Original Link: https://www.anandtech.com/show/4061/amds-radeon-hd-6970-radeon-hd-6950
AMD's Radeon HD 6970 & Radeon HD 6950: Paving The Future For AMD
by Ryan Smith on December 15, 2010 12:01 AM ESTThere are only a handful of metrics by which 2009 didn’t end as a successful year for AMD. With the launch of the Radeon HD 5800 series in September of that year AMD got a significant and unusually long-standing jump on the competition. By being the first company to transition a high-end GPU to TSMC’s 40nm process they were able to bring about the next generation of faster and cheaper video cards, quickly delivering better performance at better prices than their 55nm predecessors and competitors alike. At the same time they were the first company to produce a GPU for the new DirectX 11 standard, giving them access to a number of new features, a degree of future proofness, and good will with developers eager to get their hands on DX11 hardware.
Ultimately AMD held the high-end market for over 6 months until NVIDIA was able to counter back with the Fermi based GTX 400 series. Though it’s not unprecedented for a company to rule the high-end market for many months at a time, it’s normally in the face of slower but similar cards from the competition – to stand alone is far more rare. This is not to say that it was easy for AMD, as TSMC’s 40nm production woes kept AMD from fully capitalizing on their advantages until 2010. But even with 40nm GPUs in short supply, it was clearly a good year for AMD.
Now in the twilight of the year 2010, the landscape has once again shifted. NVIDIA did deliver the GTX 400 series, and then they delivered the GTX 500 series, once more displacing AMD from the high-end market as NVIDIA’s build’em big strategy is apt to do. In October we saw AMD reassert themselves in the mid-range market with the Radeon HD 6800 series, delivering performance close to the 5800 series for lower prices and at a greater power efficiency, and provoking a price war that quickly lead to NVIDIA dropping GTX 460 prices. With the delivery of the 6800 series, the stage has been set for AMD’s return to the high-end market with the launch of the Radeon HD 6900 series.
Launching today are the Radeon HD 6970 and Radeon HD 6950, utilizing AMD’s new Cayman GPU. Born from the ashes of TSMC’s canceled 32nm node, Cayman is the biggest change to AMD’s GPU microarchitecture since the original Radeon HD 2900. Just because AMD doesn’t have a new node to work with this year doesn’t mean they haven’t been hard at work, and as we’ll see Cayman and the 6900 series will brings that hard work to the table. So without further ado, let’s dive in to the Radeon HD 6900 series.
| AMD Radeon HD 6970 | AMD Radeon HD 6950 | AMD Radeon HD 6870 | AMD Radeon HD 6850 | AMD Radeon HD 5870 | |
| Stream Processors | 1536 | 1408 | 1120 | 960 | 1600 |
| Texture Units | 96 | 88 | 56 | 48 | 80 |
| ROPs | 32 | 32 | 32 | 32 | 32 |
| Core Clock | 880MHz | 800MHz | 900MHz | 775MHz | 850MHz |
| Memory Clock | 1.375GHz (5.5GHz effective) GDDR5 | 1.25GHz (5.0GHz effective) GDDR5 | 1.05GHz (4.2GHz effective) GDDR5 | 1GHz (4GHz effective) GDDR5 | 1.2GHz (4.8GHz effective) GDDR5 |
| Memory Bus Width | 256-bit | 256-bit | 256-bit | 256-bit | 256-bit |
| Frame Buffer | 2GB | 2GB | 1GB | 1GB | 1GB |
| FP64 | 1/4 | 1/4 | N/A | N/A | 1/5 |
| Transistor Count | 2.64B | 2.64B | 1.7B | 1.7B | 2.15B |
| Manufacturing Process | TSMC 40nm | TSMC 40nm | TSMC 40nm | TSMC 40nm | TSMC 40nm |
| Price Point | $369 | $299 | $239 | $179 | ~$249 |
Following AMD’s unfortunate renaming of its product stack with the Radeon HD 6800 series, the Radeon HD 6900 series is thus far a 3 part, 2 chip lineup. Today we are looking at the Cayman based 6970 and 6950, composing the top of AMD’s single-GPU product line. Above that is Antilles, the codename for AMD’s dual-Cayman Radeon HD 6990. Originally scheduled to launch late this year, the roughly month-long delay of Cayman has pushed that back; we’ll now be seeing the 3rd member of the 6900 series next year. So today the story is all about Cayman and the single-GPU cards it powers.
At the top we have the Radeon HD 6970, AMD’s top single-GPU part. Featuring a complete Cayman GPU, it has 1536 stream processors, 96 texture units, and 32 ROPs. It is clocked at 880MHz for the core clock and 1375MHz (5.5GHz data rate) for its 2GB of GDDR5 RAM. TDP (or the closest thing to it) is 250W, while reflecting the maturity and AMD’s familiarity with the 40nm process typical idle power draw is down from the 5800 series to 20W.

Below that we have the Radeon HD 6950, the traditional lower power card using a slightly cut-down GPU. The 6950 has 1408 stream processors, 88 texture units, and still all 32 ROPs attached to the same 2GB of GDDR5. The core clock is similarly reduced to 800MHz, while the memory clock is 1250MHz (5GHz data rate). TDP is 200W, while idle power is the same as with the 6970 at 20W.
From the specifications alone it’s quickly apparent that something new is happening with Cayman, as at 1536 SPs it has fewer SPs than the 1600 SP Cypress/5870 it replaces. We have a great deal to talk about here, but we’ll stick to a high-level overview for our introduction. In the biggest change to AMD’s core GPU architecture since the launch of their first DX10/unified shader Radeon HD 2900 in 2007, AMD is moving away from the Very Long Instruction Word-5 (VLIW5) architecture we have come to know them for, in favor of a slightly less wide VLIW4 architecture. In a nutshell AMD’s SIMDs are narrower but there are more of them, as AMD looks to find a new balance in their core architecture. Although it’s not a new core architecture outright, the change from VLIW5 to VLIW4 brings a number of ramifications that we will be looking at. And this is just one of the many facets of AMD’s new architecture.
Getting right to the matter of performance, the 6970 performs very close to the GTX 570/480 on average, while the 6950 is in a class of its own, occupying the small hole between the 5870/470 and the 6970/570. With that level of performance the pricing for today’s launch is rather straightforward: the 6970 will be launching slightly above the 570 at $379, while the 6950 will be launching at the $299 sweet spot. Further down the line AMD’s partners will be launching 1GB versions of these cards, which will be bringing prices down as a tradeoff for potential memory bottlenecks.
Today’s launch is going to be hard launch, with both the 6970 and the 6950 available. AMD is being slightly more cryptic than usual about just what the launch quantities are; our official guidance is “available in quantity” and “tens of thousands” of cards. On the one hand we aren’t expecting anything nearly as constrained as the 5800 series launch, and at the same time AMD is not filling us with confidence that it will be widely available like the 6800 either. If at the end of this article you decide you want a 6900 card, your best bet is to grab one sooner than later.

AMD's Current Product Stack
With the launch of the 6900 series, the 5800 series is facing its imminent retirement. There are still a number of cards on the market and they’re priced to move, but AMD is looking at cleaning out its Cypress inventory over the next couple of months, so officially the 5800 series is no longer part of AMD’s current product stack. Meanwhile AMD’s dual-GPU 5970 remains an outlier, as its job is not quite done until the 6990 arrives – until then it’s still officially AMD’s highest-end card and their closest competitor to the GTX 580.
Meanwhile NVIDIA’s product stack and pricing stands as-is.
| Winter 2010 Video Card MSRPs | ||
| NVIDIA | Price | AMD |
| $500 | ||
| $470 | Radeon HD 5970 | |
| $410 | ||
| $369 | Radeon HD 6970 | |
| $350 | ||
| $299 | Radeon HD 6950 | |
|
|
$250 | Radeon HD 5870 |
| $240 | Radeon HD 6870 | |
| $180-$190 | Radeon HD 6850 | |
Refresher: The 6800 Series’ New Features
Back in October AMD launched the first 6000 series cards, the Barts-based Radeon HD 6800 series. At their core they are a refreshed version of the Cypress GPU that we saw on the 5800 series, but AMD used the opportunity to make some enhancements over the standard Cypress. All of these enhancements apply throughout the 6000 series, so this includes the 6900 series. As such for those of you who didn’t pay much attention to the 6800 series, we’re going to quickly recap what’s new in order to lay the groundwork for further comparisons of the 6900 series to the 5800 series.
We’ll start with the core architecture. Compared to Cypress, Barts is nearly identical save 1 difference: the tessellator. For Barts AMD implemented what they call their 7th generation tessellator, which focused on delivering improved tessellation performance at lower tessellation factors that AMD felt were more important. Cayman takes this one step further and implements AMD’s 8th generation tessellator, which as the naming conventions implies is the 7th generation tessellator with even further enhancements (particularly those necessary for load balancing).
The second change we saw with Barts and the 6800 series was AMD’s refined texture filtering engine. AMD’s texture filtering engine from the 5800 set new standards by offering angle independent filtering, but it had an annoying quirk with highly regular/noisy textures where it didn’t do a good enough job blending together various mipmaps, resulting in visible transitions between them. For the 6800 series AMD fixed this, and it can now properly blend together noisy textures. At the same time in a controversial move AMD tweaked its default filtering optimizations for the 5800 series and entire 6000 series, leading to these cards producing imagines subtly different (and depending on who you ask, subtly worse) than they were on the 5800 series prior to the Catalyst 10.10 drivers.

| Radeon HD 5870 | Radeon HD 6870 | GeForce GTX 480 |
The third change we saw was the introduction of a new anti-aliasing mode, initially launched on the 6800 series and backported to the 5800 series shortly thereafter. Morphological Anti-Aliasing (MLAA) is a post-processing filter that works on any (and all) images, looking for high contrast edges (jaggies) and blending them to reduce the contrast. Implemented as a compute shader, it works with all games. As it’s a post-processing filter the results can vary – the filter has no knowledge of depth, polygons, or other attributes of the rendered world beyond the final image – so it’s prone to blending everything that looks like aliasing. On the plus side it’s cheap to use as it was originally designed for consoles with their limited resources, so by not consuming large amounts of memory & memory bandwidth like SSAA/MSAA it usually has a low performance hit.


