Original Link: https://www.anandtech.com/show/5057/the-bulldozer-aftermath-delving-even-deeper
The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTIt has been months since AMD's Bulldozer architecture surprised the hardware enthusiast community with performance all over the place. The opinions vary wildly from “server benchmarks are here, and they're a catastrophe” to “Best Server Processor of 2011”. The least you can say is that the idiosyncrasies of AMD's latest CPU architecture have stirred up a lot of dust.
Now that the dust has settled, the Bulldozer chips now account for more than half of Opteron shipments and revenues. Since AMD's Financial Analyst Day (February 2, 2012), we have new code names: the improved Bulldozer architecture "Piledriver" will power the "Abu Dhabi" chip, a replacement for the current top server chip "Interlagos". AMD is clearly committed to the new "Bulldozer" direction: fitting as many cores as possible into a certain power envelope to improve thread throughput, while trying to "hold the line" on single-threaded performance.
In theory, the new 16-core Interlagos should have offered somewhere around a 33% boost in most highly-threaded applications. The reality is unfortunately not that rosy: in many highly-threaded server applications such as OLAP databases and virtualization, the new Opteron 6200 fails to impress and is only a few percent faster than it's older brother the 12-core Magny-Cours. There are even times where the older Opteron is faster.
Some, including sources inside AMD, have blamed Global Foundries for not delivering higher clocked SKUs. Sure, the clock speed targets for Interlagos were probably closer to 3GHz instead of 2.3GHz. But that does not explain why the extra integer cores do not deliver. We were promised up to 50% higher performance thanks to the 33% extra cores, but we got 20% at the most.
The combination of low single-threaded performance, the failure to really outperform the previous generation in highly-threaded applications, the relatively high power consumption at full load, and the fact that the CPU is designed for high clock speeds gives a lot of people a certain sense of Déjà vu: is this AMD's version of the Pentum 4 ?
One of our readers, "Iketh", spoke up and voiced the opinion of many of our readers:
" Unfortunately, the thought still in the back of my mind while reading was why did AMD reinvent the Pentium 4? I just don't get it."
Another reader nicknamed "Clagmaster" commented:
"A core this complex in my opinion has not been optimized to its fullest potential. Expect better performance when AMD introduces later steppings of this core with regard to power consumption and higher clock frequencies."
Although there have already been quite a few attempts to understand what Bulldozer is all about, we cannot help but not feel that many questions are still unanswered. Since this architecture is the foundation of AMD's server, workstation, and notebook future (Trinity is based on the improved Bulldozer core with the codename "Piledriver"), it is interesting enough to dig a little deeper. Did AMD take a wrong turn with this architecture? And if not, can the first implementation "Bulldozer" be fixed relatively easily?
We decided to delve deeper into the SAP and SPEC CPU2006 results, as well as profiling our own benchmarks. Using the profiling data and correlating it with what we know about AMD's Bulldozer and Intel's Sandy Bridge, we attempt to solve the puzzle.
The Front End: Branch Prediction
Bulldozer's branch prediction units have been described in many articles. Most insiders agree that Bulldozer's decoupled branch predictor is a step forward from the K10's multi-level predictor. A better predictor might reduce the branch misprediction rate from 5 to 4%, but that is not the end of the story. Here's a quick rundown of the branch prediction capabilities of various CPU architectures.
| Branch Prediction | |||||
| Architecture | Branch Misprediction Penalty | ||||
| AMD K10 (Barcelona, Magny-Cours) | 12 cycles | ||||
| AMD Bulldozer | 20 cycles | ||||
| Pentium 4 (NetBurst) | 20 cycles | ||||
| Core 2 (Conroe, Penryn) | 15 cycles | ||||
| Nehalem | 17 cycles | ||||
| Sandy Bridge | 14-17 cycles | ||||
The numbers above show the minimum branch misprediction penalty, and the fact is that the Bulldozer architecture has a branch misprediction penalty that is 66% higher than the previous generation. That means that the branch prediction of Bulldozer must correctly predict 40% of the pesky branches that were mispredicted by the K10 to compensate (at the same clock). Unfortunately, that kind of massive branch prediction improvement is almost impossible to achieve.
Quite a few people have commented that Bulldozer is AMD's version of Intel's Pentium 4: it has a long pipeline, with high branch misprediction penalties, and it's built for high clock speeds that it cannot achieve. The table above seems to reinforce that impression, but the resemblance between Bulldozer and NetBurst is very superficial.
The minimum branch prediction penalty of the Bulldozer chip is indeed in the same range as Pentium 4. However, the maximum penalty could be a horrifying 100 cycles or more on the P4, while it's a lot lower on Bulldozer. In most common scenarios, the Bulldozer's branch misprediction penalty will be below 30 cycles.
Secondly, the Pentium 4's pipeline was 28 ("Willamette") to 39 ("Prescott") cycles. Bulldozer's pipeline is deep, but it's not that deep. The exact number is not known, but it's in the lower twenties. Really, Bulldozer's pipeline length is not that much higher than Intel's Nehalem or Sandy Bridge architectures (around 16 to 19 stages). The big difference is that the introduction of the µop cache (about 6KB) in Sandy Bridge can reduce the typical branch misprediction to 14 cycles. Only when the instruction is not found in the µop cache and must be fetched from the L1 data cache will the branch misprediction penalty increase to about 17 cycles. So on average, even if the efficiency of Bulldozer's and Sandy Bridge's branch predictors is more or less the same, Sandy Bridge will suffer a lot less from mispredictions.
