges" software ecosystem gave us a lot of headaches. Our setup was a Ubuntu 14.04 with lots of customized (Cavium's beta gcc compiler, MySQL version ThunderX 5.6) and newer software (the Linux kernel 4.2). The result was that we were slowed down by a large number of solvable (but time consuming) software and configuration problems.
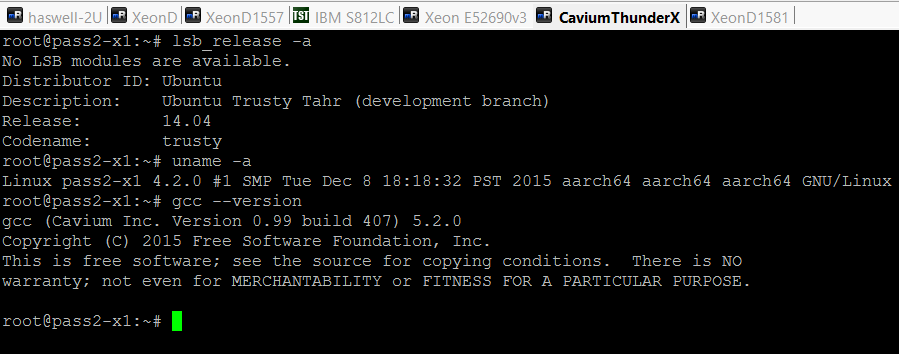
Don't get me wrong: Linux on ARM has come a long way. Most software works, the exception was Spark 1.5 (Java based) which crashed with a very low level message. Still, it took quite a bit of time to get software configured correctly, while on x86 it is simply a matter of using "apt-get install".
Cavium told us that they expect that these problems will be solved in Ubuntu 16.04, and a firmware upgrade to support the new Ubuntu is on its way. That is also why we were not able to test our most real world and relevant benchmarks, such as our webserver tests. Webcaching, light webserving and Contend Delivery Networking might fit the ThunderX well as it has access to more memory and networking bandwidth than the Xeon D.
But webservers require a lot of software components (caching layer, webserver, interpreter etc.) that have to work together well. So we wait for 16.04 and the new firmware to arrive to build these complex tests.
Closing Thoughts
Exploring a new ambitious server SoC is always an interesting journey, but also a very time intensive one. We had to find out what the real performance profile of the ThunderX, not the perceived or advertised one. There have been both good and bad surprises in our journey.
Let's start with the bad: the blocking L1 cache, high latency L2-cache and high latency DRAM access are lowering the scalability of the 48 cores in a whole range of software. The ThunderX could still be a good candidate as front-end webserver, but Cavium has to solve the high power usage at low loads. Power management seems to be more problematic than single-threaded performance. Cavium promises that ThunderX2 will vastly improve power management by letting hardware handle much more of the management duties. But the current ThunderX power management capabilities seem to be rather basic. Cavium's information is sketchy at best.
The Xeon D, by comparison, offers superior performance per watt: twice as good as the ThunderX. It is clear that the ThunderX is not a good match for heavy database servers, nor for enterprise workloads where energy consumption at low load is a high priority.
The good. The 12 and 16-core Xeon Ds ($1300-$1800) and midrange E5s ($900-$2000, not including 10 GBe NICs) cost quite a bit more than the ThunderX ($800). Gigabyte could not tell us how much the R120-T30 would cost, only that the pricing would be "competitive with similar midrange Xeon E5 servers".
Although single-threaded performance is low, it is definitely not as terrible as commonly assumed. We found out that the raw integer computing power of the Thunder-X is about one-third that of the best Xeon Ds, not one-fifth as claimed in advertising materials (a difference of 65%). The ThunderX core is almost as good as the A57, while it consumes quite a bit less power and thus offers a better performance-per-watt than the latter. On the condition that you give it enough DRAM, the 48 cores are able to offer the Java performance of a midrange Xeon E5, even when we expect the system to remain under a certain response time.
Those facts – better than expected single threaded performance and midrange Xeon E5 throughput – make a world of difference. And we have yet to test the ThunderX in situations that is was really built for: network-intensive ones. The XML processing and h264 substests (SPEC CPU) indicate that there is definitely some truth in Cavium's claims that the ThunderX shines as a compute engine of a load balancer, web cache or CDN server.

As single threaded performance (SPEC CPU) is not as dramatic as commonly assumed and Java performance is already very close to what was promised, this puts the forthcoming ThunderX2 in a different light.