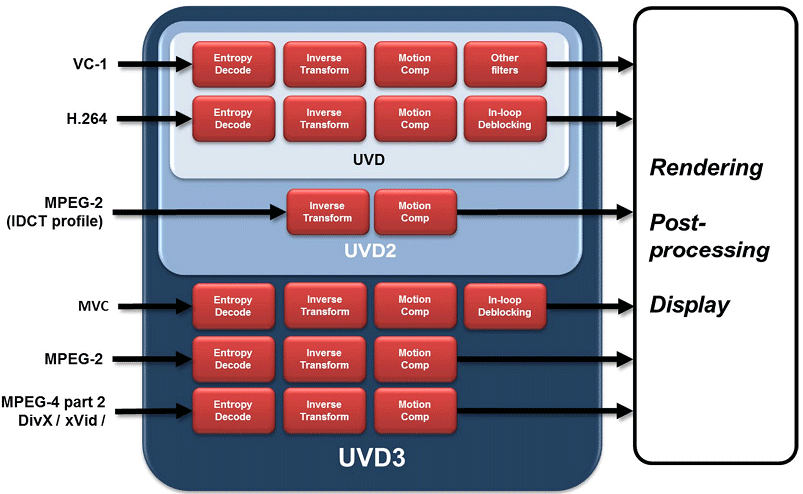
Last but not least, AMD made a number of changes to their display hardware. The Universal Video Decoder (UVD) was upgraded to version 3, bringing full decode support for MPEG-2, MPEG-4 ASP, and H.264 MVC (packed frame video for 3D movies). For the 6900 series this is not of great importance as MPEG-2 and MPEG-4 ASP are low complexity codecs, but it does play an important role for AMD’s future APU products and low-end GPUs, where offloading these low complexity codecs is still going to be a big relief for the slower CPUs they’re paired with. And on that note the first public version of the DivX codec with support for UVD3 will be shipping today, letting 6800/6900 series owners finally take advantage of this functionality.
Click to enlarge
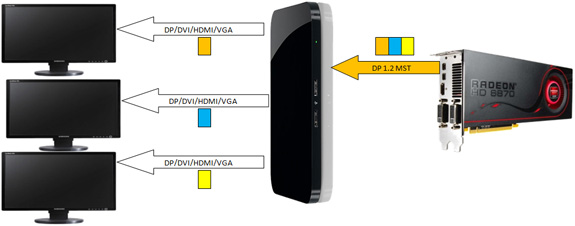
The second of the major display changes was the addition of support for the DisplayPort 1.2 standard. DP1.2 doubles DisplayPort’s bandwidth to 21.6Gbps, finally giving DisplayPort a significant bandwidth lead over dual-link DVI. With double the bandwidth it’s now possible to drive multiple monitors off of a single root DisplayPort, a technology called Multi Stream Transport (MST). AMD is heavily banking on this technology, as the additional bandwidth coupled with the fact that DisplayPort doesn’t require a clock source for each monitor/stream means AMD can drive up to 6 monitors off of a single card using only a pair of mini-DP ports. AMD is so cutting edge here that like the 6800 series the 6900 series is technically only DP1.2 ready – there won’t be any other devices available for compliance testing until 2011.
Finally, the 6800 series also introduced support for HDMI 1.4a and support for color correction in linear space. HDMI 1.4a support is fairly straightforward: the 6000 series can drive 3D televisions in either the 1080p24 or 720p60 3D modes. Meanwhile support for color correction in linear space allows AMD to offer accurate color correction for wide gamut monitors; previously there was a loss of accuracy as color correction had to be applied in the gamma color space, which is only meant for use for display purposes. This is particularly important for integrating wide gamut monitors in to traditional gamut workflows, as sRGB is misinterpreted on a wide gamut monitor without color correction.
While all of these features were introduced on the 6800 series, they’re fundamental parts of the entire 6000 series, meaning they’re part of the 6900 series too. This provides us with a baseline set of improvements over AMD’s 5800 series, on top of the additional improvements Cayman and AMD’s VLIW4 architecture brings.
Cayman: The Last 32nm Castaway
With the launch of the Barts GPU and the 6800 series, we touched on the fact that AMD was counting on the 32nm process to give them a half-node shrink to take them in to 2011. When TSMC fell behind schedule on the 40nm process, and then the 32nm process before canceling it outright, AMD had to start moving on plans for a new generation of 40nm products instead.
The 32nm predecessor of Barts was among the earlier projects to be sent to 40nm. This was due to the fact that before 32nm was even canceled, TSMC’s pricing was going to make 32nm more expensive per transistor than 40nm, a problem for a mid-range part where AMD has specific margins they’d like to hit. Had Barts been made on the 32nm process as projected, it would have been more expensive to make than on the 40nm process, even though the 32nm version would be smaller. Thus 32nm was uneconomical for gaming GPUs, and Barts was moved to the 40nm process.
Cayman on the other hand was going to be a high-end part. Certainly being uneconomical is undesirable, but high-end parts carry high margins, especially if they can be sold in the professional market as compute products (just ask NVIDIA). As such, while Barts went to 40nm, Cayman’s predecessor stayed on the 32nm process until the very end. The Cayman team did begin planning to move back to 40nm before TSMC officially canceled the 32nm process, but if AMD had a choice at the time they would have rather had Cayman on the 32nm process.
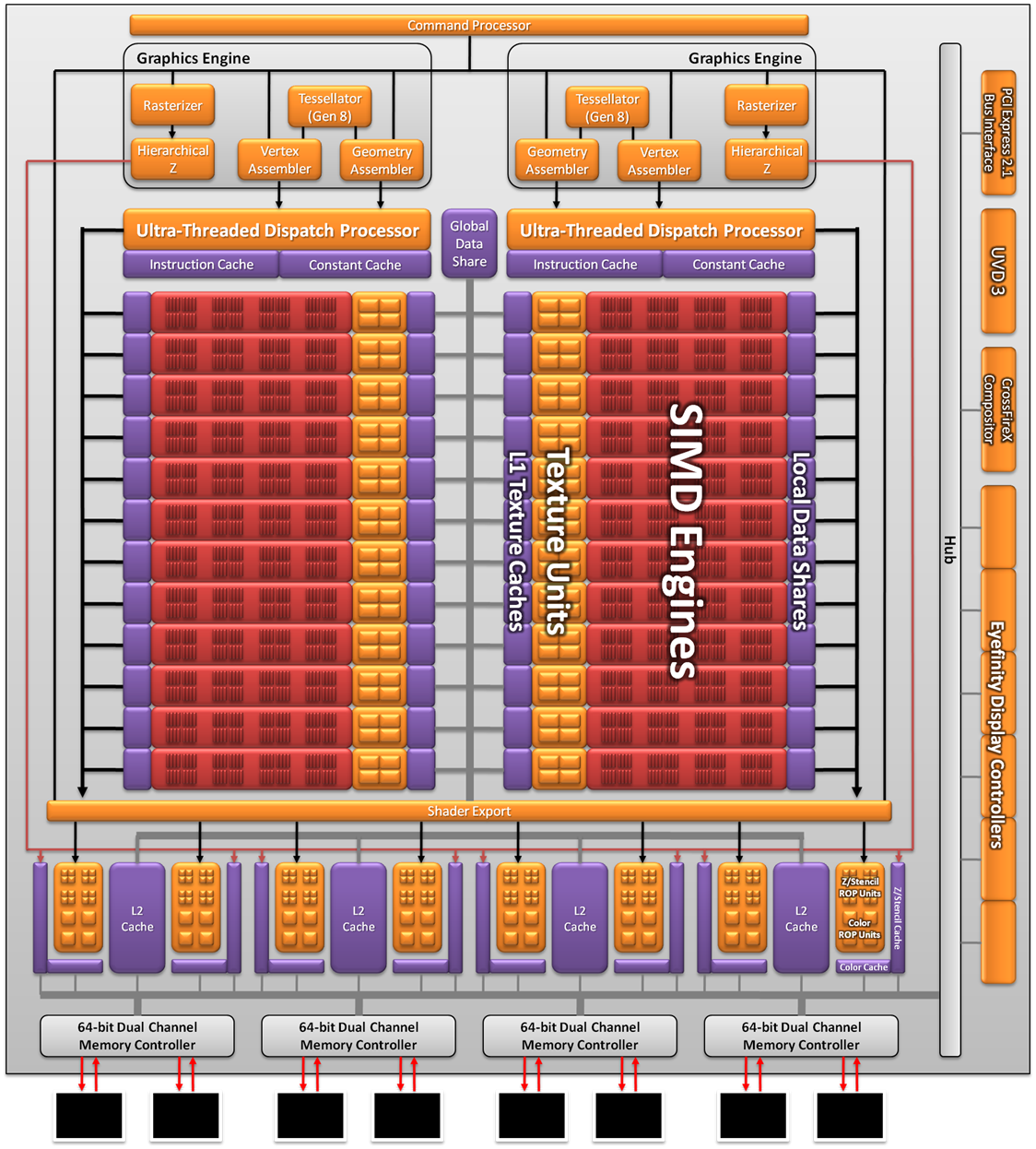
As a result the Cayman we’re seeing today is not what AMD originally envisioned as a 32nm part. AMD won’t tell us everything that they had to give up to create the 40nm Cayman (there has to be a few surprises for 28nm) but we do know a few things. First and foremost was size; AMD’s small die strategy is not dead, but getting the boot from the 32nm process does take the wind out of it. At 389mm2 Cayman is the largest AMD GPU since the disastrous R600, and well off the sub-300mm2 size that the small die strategy dictates. In terms of efficient usage of space though AMD is doing quite well; Cayman has 2.64 billion transistors, 500mil more than Cypress. AMD was able to pack 29% more transistors in only 16% more space.
Even then, just reaching that die size is a compromise between features and production costs. AMD didn’t simply settle for a larger GPU, but they had to give up some things to keep it from being even larger. SIMDs were on the chopping block; 32nm Cayman would have had more SIMDs for more performance. Features were also lost, and this is where AMD is keeping mum. We know PCI Express 3.0 functionality was scheduled for the 32nm part, where AMD had to give up their PCIe 3.0 controller for a smaller 2.1 controller to make up for their die size difference. This in all honesty may have worked out better for them: PCIe 3.0 ended up being delayed until November, so suitable motherboards are still at least months away.
The end result is that Cayman as we know it is a compromise to make it happen on 40nm. AMD got their new VLIW4 architecture, but they had to give up performance and an unknown number of features to get there. On the flip side this will make 28nm all the more interesting, as we’ll get to see many of the features that were supposed to make it for 2010 but never arrived.
VLIW4: Finding the Balance Between TLP, ILP, and Everything Else
To properly frame why AMD went with a VLIW4 design we’d have to first explain why AMD went with a VLIW5 design. And to do that we’d have to go back even further to the days of DirectX 9, and thus that is where we will start.
Back in the days of yore, when shading was new and pixel and vertex shaders were still separate entities, AMD (née ATI) settled on a VLIW5 design for their vertex shaders. Based on their data this was deemed the ideal configuration for a vertex shader block, as it allowed them to process a 4 component dot product (e.g. w, x, y, z) and a scalar component (e.g. lighting) at the same time.
Fast forward to 2007 and the introduction of AMD’s Radeon HD 2000 series (R600), where AMD introduced their first unified architecture for the PC. AMD went with a VLIW5 design once more, as even though the product was their first DX10 product it still made sense to build something that could optimally handle DX9 vertex shaders. This was also well before GPGPU had a significant impact on the market, as AMD had at best toyed around with the idea late in the X1K series’ lifetime (and well after R600 was started).