The Front End: Shared Decoders
Quite a few reviewers, including our own Anand, have pointed out that two integer cores in Bulldozer share four decoders, while two integer cores in the older “K10” architecture each get three decoders. Two K10 cores thus have six decoders, while two Bulldozer cores only have four. Considering that the complexity of the x86 ISA leads to power hungry decoders, reducing the power by roughly 1/3 (e.g. four decoders instead of six for dual-core) with a small single-threaded performance hit is a good trade off if you want to fit 16 of these integer cores in a power envelope of 115W. Instead of 48 decoders, Bulldozer tries to get by with just 32.
The single-threaded performance disadvantage of sharing four decoders between two integer cores could have been lessened somewhat by x86 fusion (test + jump and CMP + jump; Intel calls this macro-op fusion) in the pre-decoding stages. Intel first introduced this with their “Core” architecture back in 2006. If you are confused by macro-ops and micro-ops fusion, take a look here.
However AMD decided to introduce this kind of fusion in Bulldozer later in the decoding pipeline than Intel, where x86 branch fusion is already present in the predecoding phases. The result is that the decoding bandwidth of all Intel CPUs since Nehalem has been up to five (!) x86-64 instructions, while x86 branch fusion does not increase the maximum decode rate of a Bulldozer module.
This is no trifle, as on average this kind of x86 fusion can happen once every ten x86 instructions. So why did AMD let this chance to improve the effective decoding rate pass even if that meant creating a bottleneck in some applications? The most likely reason is that doing this prior to decoding increases the complexity of the chip, and thus the power consumption. Even if AMD's version of x86 branch fusion does not increase the decoding bandwidth, it still offers advantages:
- Increased dispatch bandwidth
- Reduced scheduler queue occupancy
- Faster branch misprediction recovery
The first two increase performance without any extra (or very minimal) power consumption, the last one increases performance and reduces power consumption. AMD preferred to get more cores in the same power envelop over higher decode bandwidth and thus single-threaded performance.
Mark of Hardware.fr compared the performance of a four module CPU with only one core per module enabled with the standard configuration (two integer cores per module). Lightly threaded games were 3-5% faster, which is the first indication that the front end might be something of a bottleneck for some high IPC workloads, but not a big one.
The Memory Subsystem
One of the most important features of Intel's Core architecture was its speculative out-of-order memory pipeline. It gave the Core architecture a massive improvement in many integer benchmarks over the K8, which had a strictly in order pipeline. Barcelona improved this a bit by bringing the K10 to the level of the much older PIII architecture: out of order, but not speculative. Bulldozer now finally has memory disambiguation, a feature which Intel introduced in 2006 in their Core architecture, but there's more to the story.
Bulldozer can have up to 33% more memory instructions in flight, and each module (two integer stores) can do four load/stores per cycle. It's clear that AMD’s engineers have invested heavily in Memory Level Parallelism (MLP). Considering that MLP is often the most important bottleneck in server workloads, this is yet another sign that Bulldozer is targeted at the server world. In this particular area of its architecture, Bulldozer can even beat the Westmere Intel CPUs: two threads on top of the current Intel architecture have only 2 load/stores available and have to share the L1 data cache bandwidth.
The memory controller is improved too, as you can see in the stream benchmark results below. For details about our Stream binary, check here.
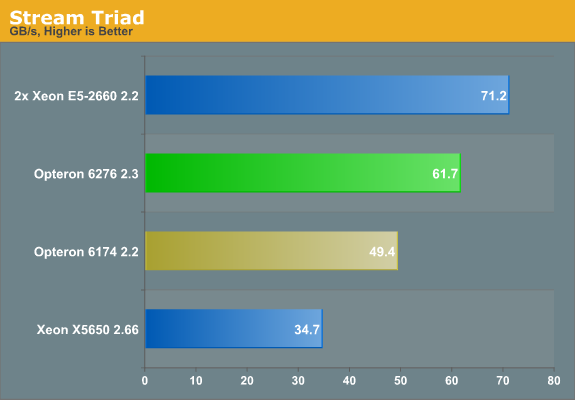
Bandwidth is 25% higher than Barcelona, while the clock speed of the RAM modules has only increased by 20%. Clearly, the Orochi die of the Opteron 6200 has a better memory controller than the Opteron 6100. The memory controller and load/store units are among the strongest parts of the Bulldozer architecture.
Integer Crunching Power
Each core has two integer executions units (EX0 and EX1) and two AGUs (Address Generation Units). For comparison, the K10 core inside Magny-Cours and Istanbul had three ports to a “Fully featured ALU + AGU” couple. AMD marketing cleverly drew four pipeline blocks inside the Bulldozer integer core, but those powerpoint blocks cannot hide the fact that each Bulldozer integer core has fewer execution resources.