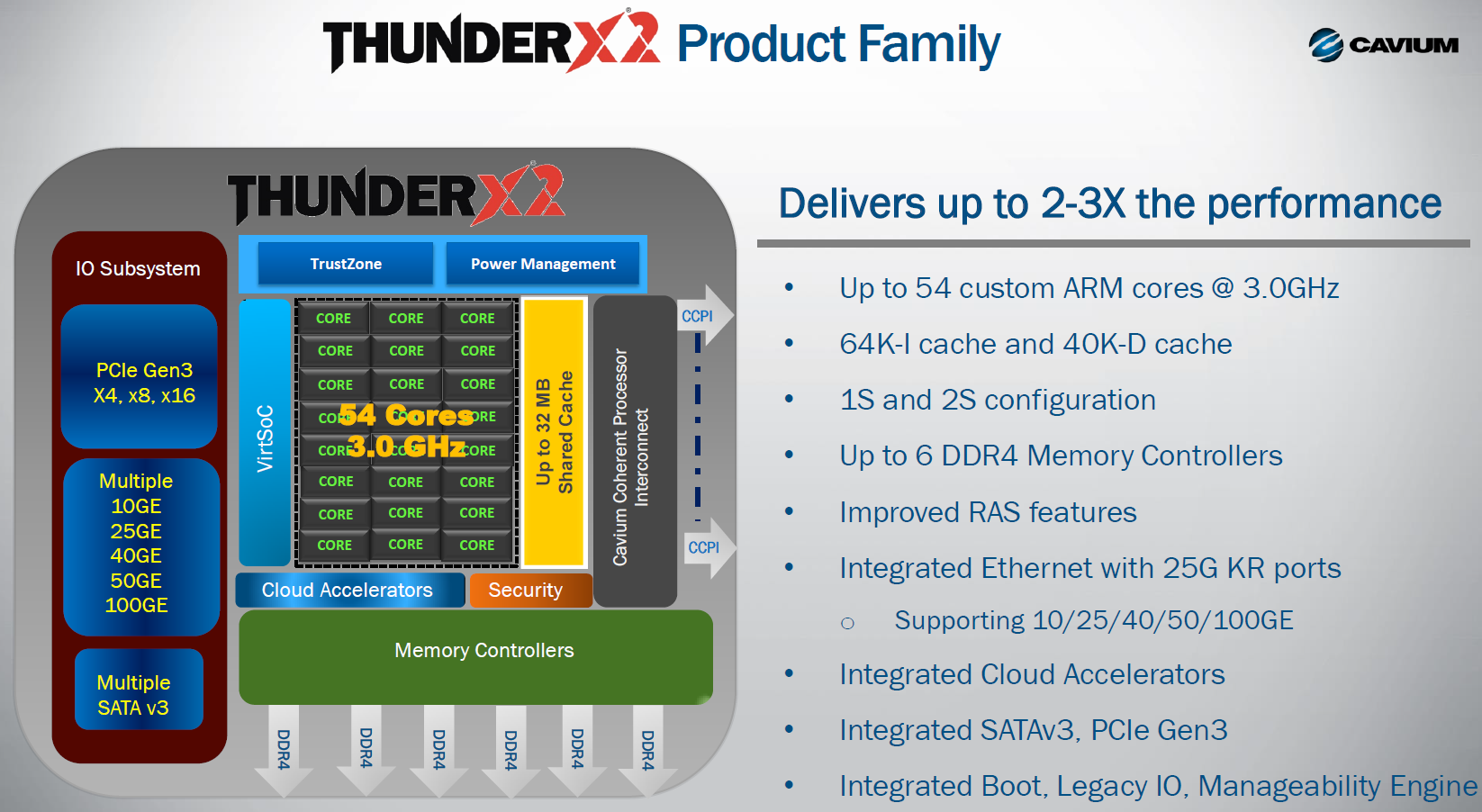
Using the new 14 nm FinFET technology of GlobalFoundries, Cavium claims it will reach 2.6-3.0 GHz and get a lot of microarchitectural improvements. This should result in twice as much performance per core. If indeed the ThunderX2 can offer single threaded performance at the level of the low end Xeon D (1.3-1.5 GHz), that might place it in the "SoCs with acceptable single threaded performance" and opens up new markets. Time will tell, but Cavium has proven it can deliver SoCs in a timely manner. And the fact that Cavium allows independent testing instead of just showing numbers on PowerPoint presentations tell us that they have confidence in the future of their ARMv8 endeavors.