Now let us jump to 2008, when Cayman’s predecessors were being drawn up. GPGPU computing is still fairly new – NVIDIA is at the forefront of a market that only amounts to a few million dollars at best – and DX10 games are still relatively rare. With 2+ years to bring up a GPU, AMD has to be looking forward at where things will be in 2010. Their predictions are that GPGPU computing will finally become important, and that DX9 games will fade in importance to DX10/11 games. It’s time to reevaluate VLIW5.
This brings us to the present day and the launch of Cayman. GPGPU computing is taking off, and DX10 & DX11 alongside Windows 7 are gaining momentum while DX9 is well past its peak. AMD’s own internal database of games tells them an interesting story: the average slot utilization is 3.4 – on average a 5th streaming processor is going unused in games. VLIW5, which made so much sense for DX9 vertex shaders is now becoming too wide, while scalar and narrow workloads are increasing in number. The stage is set for a narrower Streaming Processor Unit; enter VLIW4.
As you may recall from a number of our discussions on AMD’s core architecture, AMD’s architecture is heavily invested in Instruction Level Parallelism, that is having instructions in a single thread that have no dependencies on each other that can be executed in parallel. With VLIW5 the best case scenario is that 5 instructions can be scheduled together on every SPU every clock, a scenario that rarely happens. We’ve already touched on how in games AMD is seeing an average of 3.4, which is actually pretty good but still is under 80% efficient. Ultimately extracting ILP from a workload is hard, leading to a wide delta between the best and worst case scenarios.
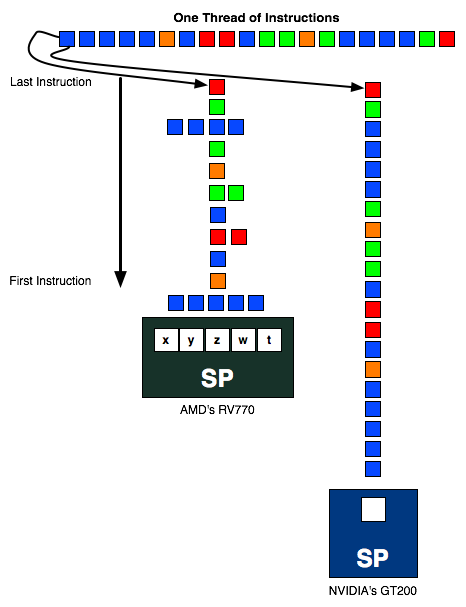
Meanwhile all of this is in stark contrast to Thread Level Parallelism (TLP), which looks for threads that can be run at the same time without having any interdependencies. This is where NVIDIA has focused their energies at the high-end, as GF100/GF100 are both scalar architectures that rely on TLP to achieve efficient operation.
Ultimately the realization is that AMD’s VLIW5 architecture is not the best architecture going forward. Up until now it has made sense at a high efficiency gaming-oriented design, and even today in a gaming part like the 6800 series it’s still a reasonable choice. But AMD needs a new architecture for the future, not only as something that’s going to better fit their 3.4 shader average, but something that is better designed for compute workloads. AMD’s choice is an overhauled version of their existing architecture. Overall it’s built on a solid foundation, but VLIW5 is too wide to meet their future goals.
The solution is to shrink their VLIW5 SPU to a VLIW4 SPU. Specifically, the solution is to remove the t-unit, the architecture’s 5th SP and largest SP that’s capable of both regular INT/FP operations as well as being responsible for transcendental operations. In the case of regular INT/FP operations this means an SPU is reduced from being able to process 5 operations at once to 4. While in the case of transcendentals an SPU now ties together 3 SPs to process 1 transcendental in the same period of time, representing a much more severe reduction in theoretical performance as an SPU can only process 1 transcendental + 1 INT/FP per clock as opposed to 1 transcendental + 4 INT/FP operations (or any variations).
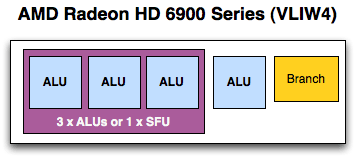
There are a number of advantages to this change. As far as compute is concerned, the biggest advantage is that much of the space previously allocated to the t-unit can now be scrounged up to build more SIMDs. Cypress had 20 SIMDs while Cayman has 24; on average Cayman’s shader block is 10% more efficient per mm2 than Cypress’s , taking in to account the fact that Cayman’s SPs are a bit larger than Cypress’ to pick up the workload the t-unit would handle. The SIMDs are further tied to a number of attributes: the number of texture units, the number of threads that can be in flight at once, and the number of FP64 operations that can be completed per clock. The latter is particularly important for AMD’s compute efforts, as they can now retire FP64 FMA/MUL operations at 1/4th their FP32 rate, in the case of a full Cayman up to 384/clock. Technically speaking they’re no faster per SPU, but with this layout change they have more SPUs to work with, improving their performance.
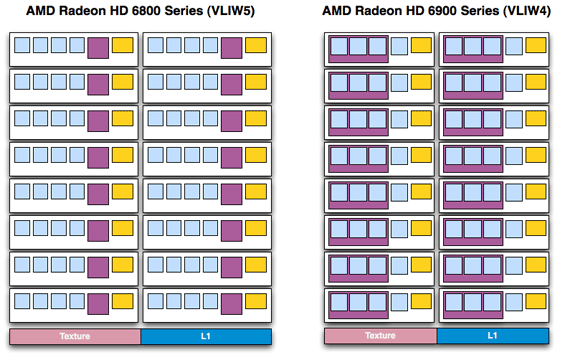
Fewer SPs per SIMD = More Space For More SIMDs
There are even ancillary benefits within the individual SPUs. While the SP count changed the register file did not, leading to less pressure on each SPU’s registers as now only 4 SPs vie for register space. Even scheduling is easier as there are fewer SPs to schedule and the fact that they’re all alike means the scheduler no longer has to take into consideration the difference between the w/x/y/z units and the t-unit.
Meanwhile in terms of gaming the benefits are similar. Games that were already failing to fully utilize the VLIW5 design now have additional SIMDs to take advantage of, and as rendering is still an embarrassingly parallel operation as far as threading is concerned, it’s very easy to further divide the rendering workload in to more threads to take advantage of this change. The extra SIMDs mean that Cayman has additional texturing horsepower over Cypress, and the overall compute:texture ratio has been reduced, a beneficial situation for any games that are texture/filtering bound more than they’re compute bound.
Of course any architectural change involves tradeoffs, so it’s not a pure improvement. For gaming the tradeoff is that Cayman isn’t going to be well suited to VLIW5-style vertex shaders; generally speaking games using such shaders already run incredibly fast, but if they’re even GPU-bound in the first place they’re not going to gain much from Cayman. The other big tradeoff is when transcendental operations are paired with vector operations, as Cypress could handle both in one clock while Cayman will take two. It’s AMD’s belief that these operations are rare enough that the loss of performance in this one situation is worth it for the gain in performance everywhere else.
It’s worth noting that AMD still considers VLIW4 to be a risky/experimental design, or at least this is their rationale for going with it first on Cayman while sticking to VLIW5 elsewhere. At this point we’d imagine the real experiment to already be over, as AMD would already be well in the middle of designing Cayman’s 28nm successor, so they undoubtedly know if they’ll be using VLIW4 in the future.
Finally, the switch to a new VLIW architecture means the AMD driver team has to do some relearning. While VLIW4 is quite similar to VLIW5 it’s not by any means identical, which is both good and bad for performance purposes. The bad news is that it means many of AMD’s VLIW5-centric shader compiler tricks are no longer valid; at the start shader compiler performance is going to be worse while AMD learns how to better program a VLIW4 design. The good news is that in time they’re going to learn how to better program a VLIW4 design, meaning there’s the potential for sizable performance increases throughout the lifetime of the 6900 series. That doesn’t mean they’re guaranteed, but we certainly expect at least some improvement in shader performance as the months wear on.
On that note these VLIW changes do mean that some code is going to have to be rewritten to better deal with the reduction of VLIW width. AMD’s shader compiler goes through a number of steps to try to optimize code, but if kernels were written specifically to organize instructions to go through AMD’s shaders in a 5-wide fashion, then there’s only so much AMD’s compiler can do. Of course code doesn’t have to be written that way, but it is the best way to maximize ILP and hence shader performance.
VLIW5:
- 4 32-bit FP MAD
- Or 2 64-bit FP MUL or ADD
- Or 1 64-bit FP MAD
- Or 4 24-bit Int MUL or ADD
- Plus 1 transcendental or 1 32-bit FP MAD
VLIW4:
- 4 32-bit FP MAD/MUL/ADD
- Or 2 64-bit FP ADD
- Or 1 64-bit FP MAD/FMA/MUL
- Or 4 24-bit INT MAD/MUL/ADD
- Or 4 32-bit INT ADD/Bitwise
- Or 1 32-bit MAD/MUL
- Or 1 64-bit ADD
- Or 1 transcendental plus 1 32-bit FP MAD
Cayman: The New Dawn of AMD GPU Computing
We’ve already covered how the shift from VLIW5 to VLIW4 is beneficial for AMD’s computing efforts: narrower SPUs are easier to fully utilize, FP64 performance improves to 1/4th FP32 performance, and the space savings give AMD room to lay down additional SIMDs to improve performance. But if Cayman is meant to be a serious effort by AMD to relaunch themselves in to the GPU computing market and to grab a piece of NVIDIA’s pie, it takes more than just new shaders to accomplish the task. Accordingly, AMD has been hard at work to round out the capabilities of their latest GPU to make it a threat for NVIDIA’s Fermi architecture.
AMD’s headline compute feature is called asynchronous dispatch, a long word that actually does a pretty good job of describing what it does. To touch back on Fermi for a moment, with Fermi NVIDIA introduced support for parallel kernels, giving Fermi the ability to execute multiple kernels at once. AMD in turn is following NVIDIA’s approach of executing multiple kernels at once, but is going to take it one step further.
The limit of NVIDIA’s design is that while Fermi can execute multiple kernels at once, each one must come from the same CPU thread. Independent threads/applications for example cannot issue their own kernels and have them execute in parallel, rather the GPU must context switch between them. With asynchronous dispatch AMD is going to allow independent threads/applications to issue kernels that execute in parallel. On paper at least, this would give AMD’s hardware a significant advantage in this scenario (context switching is expensive), one that would likely eclipse any overall performance advantages NVIDIA had.
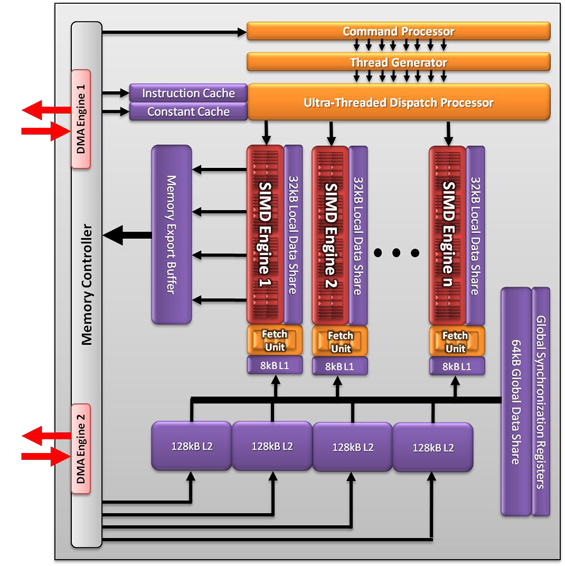
Fundamentally asynchronous dispatch is achieved by having the GPU hide some information about its real state from applications and kernels, in essence leading to virtualization of GPU resources. As far as each kernel is concerned it’s running in its own GPU, with its own command queue and own virtual address space. This places more work on the GPU and drivers to manage this shared execution, but the payoff is that it’s better than context switching.
For the time being the catch for asynchronous dispatch is that it requires API support. As DirectCompute is a fixed standard this just isn’t happening – at least not with DirectCompute 11. Asynchronous dispatch will be exposed under OpenCL in the form of an extension.
Meanwhile the rest of AMD’s improvements are focusing on memory and cache performance. While the fundamental architecture is not changing, there are several minor changes here to improve compute performance. The Local Data Store attached to each SIMD is now able to bypass the cache hierarchy and Global Data Store by having memory fetches read directly in to the LDS. Meanwhile Cayman is getting a 2nd DMA engine, improving memory reads & writes by allowing Cayman to execute two at once in each direction.
Finally, read ops from shaders are being sped up a bit. Compared to Cypress, Cayman can coalesce them in to fewer operations.
As today’s launch is primarily about the Radeon HD 6900 series AMD isn’t going too much in depth on the compute side of things, so everything here is a fairly high level overview of the architecture. Once AMD has Firestream cards ready to go with Cayman in them, there will likely be more to talk about.
Advancing Primitives: Dual Graphics Engines & New ROPs
AMD has clearly taken NVIDIA’s comments on geometry performance to heart. Along with issuing their manifesto with the 6800 series, they’ve also been working on their own improvements for their geometry performance. As a result AMD’s fixed function Graphics Engine block is seeing some major improvements for Cayman.
Prior to Cypress, AMD had 1 graphics engine, which contained 1 each of the fundamental blocks: the rasterizers/hierarchical-Z units, the geometry/vertex assemblers, and the tessellator. With Cypress AMD added a 2nd rasterizer and 2nd hierarchical-Z unit, allowing them to set up 32 pixels per clock as opposed to 16 pixels per clock. However while AMD doubled part of the graphics engine, they did not double the entirety of it, meaning their primitive throughput rate was still 1 primitive/clock, a typical throughput rate even at the time.
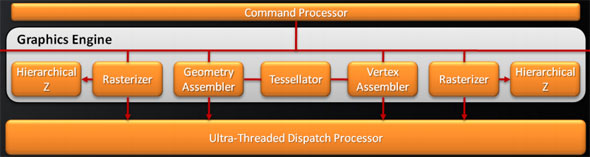
Cypress's Graphics Engine
In 2010 with the launch of Fermi, NVIDIA raised the bar on primitive performance, with rasterization moved to NVIDIA’s GPCs, NVIDIA could theoretically push out as many primitives/clock as they had GPCs, in the case of GF100/GF110 pushing this to 4 primitives/clock, a simply massive improvement in geometry performance for a single generation.
With Cayman AMD is catching up with NVIDIA by increasing their own primitive throughput rate, though not by as much as NVIDIA did with Fermi. For Cayman the rest of the graphics engine is being fully duplicated – Cayman will have 2 separate graphics engines, each containing one fundamental block, and each capable of pushing out 1 primitive/clock. Between the two of them AMD’s maximum primitive throughput rate will now be 2 primitives/clock; half as much as NVIDIA but twice that of Cypress.
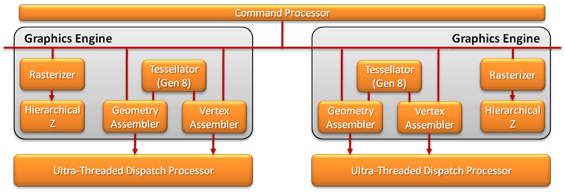
Cayman's Dual Graphics Engines