In practice, the AG0 and AG1 are little more than assistants with limited capabilities to EX0 and EX1.The software optimization guide for AMD family 15h processors lists only a few instructions (page 248 in the January 2012 version) that can be processed by the AG0 and AG1 execution units and each time the remark "First op to AG0 | AG1, Second to EX0 | EX1" is made. The AG0 and AG1 execution units reduce the latency of the CALL and LEA instructions, but the maximum throughput of each integer core inside the Bulldozer module is only two integer instructions per clock cycle. It's only when a fused branch enters EX0 and another integer instruction can enter EX1 that we have a slightly higher throughput of three integer instructions.
So the Bulldozer integer core can execute one integer instruction less per cycle (2 vs 3). That doesn’t mean that the Bulldozer integer core is 1/3 slower, however. The integer core of Bulldozer is smaller but also more flexible. The per lane dedicated 8-entry schedulers are gone, and a much larger 40 entry scheduler replaced it. This means that Bulldozer should be better at extracting ILP (Instruction Level Parallelism) out of code that has low IPC (Instructions Per Clock).
In some integer intensive applications, the fact that the maximum throughput of integer instructions is somewhat lower might slow things down. That is the not very useful "it depends" answer, so let's clarify: what kind of applications are we talking about?
The Current Situation
It's not hard to explain why an 8-thread processor with slightly lower single-threaded performance does not do well in many desktop applications. If you compare for example the hex-core Core i7-3960X with a quad-core i7-3820, four games did not benefit from the extra two cores: Civilization V, Crysis, Dirt 3 and Metro 2033. In Starcraft 2, World of Warcraft, and Dawn of War 2, the 50% higher core count was good for a 10% performance boost at best. In other words, the situation has improved, but most games don't scale well beyond four cores. There are also other factors at play, though, as it's already known that StarCraft II doesn't use more than two cores; instead, it's likely the 15MB (vs. 10MB in i7-3820) L3 cache that helps improve performance.
The situation in the server space is a lot harder to explain. The Opteron 6100 was able to keep up—more or less—with the Xeon 5600 performancewise. However, the Xeon 5600 was equipped with much better power management and the Xeon won the performance/watt race in most applications, with the exception of HPC applications.
The Opteron 6200 added a bit of performance but sips much less power at low and medium load, so it was capable of offering a better performance per Watt ratio than its older brother. However, since the Xeon E5 came out, the situation became pretty dramatic for the Opteron. One telling example is the fact that only one VMmark 2.0 result on the Opteron 6200 exists, but it has been withdrawn. Even if the reported 12.77 score is close to truth, we need four AMD Opteron 6726 (2.3GHz) to beat the best dual Xeon E5 (2690 at 2.9GHz) by 15%.
We have shown already quite a few benchmarks in two Opteron 6276 articles and one Xeon E5 review. We summarized the relevant numbers of both articles in the table below. The benchmarks below are real world and very relevant to the professional in our opinion.
| Software: Importance in the market |
Opteron 6276 vs. Opteron 6174 |
Xeon E5-2660 vs. Opteron 6276 |
Virtualization: 20-50% |
||
| ESXi + Linux (vApusMark FOS) |
+1% |
+40% |
OLAP Databases: 10-15% |
|
|
| MS SQL Server 2008 R2 (OLAP throughput) |
-9% |
+34% |
HPC: 5-7% |
|
|
| LS-Dyna (Neon-Refined) |
+21% |
+26% |
Rendering software: 2-3% |
|
|
| Cinebench |
+2% |
+37% |
ERP |
|
|
| SAP |
+18% |
+13% |
Now consider that all these applications are highly-threaded and scale well. Despite the 33% higher integer core count, the Opteron 6276 is not able to outperform the older Magny-Cours in the OLAP, virtualization and rendering benchmarks. However, the architecture is showing its promise by offering about 20% better performance in SAP and HPC applications.
What makes the Bulldozer cores fail in the OLAP benchmark and succeed in SAP? We now have some interesting profiling details on SAP as well as our OLAP benchmark, so we can delve deeper.
SAP S&D profiled
The SAP S&D 2-Tier benchmark has always been one of my favorites. This is probably the most real world benchmark of all server benchmarks done by the vendors. It is a full blown application living on top of a heavy relational database. And don't forget that SAP is one of the most successful software companies out there, the undisputed market leader of Enterprise Resource Planning.
Profiling this benchmark is beyond the capabilities of our lab but Intel shared some of their profiling data when they compared the Xeon E5 with the Xeon 5600. This gives us very interesting insights in how the SAP application behaves.
| SAP S&D | SPEC Int 2006 | |
| Typical IPC (on Intel Westmere) | 0.5 | 1.1 |
| Typical IPC (on Intel Sandy Bridge) | 0.55 | 1.29 |
| Branches | 18% | 19% |
| Mispredictions | 0.9% | 1.1% |
| Loads (percentage of instruction mix) | 32% | 28% |
| Stores (percentage of instruction mix) | 16% | 11% |
Besides the high level profiling numbers, quite a few details surfaced. For example, increasing the ROB (ReOrder Buffer) from 128 (Westmere) to 168 (Sandy Bridge) reduced the ROB stalls from 10% to almost nothing. Increasing the load buffers from 48 to 64 reduced the load buffers stalls to one fifth of what they were before! This clearly shows that SAP puts quite a bit of pressure on both the ROB and the load units. The application finds ample integer processing power in most modern processors, but it is limited by how fast data can be loaded and how well the Out of Order engine (of which the ROB is the primary buffer) is able to hide the load latency.