As was the case for NVIDIA, splitting up rasterization and tessellation is not a straightforward and easy task. For AMD this meant teaching the graphics engine how to do tile-based load balancing so that the workload being spread among the graphics engines is being kept as balanced as possible. Furthermore AMD believes they have an edge on NVIDIA when it comes to design - AMD can scale the number of eraphics engines at will, whereas NVIDIA has to work within the logical confines of their GPC/SM/SP ratios. This tidbit would seem to be particularly important for future products, when AMD looks to scale beyond 2 graphics engines.
At the end of the day all of this tinking with the graphics engines is necessary in order for AMD to further improve their tessellation performance. AMD’s 7th generation tessellator improved their performance at lower tessellation factors where the tessellator was the bottleneck, but at higher tessellation factors the graphics engine itself is the bottleneck as the graphics engine gets swamped with more incoming primitives than it can set up in a single clock. By having two graphics engines and a 2-primitive/clock rasterization rate, AMD is shifting the burden back away from the graphics engine.
Just having two 7th generation-like tessellators goes a long way towards improving AMD’s tessellation performance. However all of that geometry can still lead to a bottleneck at times, which means it needs to be stored somewhere until it can be processed. As AMD has not changed any cache sizes for Cayman, there’s the same amount of cache for potentially thrice as much geometry, so in order to keep things flowing that geometry has to go somewhere. That somewhere is the GPU’s RAM, or as AMD likes to put it, their “off-chip buffer.” Compared to cache access RAM is slow and hence this isn’t necessarily a desirable action, but it’s much, much better than stalling the pipeline entirely while the rasterizers clear out the backlog.
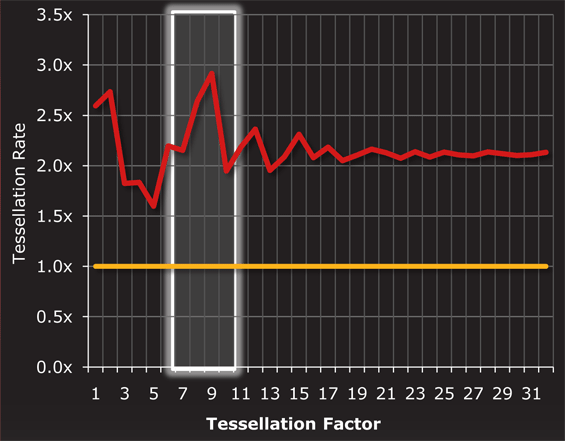
Red = 6970. Yellow = 5870
Overall, clock for clock tessellation performance is anywhere between 1.5x and 3x that of Cypress. In situations where AMD’s already improved tessellation performance at lower tessellation factors plays a part, AMD approaches 3x performance; while at around a factor of 5 the performance drops to near 1.5x. Elsewhere performance is around 2x that of Cypress, representing the doubling of graphics engines.
Tessellation also plays a factor in AMD’s other major gaming-related improvement: ROP performance. As tessellation produces many mini triangles, these triangles begin to choke the ROPs when performing MSAA. Although tessellation isn’t the only reason, it certainly plays a factor in AMD’s reasoning for improving their ROPs to improve MSAA performance.
The 32 ROPs (the same as Cypress) have been tweaked to speed up processing of certain types of values. In the case of both signed and unsigned normalized INT16s, these operations are now 2x faster. Meanwhile FP32 operations are now 2x to 4x faster depending on the scenario. Finally, similar to shader read ops for compute purposes, ROP write ops for graphics purposes can be coalesced, improving performance by requiring fewer operations.
Redefining TDP With PowerTune
One of our fundamental benchmarks is FurMark, oZone3D’s handy GPU load testing tool. The furry donut can generate a workload in excess of anything any game or GPGPU application can do, giving us an excellent way to establish a worst case scenario for power usage, GPU temperatures, and cooler noise. The fact that it was worse than any game/application has ruffled both AMD and NVIDIA’s feathers however, as it’s been known to kill older cards and otherwise make their lives more difficult, leading to the two companies labeling the program a “power virus”.
FurMark is just one symptom of a larger issue however, and that’s TDP. Compared to their CPU counterparts at only 140W, video cards are power monsters. The ATX specification allows for PCIe cards to draw up to 300W, and we quite regularly surpass that when FurMark is in use. Things get even dicier on laptops and all-in-one computers, where compact spaces and small batteries limit how much power a GPU can draw and how much heat can effectively be dissipated. For these reasons products need to be designed to meet a certain TDP; in the case of desktop cards we saw products such as the Radeon HD 5970 where it had sub-5870 clocks to meet the 300W TDP (with easy overvolting controls to make up for it), and in laptop parts we routinely see products with many disabled functional units and low clocks to meet those particularly low TDP requirements.
Although we see both AMD and NVIDIA surpass their official TDP on FurMark, it’s never by very much. After all TDP defines the thermal limits of a system, so if you regularly surpass those limits it can lead to overwhelming the cooling and ultimately risking system damage. It’s because of FurMark and other scenarios that AMD claims that they have to set their products’ performance lower than they’d like. Call of Duty, Crysis, The Sims 3, and other games aren’t necessarily causing video cards to draw power in excess of their TDP, but the need to cover the edge cases like FurMark does. As a result AMD has to plan around applications and games that cause a high level of power draw, setting their performance levels low enough that these edge cases don’t lead to the GPU regularly surpassing its TDP.
This ultimately leads to a concept similar to dynamic range, defined by Wikipedia as: “the ratio between the largest and smallest possible values of a changeable quantity.” We typically use dynamic range when talking about audio and video, referring to the range between quiet and loud sounds, and dark and light imagery respectively. However power draw is quite similar in concept, with a variety of games and applications leading to a variety of loads on the GPU. Furthermore while dynamic range is generally a good thing for audio and video, it’s generally a bad thing for desktop GPU usage – low power utilization on a GPU-bound game means that there’s plenty of headroom for bumping up clocks and voltages to improve the performance of that game. Going back to our earlier example however, a GPU can’t be set this high under normal conditions, otherwise FurMark and similar applications will push the GPU well past TDP.
The answer to the dynamic power range problem is to have variable clockspeeds; set the clocks low to keep power usage down on power-demanding games, and set the clocks high on power-light games. In fact we already have this in the CPU world, where Intel and AMD use their turbo modes to achieve this. If there’s enough thermal and power headroom, these processors can increase their clockspeeds by upwards of several steps. This allows AMD and Intel to not only offer processors that are overall faster on average, but it lets them specifically focus on improving single-threaded performance by pushing 1 core well above its normal clockspeeds when it’s the only core in use.
It was only a matter of time until this kind of scheme came to the GPU world, and that time is here. Earlier this year we saw NVIDIA lay the groundwork with the GTX 500 series, where they implemented external power monitoring hardware for the purpose of identifying and slowing down FurMark and OCCT; however that’s as far as they went, capping only FurMark and OCCT. With Cayman and the 6900 series AMD is going to take this to the next step with a technology called PowerTune.
PowerTune is a power containment technology, designed to allow AMD to contain the power consumption of their GPUs to a pre-determined value. In essence it’s Turbo in reverse: instead of having a low base clockspeed and higher turbo multipliers, AMD is setting a high base clockspeed and letting PowerTune cap GPU performance when it exceeds AMD’s TDP. The net result is that AMD can reduce the dynamic power range of their GPUs by setting high clockspeeds at high voltages to maximize performance, and then letting PowerTune cap GPU performance for the edge cases that cause GPU power consumption to exceed AMD’s preset value.
PowerTune, Cont
PowerTune’s functionality is accomplished in a two-step process. The first step is defining the desired TDP of a product. Notably (and unlike NVIDIA) AMD is not using power monitoring hardware here, citing the costs of such chips and the additional design complexities they create. Instead AMD is profiling the performance of their GPUs to determine what the power consumption behavior is for each functional block. This behavior is used to assign a weighted score to each functional block, which in turn is used to establish a rough equation to find the power consumption of the GPU based on each block’s usage.
AMD doesn’t provide the precise equations used, but you can envision it looking something like this:
Power Consumption =( (shaderUsage * shaderWeight) + (ropUsage * ropWeight) + (memoryUsage * memoryWeight) ) * clockspeed
In the case of the Radeon HD 6970, the TDP is 250W, while the default clockspeed is 880MHz.
With a power equation established, AMD can then adjust GPU performance on the fly to keep power consumption under the TDP. This is accomplished by dynamically adjusting just the core clock based on GPU usage a few times a second. So long as power consumption stays under 250W the 6970 stays at 880MHz, and if power consumption exceeds 250W then the core clock will be brought down to keep power usage in check.
It’s worth noting that in practice the core clock and power usage do not have a linear relationship, so PowerTune may have to drop the core clock by quite a bit in order to maintain its power target. The memory clock and even the core voltage remain unchanged (these are only set with PowerPlay states), so PowerTune only has the core clock to work with.
Ultimately PowerTune is going to fundamentally change how we measure and classify AMD’s GPUs. With PowerTune the TDP really is the TDP; as a completely game/application agonistic way of measuring and containing power consumption, it’s simply not possible to exceed the TDP. The power consumption of the average game is still below the TDP – sometimes well below – so there’s still an average case and a worst case scenario to discuss, but the range between them just got much smaller.
Furthermore as a result, real world performance is going to differ from theoretical performance that much more. Just as is the case with CPUs where the performance you get is the performance you get; teraFLOPs, cache bandwidth, and clocks alone won’t tell you everything about the performance of a product. The TDP and whether the card regularly crosses it will factor in to performance, just as how cooling factors in to CPU performance by allowing/prohibiting higher turbo modes. At least for AMD’s GPUs, we’re now going to be talking about how much performance you can get for any given TDP instead of specific clockspeeds, bringing performance per watt to the forefront of importance.
So by now you’re no doubt wondering what the impact of PowerTune is, and the short answer is that there’s virtually no impact. We’ve gone ahead and compiled a list of all the games and applications in our test suite, and whether they triggered PowerTune throttling. Of the dozen tests, only two triggered PowerTune: FurMark as expected, and Metro 2033. Furthermore as you can see there was a significant difference between the average clockspeed of our 6970 in these two situations.
| AMD Radeon HD 6970 PowerTune Throttling | |||
| Game/Application | Throttled? | ||
| Crysis: Warhead | No | ||
| BattleForge | No | ||
| Metro | Yes (850Mhz) | ||
| HAWX | No | ||
| Civilization V | No | ||
| Bad Company 2 | No | ||
| STALKER | No | ||
| DiRT 2 | No | ||
| Mass Effect 2 | No | ||
| Wolfenstein | No | ||
| 3DMark Vantage | Yes | ||
| MediaEspresso 6 | No | ||
| Unigine Heaven | No | ||
| FurMark | Yes (600MHz) | ||
| Distributed.net Client | No | ||
In the case of Metro the average clockspeed was 850MHz; Metro spent 95% of the time running at 880MHz, and only at a couple of points did the core clock drop to around 700MHz. Conversely FurMark, a known outlier, drove the average core clock down to 600MHz for a 30% reduction in the core clock. So while PowerTune definitely had an impact on FurMark performance it did almost nothing to Metro, never mind any other game/application. To illustrate the point, here are our Metro numbers with and without PowerTune.
| Radeon HD 6970: Metro 2033 Performance | ||||
| PowerTune 250W | PowerTune 300W | |||
| 2560x1600 | 25.5 | 26 | ||
| 1920x1200 | 39 | 39.5 | ||
| 1680x1050 | 64.5 | 65 | ||
The difference is no more than .5fps on average, which may as well be within our experimental error range for this benchmark. For everything we’ve tested on the 6970 and the 6950, the default PowerTune settings do not have a meaningful performance impact on any game or application we test. Thus at this point we’re confident that there are no immediate drawbacks to PowerTune for desktop use.
Ultimately this is a negative feedback mechanism, unlike Turbo which is a positive feedback mechanism. Without overclocking the best a 6970 will run at is 880MHz, whereas Turbo would increase clockspeeds when conditions allow. Neither one is absolutely the right way to do things, but there’s a very different perception when performance is taken away, versus when performance is “added” for free. I absolutely like where this is going – both as a hardware reviewer and as a gamer – but I’d be surprised if this didn’t generate at least some level of controversy.