Further data confirms this. It is was my understanding that the hardware prefetchers of Sandy Bridge were improved a bit compared to Westmere/Nehalem, but in fact the smarter prefetchers are able to reduce the L2 cache misses by no less than 40%! Now, consider that in most SPEC CPU int 2006 benchmarks only 1 to 10 instructions out of 1000 typically miss the L2 cache. In contrast, in SAP, about 40 out of 1000 instructions miss the small 256KB L2 cache of the Westmere Xeon 5600, which is in the same range as the most memory intensive application in the SPEC CPU2006 int CPU suite (mcf).
SAP is thus an application that misses the L2 cache much more than most applications out there, with the exception of some exotic HPC apps. The better prefetchers inside Sandy Bridge make much better use of the extra bandwidth available and reduce the L2 and L1 misses. Hence, these improved prefetchers are probably one of the main reasons why Sandy Bridge performs better.
Interestingly, the L1 instruction cache misses were halved, and most of the L2 cache miss reduction came from instruction prefetching (less than half the cache misses). Data requests could not be prefetched.
So the end conclusion about SAP is:
- The application has very low instruction level parallelism (ILP) and as a result is not taxing the integer units much.
- The application has a relatively large but "prefetcheable" instruction footprint, which allows the prefetchers to reduce the instruction related cache misses
- The application has a massive and random data footprint, putting great pressure on the load subsystem. As a result the out of order engine has to hide the latency the best it can, and large ROB and load buffers help a lot. The latency of the memory subsystem matters.
Combine this with the fact that the SAP application has a high amount of TLP (Thread Level Parallism) and you'll understand that this is an application ideally suited for Hyper-Threading and Clustered Multi-Threading. Hyper-Threading for example is good for a 30% performance boost. The SAP S&D benchmark is a prime example on how a CPU architecture can be more server or more consumer oriented. The charactheristics of server applications are vastly different from the software that we run on our laptops and desktops.
SAP will hardly be limited by the lower integer execution resources of the individual Bulldozer integer cores. Bulldozer has vastly improved prefetching capabilities and larger OOO buffers. Add to this the 33% higher core count, and we should expect Bulldozer to outperform Magny-Cours chips by at least 33%, as the SAP benchmark emphasizes the strong points of the individual Bulldozer core without stressing the weak points (lower integer throughput). However, we are nowhere near 33% better performance, let alone the 50% higher throughput once promised by AMD. Why?
We have uncovered some additional understanding with the above information, but our job is not done yet.
Next stop: SPEC CPU2006 Int Rate
There is no denying that SPEC CPU2006 was never one of our favorite benchmarks in the Professional IT section of AnandTech. Although it is the standard benchmark of most CPU designers and academic researchers, it is far from a real world benchmark for most professional IT users.
For starters, a typical SPEC CPU2006 benchmark consists of running as many SPEC CPU2006 instances as there are cores available in the machine. The SPEC CPU2006 instances run completely independently from each other, so there are much fewer locks or other synchronization mechanisms at work: the benchmark scales almost perfectly as long as there is enough bandwidth available. Unfortunately, that is not how the majority of business software behaves: databases have high locking overhead and most applications need some synchronization.
Secondly, most of the subtests are related to gaming and simulations (HPC). Typically these applications are much more processing intensive and achieve a higher IPC than your average business application.
Lastly, the source code of the SPEC CPU2006 tests is compiled with extremely aggressively tuned compiler settings and compilers that are less used in the rest of the IT world. Few SPEC CPU2006 results are compiled with gcc and Microsoft's Visual Studio, for example.
However, it would be a step too far to call SPEC CPU2006 useless. From a high level perspective, the scores of SPEC CPU2006 show a strong correlation with L2/L3 cache misses, cache latency, and to a lesser degree branch prediction, just like many business applications. Given similar platforms (like Intel Nehalem and AMD's Shanghai), the CPU SPEC2006 Int score gives a vague idea of which CPU has the most raw integer crunching power, although it overemphasizes memory bandwidth and core count.
To understand the weaknesses and strengths of a certain CPU architecture, even in server workloads, there is no better test than SPEC CPU2006. The first reason is that it has been profiled by so many different people from academia to engineers. If we zoom in on the subtests we can derive a lot of information as we know exactly how these applications behave: there have been lots of performance characterization papers going into great detail.
The second reason is that SPEC CPU2006 tests are compiled with the most optimal compilers and compiler options available at a certain point in time. This gives us some insight into the "real" (e.g. future) potential of a processor. We can exclude the possibility that a processor performs badly because some legacy piece of code is detrimental to the performance. If the CPU cannot score well with these kinds of binaries, it never will!