Finally, while we’ve looked at PowerTune in the scope of desktop usage, we’ve largely ignored other cases so far. AMD will be the first to tell you that PowerTune is more important for mobile use than it is desktop use, and mobile use is all the more important as the balance between desktops and laptops sold continues to slide towards laptops. In the mobile space not only does PowerTune mean that AMD will absolutely hit their TDPs, but it should allow them to produce mobile GPUs that come with higher stock core clocks, comfortable in the knowledge that PowerTune will keep power usage in check for the heaviest games and applications. The real story for PowerTune doesn’t even begin until 2011 – as far as the 6900 series is concerned, this may as well be a sneak peak.
Even then there’s one possible exception we’re waiting to see: 6990 (Antilles). The Radeon HD 5970 put us in an interesting spot: it was and still is the fastest card around, but unless you can take advantage of CrossFire it’s slower than a single 5870, a byproduct of the fact that AMD had to use lower core and memory clocks to make their 300W TDP. This is in stark comparison to the 4870X2, which really was 2 4870s glued together with the same single GPU performance. With PowerTune AMD doesn’t necessarily need to repeat the 5970’s castrated clocks; they could make a 6970X2, and let PowerTune clip performance as necessary to keep it under 300W. If something is being used without CrossFire for example, then there’s no reason not to run the 1 GPU at full speed. It would be the best of both worlds.
In the meantime we’re not done with PowerTune quite yet. PowerTune isn’t just something AMD can set – it’s adjustable in the Overdrive control panel too.
Tweaking PowerTune
While the primary purpose of PowerTune is to keep the power consumption of a video card within its TDP in all cases, AMD has realized that PowerTune isn’t necessarily something everyone wants, and so they’re making it adjustable in the Overdrive control panel. With Overdrive you’ll be able to adjust the PowerTune limits both up and down by up to 20% to suit your needs.
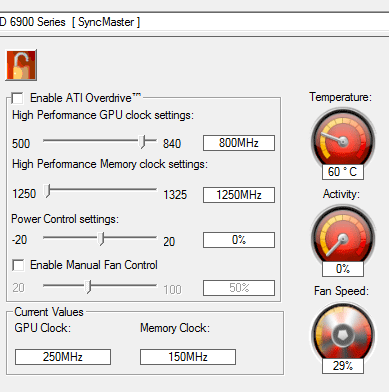
We’ll start with the case of increasing the PowerTune limits. While AMD does not allow users to completely turn off PowerTune, they’re offering the next best thing by allowing you to increase the PowerTune limits. Acknowledging that not everyone wants to keep their cards at their initial PowerTune limits, AMD has included a slider with the Overdrive control panel that allows +/- 20% adjustment to the PowerTune limit. In the case of the 6970 this means the PowerTune limit can be adjusted to anywhere between 200W and 300W, the latter being the ATX spec maximum.
Ultimately the purpose of raising the PowerTune limit depends on just how far you raise it. A slight increase can bring a slight performance advantage in any game/application that is held back by PowerTune, while going the whole nine yards to 20% is for all practical purposes disabling PowerTune at stock clocks and voltages.
We’ve already established that at the stock PowerTune limit of 250W only FurMark and Metro 2033 are PowerTune limited, with only the former limited in any meaningful way. So with that in mind we increased our PowerTune limit to 300W and re-ran our power/temperature/noise tests to look at the full impact of using the 300W limit.
| Radeon HD 6970: PowerTune Performance | ||||
| PowerTune 250W | PowerTune 300W | |||
| Crysis Temperature | 78 | 79 | ||
| Furmark Temperature | 83 | 90 | ||
| Crysis Power | 340W | 355W | ||
| Furmark Power | 361W | 422W | ||
As expected, power and temperature both increase with FurMark with PowerTune at 300W. At this point FurMark is no longer constrained by PowerTune and our 6970 runs at 880MHz throughout the test. Overall our power consumption measured at the wall increased by 60W, while the core clock for FurMark is 46.6% faster. It was under this scenario that we also “uncapped” PowerTune for Metro, when we found that even though Metro was being throttled at times, the performance impact was impossibly small.
Meanwhile we found something interesting when running Crysis. Even though Crysis is not impacted by PowerTune, Crysis’ power consumption still crept up by 15W. Performance is exactly the same, and yet here we are with slightly higher power consumption. We don’t have a good explanation for this at this point – PowerTune only affects the core clock (and not the core voltage), and we never measured Crysis taking a hit at 250W or 300W, so we’re not sure just what is going on. However we’ve already established that FurMark is the only program realistically impacted by the 250W limit, so at stock clocks there’s little reason to increase the PowerTune limit.
This does bring up overclocking however. Due to the limited amount of time we had with the 6900 series we have not been able to do a serious overclocking investigation, but as clockspeed is a factor in the power equation, PowerTune is going to impact overclocking. You’re going to want to raise the PowerTune limit when overclocking, otherwise PowerTune is liable to bring your clocks right back down to keep power consumption below 250W. The good news for hardcore overclockers is that while AMD set a 20% limit on our reference cards, partners will be free to set their own tweaking limits – we’d expect high-end cards like the Gigabyte SOC, MSI Lightning, and Asus Matrix lines to all feature higher limits to keep PowerTune from throttling extreme overclocks.
Meanwhile there’s a second scenario AMD has thrown at us for PowerTune: tuning down. Although we generally live by the “more is better” mantra, there is some logic to this. Going back to our dynamic range example, by shrinking the dynamic power range power hogs at the top of the spectrum get pushed down, but thanks to AMD’s ability to use higher default core clocks, power consumption of low impact games and applications goes up. In essence power consumption gets just a bit worse because performance has improved.
Traditionally V-sync has been used as the preferred method of limiting power consumption by limiting a card’s performance, but V-sync introduces additional input lag and the potential for skipped frames when triple-buffering is not available, making it a suboptimal solution in some cases. Thus if you wanted to keep a card at a lower performance/power level for any given game/application but did not want to use V-sync, you were out of luck unless you wanted to start playing with core clocks and voltages manually. By being able to turn down the PowerTune limits however, you can now constrain power consumption and performance on a simpler basis.
As with the 300W PowerTune limit, we ran our power/temperature/noise tests with the 200W limit to see what the impact would be.
| Radeon HD 6970: PowerTune Performance | ||||
| PowerTune 250W | PowerTune 200W | |||
| Crysis Temperature | 78 | 71 | ||
| Furmark Temperature | 83 | 71 | ||
| Crysis Power | 340W | 292W | ||
| Furmark Power | 361W | 292W | ||
Right off the bat everything is lower. FurMark is now at 292W, and quite surprisingly Crysis is also at 292W. This plays off of the fact that most games don’t cause a card to approach its limit in the first place, so bringing the ceiling down will bring the power consumption of more power hungry games and applications down to the same power consumption levels as lesser games/applications.
Although not whisper quiet, our 6970 is definitely quieter at the 200W limit than the default 250W limit thanks to the lower power consumption. However the 200W limit also impacts practically every game and application we test, so performance is definitely going to go down for everything if you do reduce the PowerTune limit by the full 20%.
| Radeon HD 6970: PowerTune Crysis Performance | ||||
| PowerTune 250W | PowerTune 200W | |||
| 2560x1600 | 36.6 | 28 | ||
| 1920x1200 | 51.5 | 43.3 | ||
| 1680x1050 | 63.3 | 52 | ||
At 200W, you’re looking at around 75%-80% of the performance for Crysis. The exact value will depend on just how heavy of a load the specific game/application was in the first place.
Another New Anti-Aliasing Mode: Enhanced Quality AA
With the 6800 series AMD introduced Morphological Anti-Aliasing (MLAA), a low-complexity post-processing anti-aliasing filter. As a post-processing filter it worked with a wide variety of games and APIs, and in most cases the performance overhead was not very severe. However it’s not the only new anti-aliasing mode that AMD has been working on.
New with the 6900 series is a mode AMD is calling Enhanced Quality Anti-Aliasing. If you recall NVIDIA’s Coverage Sample Anti-Aliasing (CSAA) introduced with the GeForce 8800GTX, then all of this should sound quite familiar – in fact it’s basically the same thing.
Under traditional MSAA, for a pixel covered by 2 or more triangles/fragments, 2, 4, or 8 subpixel samples are taken to determine what the final pixel should be. In the process the color of the triangle and the Z/depth of the triangle are both sampled and stored, and at the end of the process the results are blended together to determine the final pixel value. This process works well for resolving aliasing along polygon edges at a fraction of the cost of true super sampling, but it’s still expensive. Collecting and storing the Z and color values requires extra memory to store the values and extra memory bandwidth to work with the values. Ultimately while we need enough samples to determine colors of the involved triangles, we do not always need a great deal of them. With a few color/Z samples we have all of the color data we need in most cases, however the “hard” part of anti-aliasing becomes what the proper blending of color values should be.
1 Pixel Covred by 2 Triangles/Fragments
Thus we have EQAA, a compromise on the idea. Color/Z samples are expensive, but just checking if a triangle covers part of a subpixel is very cheap. If we have enough color/Z samples to get the necessary color information, then just doing additional simple subpixel coverage checks would allow us better determine what percentage of a pixel is covered by a given polygon, which we can then use to blend colors in a more accurate fashion. For example with 4x MSAA we can only determine if a pixel is 0/25/50/75/100 percent covered by a triangle, but with 4x EQAA where we take 4 color samples and then 4 additional coverage-only samples, we can determine blending values down to 0/12/25/37/50/62/75/87/100 percent coverage, the same amount of accuracy as using 8x MSAA. Thus in the right situation we can have quality similar to 8x MSAA for only a little over 4x MSAA’s cost.
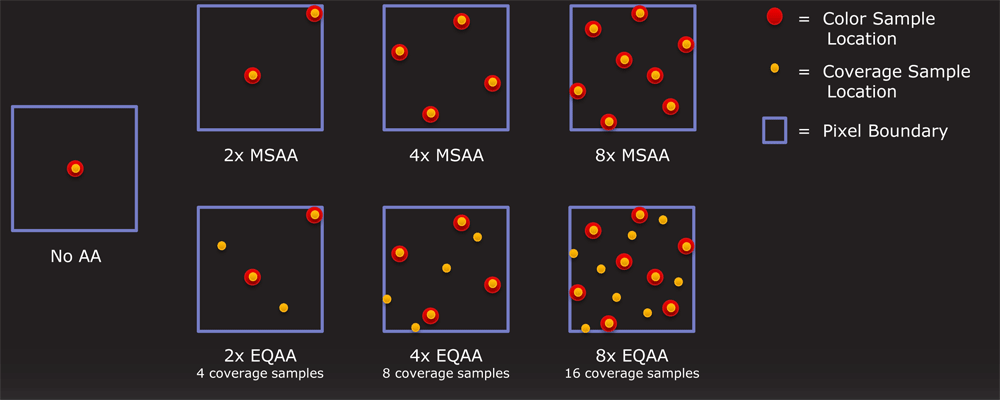
MSAA & EQAA Sample Patterns
In reality of course this doesn’t always work out as well. The best case scenario is that the additional coverage samples are almost as good as having additional color/Z samples, while the worst case scenario is that additional coverage samples are practically worthless. This depends on a game-by-game, if not pixel-by-pixel basis. In practice additional coverage samples are a way to slightly improve MSAA quality for a very, very low cost.
While NVIDIA has had the ability to take separate coverage samples since G80, AMD has not had this ability until now. With the 6900 hardware their ROPs finally gain this ability.
Beyond that, AMD and NVIDIA’s implementations are nearly identical except for the naming convention. Both can take a number of coverage samples independent of the color/Z samples based on the setting used; the only notable difference we’re aware of is that like AMD’s other AA modes, their EQAA mode can be programmed to use a custom sample pattern.
As is the case with NVIDIA’s CSAA, AMD’s EQAA mode is available to DirectX applications or can be forced through the drivers. DirectX applications can set it through the Multisample Quality attribute, which is usually abstracted to list the vendor’s name for the mode in a game’s UI. Otherwise it can be forced via the Catalyst Control Center, either by forcing an AA mode, or as is the case with NVIDIA, enhancing the AA mode by letting the game set the AA mode while the driver overrides the game and specifies different Multisample Quality attribute. Thus the “enhance application settings” AA mode is new to AMD with the 6900 series.
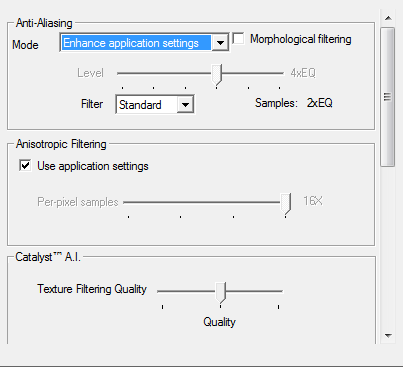
To be honest we’re a bit ruffled by the naming choice. True, NVIDIA did go and have to pick daft names for their CSAA modes (when is 8x not 8 sample MSAA?), but ultimately CSAA and EQAA are virtually identical. NVIDIA has a 4 year lead on AMD here, and we’d just as well use NVIDIA’s naming conventions for consistency. Instead we have the following.
| Coverage Sampling Modes: CSAA vs EQAA | ||||
| NVIDIA |
Mode (Color + Coverage) |
AMD | ||
| 2x | 2+0 | 2x | ||
| N/A | 2+2 | 2xEQ | ||
| 4x | 4+0 | 4x | ||
| 8x | 4+4 | 4xEQ | ||
| 16x | 4+12 | N/A | ||
| 8xQ | 8+0 | 8x | ||
| 16xQ | 8+8 | 8xEQ | ||
| 32x | 8+24 | N/A | ||
AMD ends up having 1 mode NVIDIA doesn’t, 2xEQ, which is 2x MSAA + 2x cover samples; meanwhile NVIDIA has 16x (4x MSAA + 12 cover samples) and 32x (8x MSAA + 24 cover samples). Finally, as we’ll see, just as is the case for NVIDIA additional coverage samples are equally cheap for AMD.
Meet the 6970 & 6950
Now that we’ve finally looked at what makes the 6900 series tick, let’s look at the cards themselves.
If you’re familiar with the 6800 series, then the 6900 series is nearly identical. For our reference cards AMD is using the same style they used for the 6800 cards, utilizing a completely shrouded and squared off design. Furthermore unlike the 5800 series AMD is utilizing the same cooler/PCB/layout for both the 6970 and 6950, meaning virtually everything we have to say about one card applies to the other as well. In this case we’ll be using the 6970 as our point of reference.

Top: 5870. Bottom: 6970
Starting with the length, the 6970 measures a hair over 10.5”, giving it the same length as the 5870. Buyers looking for a 5850-like shorter card will have to look elsewhere else for the moment, as the 6950 is the same 10.5”. Power is provided by a set of 6+8pin PCIe power sockets at the top of the card, necessary as the 6970’s 250W TDP is in excess of the 225W 6+6 limit. The 6950 on the other hand does use 6+6 PCIe power sockets in the same location, afforded by its lower 200W TDP.

Cracking open the 6970 we find the PCB with the Cayman GPU at the center in all its 389mm2 glory. Around it are 8 2Gb Hynix GDDR5 chips, rated for 6Gbps, 0.5Gbps higher than what the card actually runs at. As we’ve said before the hardest part about using GDDR5 at high speeds is the complexity of building a good memory bus, and this continues to be the case here. AMD has made progress on getting GDDR5 speeds up to 5.5Gbps primarily through better PCB designs, but it looks like hitting 6Gbps and beyond is going to be impractical, at least for a 256bit bus design. Ultimately GDDR5 was supposed to top out at 7Gbps, but with the troubles both AMD and NVIDIA have had, we don’t expect anyone will ever reach it.

Moving on to the cooling apparatus, vapor chamber coolers are clearly in vogue this year. AMD already used a vapor chamber last year on the dual-GPU 5970, while this year both AMD and NVIDIA are using them on their high-end single-GPU products. Compared to a more traditional heatpipe cooler, a vapor chamber cooler is both more efficient than a heatpipe cooler and easier to build in to a design as there’s no need to worry about where to route the heatpipes. Meanwhile airflow is provided by a blower at the rear of the card; compared to the 5870 the blower on the 6970 is just a bit bigger, a fair consideration given that the 6970 is a hotter card. Interestingly in spite of the higher TDP AMD has still been able to hold on to the half-height exhaust port at the front of the card.

As for I/O we’re looking at AMD’s new port layout as seen on the 6800 series: 2x DVI, 1x HDMI 1.4, and 2x mini-DP. All together the 6970 can drive up to 6 monitors through the use of the mini-DP ports and a MST hub. Compared to the 5800 series the DVI-type ports have a few more restrictions however; along with the usual limitation of only being able to drive 2 DVI-type monitors at once, AMD has reduced the 2nd DVI port to a single-link port (although it maintains the dual-link pin configuration), so you won’t be able to drive 2 2560 or 3D monitors using DVI ports.

Elsewhere the card features 2 CrossFire connectors at the top, allowing for tri-CF for the particularly rich and crazy. Next to the CF connectors you’ll find AMD’s not-so-secret switch, which controls the cards’ switchable BIOSes. The card has 2 BIOSes, which can be changed with the flick of a switch. The primary purpose of this switch is to offer a backup BIOS in case of a failed BIOS flash, as it’s possible to boot the card with the secondary BIOS and then switch back to the primary BIOS after the computer has started in order to reflash it. Normally AMD doesn’t strike us as very supportive of BIOS flashing, so this is an interesting change.