Auto-parallelization made the normal single-threaded SPEC CPU benchmarks very hard to read. We turn to the rate version instead. Since it scales almost perfectly, it is relatively easy to deduce single-threaded performance from the SPEC rate numbers--on the condition that cache interference and bandwidth bottlenecks do not blur the picture too much, so we have to be careful with those benchmarks that miss the L2 cache a lot. The current CPU2006 int scores are as follows:
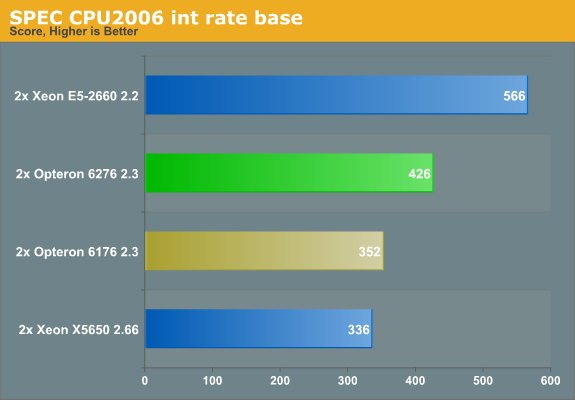
The Xeon E5 is the most efficient clock for clock, core for core. But let us compare the Opteron 6276 (2.3GHz, 16-core Bulldozer) and the Opteron 6176 (2.3GHz, 12-core Magny-Cours) in the subtests.
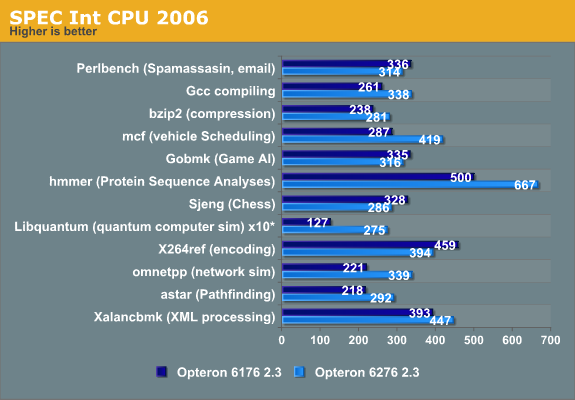
You can immediately derive from these numbers that the "Bulldozer" architecture has a very different architecture profile than Magny-Cours (which was based on the improved Barcelona architecture, Istanbul). Libquantum, omnetpp and mcf show larger performance boosts than you might expect from the 33% higher corecount. These benchmarks show that in some scenarios, Bulldozer can even increase the IPC compared to its predecessor.
We also notice that Bulldozer has some serious weaknesses compared to its predecessor, as performance decreases in the Perlbench, the game AI (gobmk), the chess (Sjeng), and the x264 encoding subtests. And although it is not uncommon that a new architecture fails to beat the previous architecture in every benchmark, it is not a good sign that even a 33% core count cannot overcome the IPC decrease in a very good scaling benchmark. If we try to understand what makes these subtests different from the others, we can get an idea of what kind of software makes Bulldozer choke. This in turn can help us to understand if relatively small tweaks can help future Opterons.
Zooming in on SPEC CPU2006: the Good
We filtered out those benchmarks that showed a 30% improvement over Magny-Cours (based on the K10 core). Remember the Bulldozer architecture has been designed to deliver 33% more cores in the same power envelope while keeping the IPC more or less at 95% of the K10. The rest of the performance should have come from a clock speed increase. The clock speed increases did not materialize in the real world, and we also kept the clock speed the same to focus on the architecture. Where a 30-35% performance increase is good, anything over 35% indicates that the Bulldozer architecture handles that particular sort of software better than Magny-Cours.

The Libquantum score is the most spectacular. Bulldozer performs over twice as fast and the score of 2750 is not that far from the all mighty Xeon 2660 at 2.2GHz (3310). Bulldozer here is only 17% slower.
At first sight, there is nothing that should make Libquantum run very fast on Bulldozer. Libquantum contains a high amount of branches (27%) and we have seen before that although Bulldozer has a somewhat improved branch predictor, the deeper pipeline and higher branch misprediction penalty can cause a lot of trouble. In fact, Perlbench (23%), Sjeng Chess (21%), and Gobmk (AI, 21%) are branchy software and are among the worst performing tests on Bulldozer. Luckily, Libquantum has a much easier to predict branches: libquantum is among the software pieces that has the lowest branch misprediction rates (less than six per 1000 instructions).
We all know that Bulldozer can deal much better with loads and stores than Magny-Cours. However, libquantum has the lowest (!) amount of load/stores (19%=14% Loads, 5% Stores). The improved Memory Level Parallelism of Bulldozer is not the answer. The table below gives an idea of the instruction mix of SPEC CPU2006int.
| SPEC Int 2006 Application | IPC* | Branches | Stores | Loads |
Total Loads/ Stores |
|---|---|---|---|---|---|
| perlbench | 1.67 | 23 | 12 | 24 | 36 |
| Bzip compression | 1.43 | 15 | 9 | 26 | 35 |
| Gcc | 0.83 | 22 | 13 | 26 | 39 |
| mcf | 0.28 | 19 | 9 | 31 | 40 |
| Go AI | 1.00 | 21 | 14 | 28 | 42 |
| hmmer | 1.67 | 8 | 16 | 41 | 57 |
| Chess | 1.25 | 21 | 8 | 21 | 29 |
| libquantum | 0.43 | 27 | 5 | 14 | 1 |
| h264 encoding | 2.00 | 8 | 12 | 35 | 47 |
| omnetppp | 0.38 | 21 | 18 | 34 | 52 |
| astar | 0.56 | 17 | 5 | 27 | 32 |
| XML processing | 0.66 | 26 | 9 | 32 | 41 |
* IPC as measured on Core 2 Duo.
Libquantum has a relatively high amount of cache misses on most CPUs as it works with a 32MB data set, so it benefits from a larger cache. The 8MB L3 vs 6MB L3 might have boosted performance a bit, but the main reason is vastly improved prefetching inside Bulldozer. According to the researchers of the university of Austin and Microsoft, the prefetch requests in libquantum are very accurate. If you check AMD's own publications you'll notice that there were two major improvements to improve the single-threaded performance of the Bulldozer architecture (compared to the previous ones): an improved Turbo Core and vastly improved prefetching.
Next, let's look at the excellent mcf result. mcf is by far the most memory intensive SPEC CPU Int benchmark out there. mcf misses the L1 data cache about five times more than all the other benchmarks on average. The hit rate is lower than 70%! mcf also misses the last level cache up to eight times more than all other benchmarks. Clearly mcf is a prime candidate to benefit from the vastly improved L/S units of Bulldozer.
Omnetpp is not that extreme, but the instruction mix has 52% loads and stores, and the L2 and last level cache misses are twice as high as the rest of the pack. In contrast to mcf, the amount of branch mispredictions is much lower, despite the fact that it has a similar, relatively high percentage of branches (20%). So the somewhat lower reliance on the memory subsystem is largely compensated for by a much lower amount of branch mispredictions. To be more precise: the amount of branch predictions is about three times lower! This most likely explains why Bulldozer makes a slightly larger step forward in omnetpp compared to the previous AMD architecture than in it does in mcf.
Zooming in on SPEC CPU2006: the Bad
The optimized SPEC CPU2006 int binaries allow gains in the range of 30% to 117%. Unfortunately the complete benchmark suite only shows a gain of 21% when we compare the Opteron 6276 with the 6176. Closer inspection shows that four benchmarks regress. The regression appears to be small in most benchmarks (7 to 14%), but remember that we have 33% more cores. Even a small regression of 7% means that we are losing up to 30% of the previous architecture's single-threaded performance!
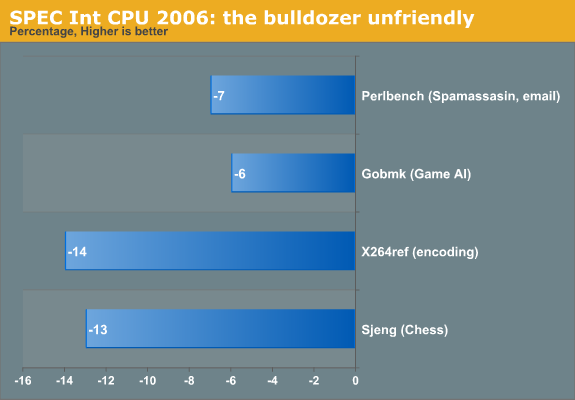
Perlbench has high locality in the L1 and L2 caches and rarely accesses the Last Level Cache, let alone the memory. The result is a benchmark that delivers high IPC: 1.67 on a five year old Core 2 Duo ("Merom"), and close to +/- 1.9 IPC on the latest Intel CPUs. The interesting thing to note is that h264ref and Perlbench are among the top IPC performers in the SPEC CPU2006 suite.
Sjeng (chess) and Gobmk are both Artificial Intelligence subroutines. Again, the IPC is relatively high (>1), but their most important performance characteristic is that they contain a very high percentage of hard to predict branches: twice the average of the SPEC CPU integer suite.
Granted, the evidence we've presented is still circumstantial. It would take an extremely long and intensive profiling session on all new processors to really determine what is going on, and that is beyond our time budget: one SPEC CPU run alone consumes a whole day. However, we did get our hands dirty. A short profiling session on three different benchmarks gives us some very interesting results that we want to discuss next.
IPC Analysis: What Is Going On?
We decided to focus our attention on our MS SQL Server benchmark and profile it on the most important hardware events (IPC, cache, and branch prediction). We used Intel's VTune Amplifier XE 2011 and AMD's Code Analyst 3.4.1037.88 to get a better understand of this benchmark. To put things into perspective, we compared the results with the extremely popular Cinebench benchmark and the 7-Zip compression benchmark.
Note that VTune has a rather steep learning curve and the numbers presented are more detailed but also harder to interprete than those of Code Analyst. In some cases we had doubts about our measurements on the brand spanking new Xeon E5. That is why we are refraining from publishing those numbers until we are absolutely sure they are accurate, so some of the Xeon E5 numbers are missing.