The BIOS Switch
Like the 5870 the back side is covered with a metal plate, and while there aren’t any components on the back side of the card to protect, this is a nice touch by making it easier to grab the card without needing to worry about coming in contact with a pointy contact.
Finally, while the card’s overall dimensions are practically identical to the 5870, we noticed that the boxy design isn’t doing AMD any favors when it comes to CrossFire mode with 2 cards right next to each other. The 5870’s shroud actually jutted out just a bit at the center, keeping the ventilation hole for the blower from pressing right up against the back of another card. The 6970 does not have this luxury, meaning it’s possible to practically seal the upper card depending on how you screw the cards down. As a result our CF temperatures run high, but not to a troublesome degree. We’d still encourage AMD to take a page from NVIDIA’s book and to bring the shroud in a bit around the blower so that it has more room to breathe, particularly as their TDP is approaching NVIDIA’s. In the meantime we’d definitely suggest spacing your cards apart if you have a motherboard and case that allows it.
The Test
For the launch of the Radeon HD 6900 series, AMD supplied us with a 6900-enabled version of the Catalyst 10.11 driver, version 8.79.6.2RC2. This is older than the Catalyst 10.12 preview released Monday, which was 8.8xx.
Otherwise our test setup has not significantly changed from the GTX 570 launch last week. For our existing AMD cards we’re still using the Catalyst 10.10e, while for NVIDIA it’s a mix of 262.99 and 263.09. Note that we do not have a 2nd GTX 570 yet for GTX 570 SLI comparisons; given the equality between the 570 and 480, the GTX 480 in SLI is a reasonable stand-in.
Finally, all tests were done with the default driver settings unless otherwise noted.
| CPU: | Intel Core i7-920 @ 3.33GHz |
| Motherboard: | Asus Rampage II Extreme |
| Chipset Drivers: | Intel 9.1.1.1015 (Intel) |
| Hard Disk: | OCZ Summit (120GB) |
| Memory: | Patriot Viper DDR3-1333 3 x 2GB (7-7-7-20) |
| Video Cards: |
AMD Radeon HD 6970 AMD Radeon HD 6950 AMD Radeon HD 6870 AMD Radeon HD 6850 AMD Radeon HD 5970 AMD Radeon HD 5870 AMD Radeon HD 5850 AMD Radeon HD 5770 AMD Radeon HD 4870 NVIDIA GeForce GTX 580 NVIDIA GeForce GTX 570 NVIDIA GeForce GTX 480 NVIDIA GeForce GTX 470 NVIDIA GeForce GTX 460 1GB NVIDIA GeForce GTX 460 768MB NVIDIA GeForce GTS 450 NVIDIA GeForce GTX 285 NVIDIA GeForce GTX 260 Core 216 |
| Video Drivers: |
NVIDIA ForceWare 262.99 NVIDIA ForceWare 263.09 AMD Catalyst 10.10e AMD Catalyst 8.79.6.2RC2 |
| OS: | Windows 7 Ultimate 64-bit |
Crysis: Warhead
Kicking things off as always is Crysis: Warhead, still one of the toughest game in our benchmark suite. Even 2 years since the release of the original Crysis, “but can it run Crysis?” is still an important question, and the answer continues to be “no.” While we’re closer than ever, full Enthusiast settings at a playable framerate is still beyond the grasp of a single card.


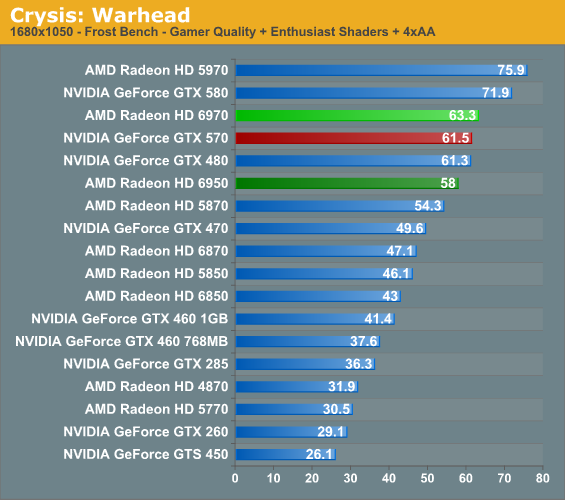
Crysis starts things off well for AMD. Keeping an eye on 2560 and 1920, not only does the 6970 start things off with a slight lead over NVIDIA’s GTX 570, but even the cheaper 6950 holds parity. In the case of the 6900 series it also hits a special milestone at 2560, being the first AMD single-GPU cards to surpass 30fps. This also gives us our first inkling of 6950 performance relative to 5870 performance – as expected the 6950 is faster, but at 5-10% not fantastically so. Crysis does push in excess of 2mil polygons/frame, but the 6900 series’ improvements are best suited for when tessellation is in use.
Meanwhile our CrossFire setups are unusually close, with barely 2fps separating the 6970CF and 6950CF. It’s unlikely we’re CPU limited at 2560, so we may be looking at being ROP-limited, as the ROPs are the only constant between the two cards.

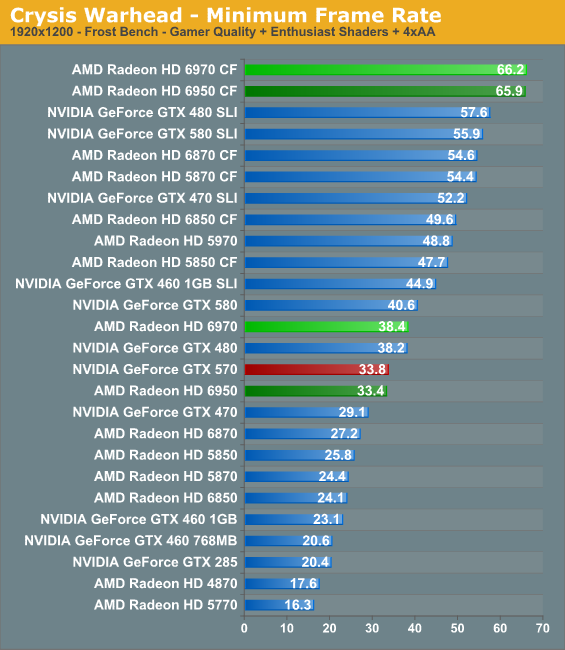

With 2GB of RAM our AMD cards finally break out of the minimum framerate crash Crysis experiences with 1GB AMD cards. Our rankings are similar to our averages, with the 6970 taking a small lead while the 6950 holds close to the 570.
BattleForge: DX10
Up next is BattleForge, Electronic Arts’ free to play online RTS. As far as RTSes go this game can be quite demanding, and this is without the game’s DX11 features.


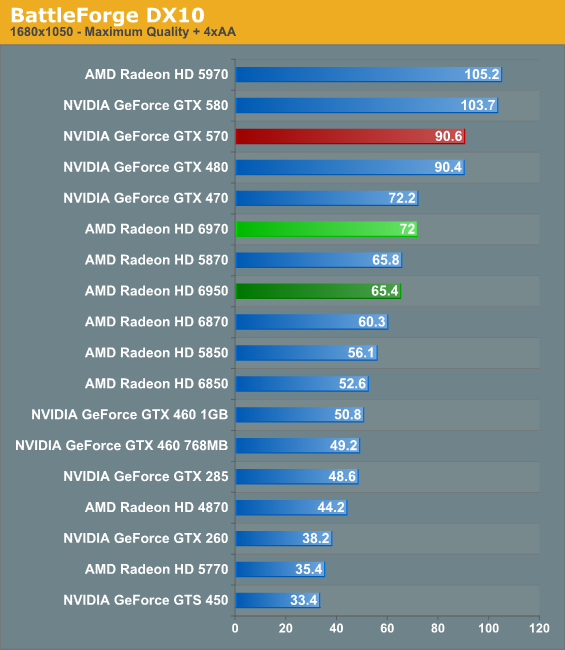
With BattleForge the situation immediately reverses for AMD and then some. The GTX 570 takes a commanding lead over both AMD cards; worse, the 5870 and the 6950 are effectively tied. We routinely see BattleForge show up as a shader-bound benchmark, so it stands to reason that the potential loss in shader performance on the Cayman architecture would hurt AMD here. This would certainly explain why the 6950 can’t gain any ground on the 5870.
Metro 2033
The next game on our list is 4A Games’ Metro 2033, their tunnel shooter released earlier this year. In September the game finally received a major patch resolving some outstanding image quality issues with the game, finally making it suitable for use in our benchmark suite. At the same time a dedicated benchmark mode was added to the game, giving us the ability to reliably benchmark much more stressful situations than we could with FRAPS. If Crysis is a tropical GPU killer, then Metro would be its underground counterpart.