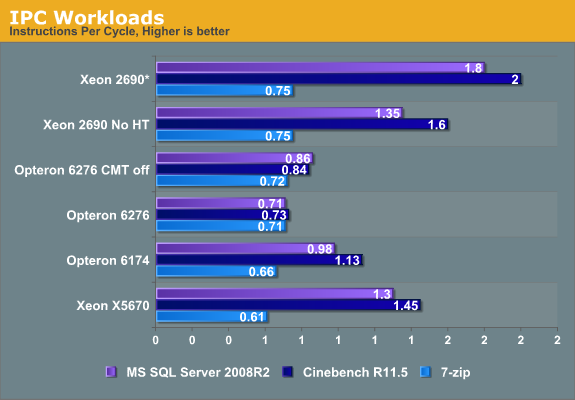
* We add the IPC of the two threads up
It is interesting to note the high Instruction Level Parallelism (ILP) that the Xeon E5 "Sandy Bridge" is able to extract out of these server benchmarks. Almost 1.4 instructions per clock cycle are retired and if you add SMT (Simultaneous Multi Threading), another 0.4 IPC flows through a single core. That is pretty remarkable for a benchmark that consists mostly of SQL statements that result in many branches and loads.
Our Opteron 6200 reveals a bit more about its internal working. Using the extra integer cluster inside the Opteron module causes the separate threads to slow down somewhat. In the case of Cinebench, this is not a real surprise since it contains a lot of SSE floating point commands; a single thread can have the out of order FP cluster all to itself while two threads have to share the SMT capable floating point engine.
But in case of our datamining benchmarks, something else is going on. Single-threaded performance regresses by 18% once you enable the second cluster. We get a 65% speed up (2x 0.71 vs 0.86), which is somewhat lower than the 80% predicted by the AMD slides discussing CMT. So some of the shared resources are slowing down the total performance of our module. We will find out more on the next page.
Caching Analysis
It does not take us long to find a suspect for the lower single-threaded performance of the CMT enabled module: the instruction cache.

The instructions of Cinebench and 7-Zip fit almost perfectly in the instruction cache, but that cannot be said about our MS SQL Server SQL statements. The 8-way 32KB Instruction caches of the latest Intel CPUs are clearly not large enough and shed some light on why the Opteron 6174 performed so well in this benchmark. The older AMD CPU has up to 40% fewer instruction cache misses.
The 2-way 64KB instruction cache was clearly not the optimal choice for caching two threads: the hit rate goes from an excellent 97% down to a mediocre 95% once we enable the second integer thread. It will take some engineering, but increasing the associativity of the L1 instruction cache seems necessary to make sure that the two CMT threads do not hinder each other. Let's move on to the data cache.

Reducing the data cache from 64KB to 16KB was probably necessary in order to keep the die size of the module under control. (A Bulldozer module is less than 80 mm², while two Magny-Cours cores are good for 115 mm².) However this reduction comes with a price: the data cache suffers twice as many misses as before. Intel's 8-way cache does a bit better, but it is not spectacular. Now let's check out the L2 caches.
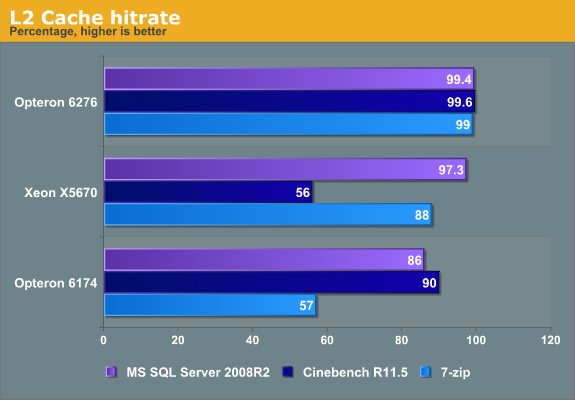
The very low L2 cache hit rates on the older Opteron and Xeon seem like a fluke but that is not the case. In the case of Cinebench, don't forget that this benchmark has an extremely low miss rate in the L1 cache, so most of the easy to cache code and data is already there. The relatively high L2 cache miss rate on the Xeon means that 44% of less than 1% misses the L2 cache--or in other words, almost nothing. The data is almost perfectly cache inside the caches and the data cache hit rate is 99.99%. Most of the L2 cache misses are a few hardly used instructions.
The same is true for the relatively bad hit rate of the Opteron 6174 L2 cache in 7-Zip. The Opteron has a higher L1 data cache hit rate than the other CPUs, so the L2 cache is less accessed. The bad L2 hit rate is not the reason for the lower performance of the older Opteron. Which brings us to the final area of analysis....
Branch Prediction Analysis
The AMD engineers overhauled the branch prediction unit(s) completely in Bulldozer. Did they succeed in closing the gap with Intel, which has had superior branch prediction for years now ? Let us see.
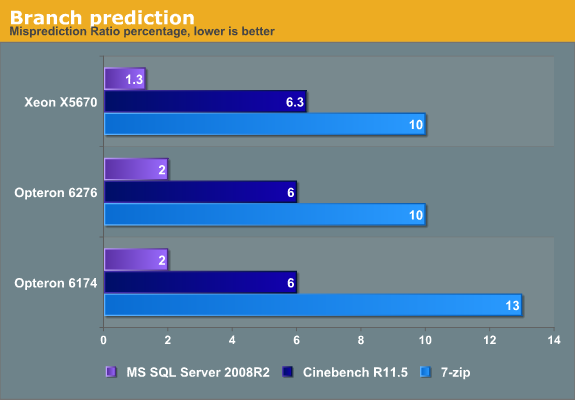
The new Opteron's BPU performs at least as good and sometimes significantly better than old one. This is another component that AMD really got right. However, Intel's BPU clearly wins in SQL Server.
Cache Is Not the Only, Or Even the Main, Culprit
Most people pointed to high latency caches as a reason for subpar Bulldozer performance, but the real explanation of why Bulldozer's performance was underwhelming is a lot more complex. First of all, in most applications, an OOO processor can easily hide the 4-cycle latency of an L1 cache. Intel introduced a 4-cycle latency cache three years ago with their Nehalem architecture, and Intel's engineers claim that simulations show that a 3-cycle L1 would only boost performance by 2-3% (at the same clock), which is peanuts compared to the performance boost that is the result of the higher clock speed headroom.
Secondly, a dedicated 4-way 16KB cache, although relatively small, is hardly worse than Intel's 8-way 32KB data cache that is shared by two threads. The cache is also predicted lowering the power to search, so the Bulldozer data cache organisation does have its advantages.
Considering that SAP and Libquantum tell us that Bulldozer's prefetching works quite well, the 20-cycle L2 cache latency might not be a showstopper after all in server and HPC applications. We noticed also that the large 2MB cache offers (much) higher hit rates than the 512KB L2 cache of the older Istanbul/Magny-Cours cores. So while the L2 cache latency is not an advantage, we definitely have doubts that it is a major factor.
We do agree that it is a serious problem for desktop applications as most of our profiling shows that games and other consumer applications are much more sensitive to L2 cache latency. It was after all one of the reasons why Nehalem was not much faster than the older Penryn based CPUs. Lowly threaded desktop applications run best in a large, low latency L2 cache. But for server applications, we found worse problems than the L2 cache.
The Real Shortcomings: Branch Misprediction Penalty and Instruction Cache Hit Rate
Bulldozer is a deeply pipelined CPU, just like Sandy Bridge, but the latter has a µop cache that can cut the fetching and decoding cycles out of the branch misprediction penalty. The lower than expected performance in SAP and SQL Server, plus the fact that the worst performing subbenches in SPEC CPU2006 int are the ones with hard to predict branches, all points to there being a serious problem with branch misprediction.
Our Code Analyst profiling shows that AMD engineers did a good job on the branch prediction unit: the BPU definitely predicts better than the previous AMD designs. The problem is that Bulldozer cannot hide its long misprediction penalty, which Intel does manage with Sandy Bridge. That also explains why AMD states that branch prediction improvements in "Piledriver" ("Trinity") are only modest (1% performance improvements). As branch predictors get more advanced, a few tweaks here and there cannot do much.
It will be interesting to see if AMD will adopt a µop cache in the near future, as it would lower the branch prediction penalty, save power, and lower the pressure on the decoding part. It looks like a perfect match for this architecture.
Another significant problem is that the L1 instruction cache does not seem to cope well with 2-threads. We have measured significantly higher miss rates once we run two threads on the 2-way 64KB L1 instruction cache. It looks like the associativity of that cache is simply too low. There is a reason why Intel has an 8-way associative cache to run two threads.
Desktop Performance Was Not the Priority
No matter how rough the current implementation of Bulldozer is, if you look a bit deeper, this is not the architecture that is made for high-IPC, branch intensive, lightly-threaded applications. Higher clock speeds and Turbo Core should have made Zambezi a decent chip for enthusiasts. The CPU was supposed to offer 20 to 30% higher clock speeds at roughly the same power consumption, but in the end it could only offer a 10% boost at slightly higher power consumption.
Server Workloads: There Is Hope
If there is one thing this article should have made clear, it's that server applications have completely different demands than SPEC CPU or workstation software. They are much more limited by MLP, come with lower IPC, and are more scalable. They also come with a much larger memory footprint and punish small, low latency caches with high miss rates. Therefore a higher latency but larger L2 cache assisted by good prefetchers can perform adequately.
We strongly believe the concepts behind Bulldozer are sound ones for the professional IT world. The trade-offs are well made for these workloads, but there seem to be four show stoppers. So far we found out that the instruction cache, the branch misprediction penalty, and the lack of clock speed are the main reasons why Bulldozer underperforms in the server world.
The lack of clock speed seems to be addressed in Piledriver with the use of hard edge flops and the resonant clock edge, which is especially useful for clock speeds beyond 3GHz. That means "Abu Dhabi" might be a pleasant surprise. AMD has done it before: in 2007, "Barcelona" (K10 architecture) started at a very dissapointing 2GHz and with worse single-threaded performance than expected. At the end of 2008, a slightly improved version of this architecture (Shanghai) was running at 2.7GHz and had a cache that was three times larger with slightly lower latency. So let's hope that "Abu Dhabi" can repeat the "Shanghai stunt".
But what about the fourth show stopper? That is probably one of the most interesting ones because it seems to show up (in a lesser degree) in Sandy Bridge too. However, we're not quite ready with our final investigations into this area, so you'll have to wait a bit longer. To be continued....