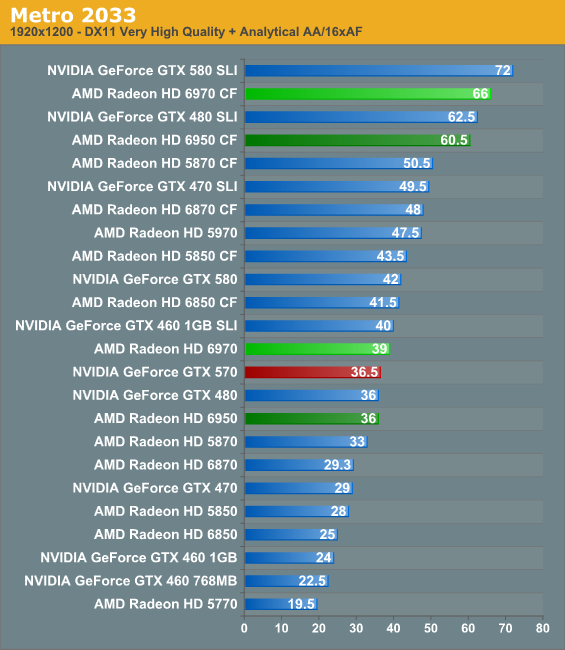

The Crysis comparison seems particularly apt here, as our rankings closely mirror Crysis. The 6970 takes a small lead over the GTX 570, while the 6950 rides shotgun with the GTX 570. Note that none of these single-GPU cards, not even the GTX 580, get exceptionally good framerates at 1920 or 2560, so we have to resort to CF/SLI to get there. CF/SLI makes things all the more interesting, as any kind of parity the GTX 400/500 series has goes right out the window at 2560. AMD simply outscales NVIDIA here, leading to the 6970 CF surpassing the mighty 580 SLI by 30%. Reality reasserts itself at 1920 however where we end up with a more typical order.
HAWX
Ubisoft’s 2008 aerial action game is one of the less demanding games in our benchmark suite, particularly for the latest generation of cards. However it’s fairly unique in that it’s one of the few flying games of any kind that comes with a proper benchmark.
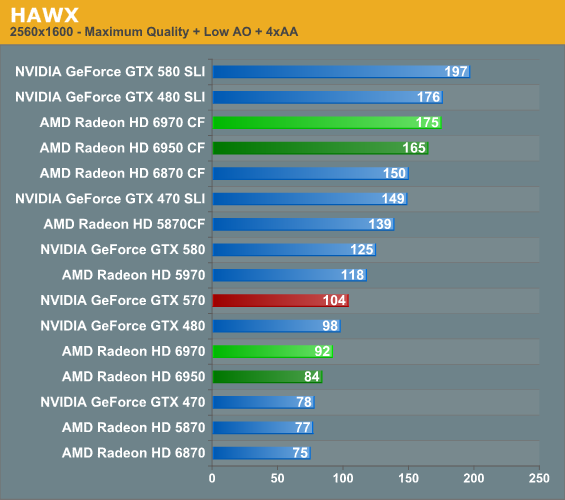
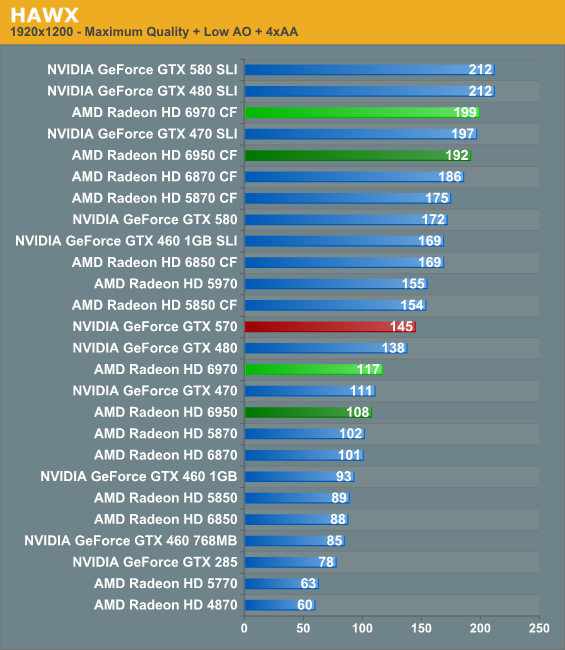

HAWX is a game that traditionally favors NVIDIA, so there aren’t any major surprises here. At 2560 the gap is nearly 10% between the 6970 and 570, while it grows to 20% at 1920. The difference is largely academic – I’m not sure even NVIDIA’s DX10 SSAA mode can make HAWX anything but buttery smooth – but it’s an area where the Radeon consistently falls up short. Meanwhile CrossFire and SLI scaling is almost equal here, leading to even more ridiculous framerates but no change in ranking.
Civilization V
The other new game in our benchmark suite is Civilization 5, the latest incarnation in Firaxis Games’ series of turn-based strategy games. Civ 5 gives us an interesting look at things that not even RTSes can match, with a much weaker focus on shading in the game world, and a much greater focus on creating the geometry needed to bring such a world to life. In doing so it uses a slew of DirectX 11 technologies, including tessellation for said geometry and compute shaders for on-the-fly texture decompression.



Once more Civilization V throws us a curveball, with some interesting results. At 2560 we’re GPU limited to the point where the 6900 series pulls ahead of the 5870, while at 1920 there’s something going on that doesn’t sit well with Civ V, leading to sub-5870 performance. In any case this is another game where NVIDIA traditionally does well, leading to even the fast 6900 series coming in well below the GTX 570 and even the GTX 470. AMD’s CrossFire scaling reigns supreme however, giving all the CF configurations an edge over their NVIDIA counterparts.
Battlefield: Bad Company 2
The latest game in the Battlefield series - Bad Company 2 – remains as one of the cornerstone DX11 games in our benchmark suite. As BC2 doesn’t have a built-in benchmark or recording mode, here we take a FRAPS run of the jeep chase in the first act, which as an on-rails portion of the game provides very consistent results and a spectacle of explosions, trees, and more.
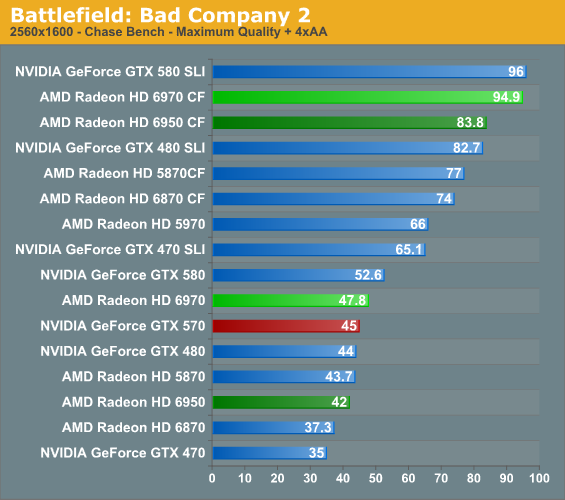

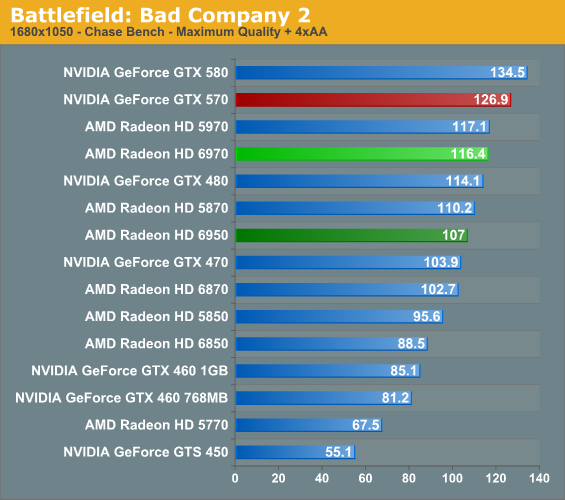
Bad Company 2 has ended up being a rather balanced game. Neither AMD or NVIDIA GPUs end up being favored giving us performance close to our global average. At higher resolutions the 6970 can meet or beat the GTX 570, while we have to drop to 1680 for the 570 to take a real lead. Meanwhile the 6970 CF is but a hair’s width away from the GTX 580 SLI.
Curiously this is another game where the 5870 holds an advantage over the 6950. Bad Company 2 is another game that normally appears shader-bound, so this may be an outcome from AMD’s shader change. At the same time it’s a very recent game, so it shouldn’t have any particular attachment to the older VLIW5 design.
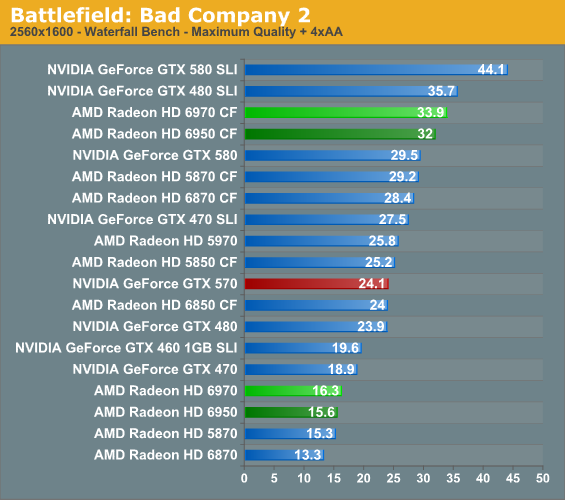
As for our Water benchmark, it produces disappointing result for the 6900 series. AMD has simply never done well here and the 6900 cards don’t seem to have what it takes to break that curse. The result is that while the averages are close, the worst case scenario of minimum framerates looks much worse for AMD.
STALKER: Call of Pripyat
The third game in the STALKER series continues to build on GSC Game World’s X-Ray Engine by adding DX11 support, tessellation, and more. This also makes it another one of the highly demanding games in our benchmark suite.

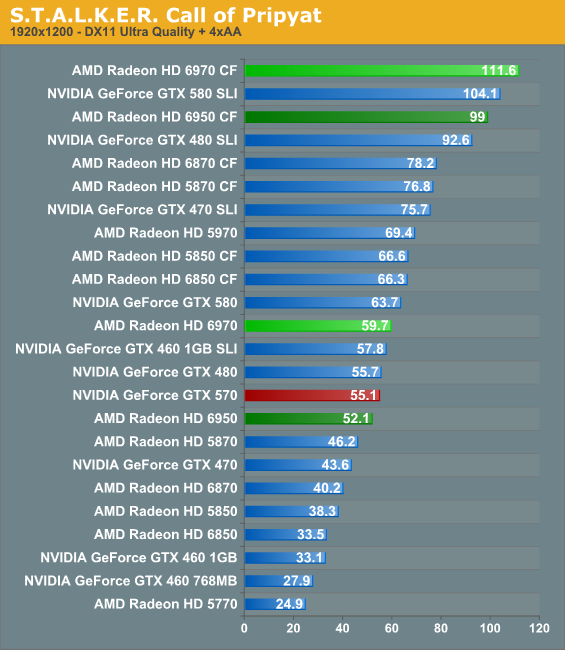
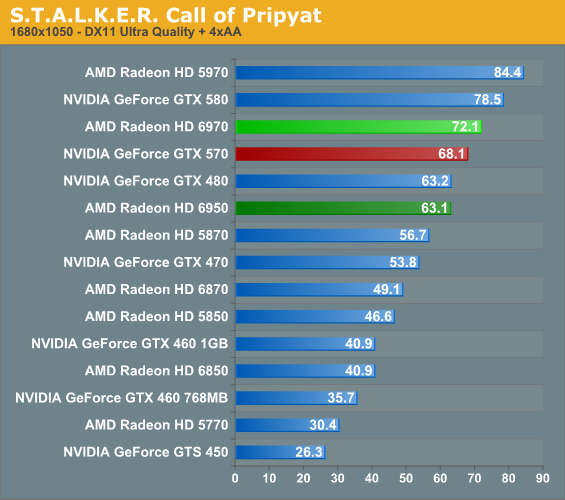
It’s when we finally get to STALKER, a game that uses significant tessellation, that we see the 6900 stretch out its legs and shine. Once more compared to the GTX 570 the 6950 is close to or meets it in performance while the 6970 takes anywhere from an 8%-20% lead and threatens the GTX 580. But the real story is the 6900 series versus the 5870; the 6950 enjoys a 15% lead while the 6970 is anywhere between 30% and 50% faster depending on the resolution. Between the game’s high memory requirements and its use of tessellation, the 6900 has a very clear advantage over the 5870. It’s situations like these where AMD’s forward looking architecture is meeting a forward looking game.
DIRT 2
Codemasters’ 2009 off-road racing game continues its reign as the token racer in our benchmark suite. As the first DX11 racer, DiRT 2 makes pretty thorough use of the DX11’s tessellation abilities, not to mention still being the best looking racer we have ever seen.



With DIRT 2 we’re back to another game that heavily favors NVIDIA GPUs. The 6970 can at least close in on the GTX 570 at 2560, but at 1920 all bets are off. Meanwhile the 6950 gains practically nothing over the 5870, even though DIRT 2 is a game that uses tessellation.
Mass Effect 2
Electronic Arts’ space-faring RPG is our Unreal Engine 3 game. While it doesn’t have a built in benchmark, it does let us force anti-aliasing through driver control panels, giving us a better idea of UE3’s performance at higher quality settings. Since we can’t use a recording/benchmark in ME2, we use FRAPS to record a short run.

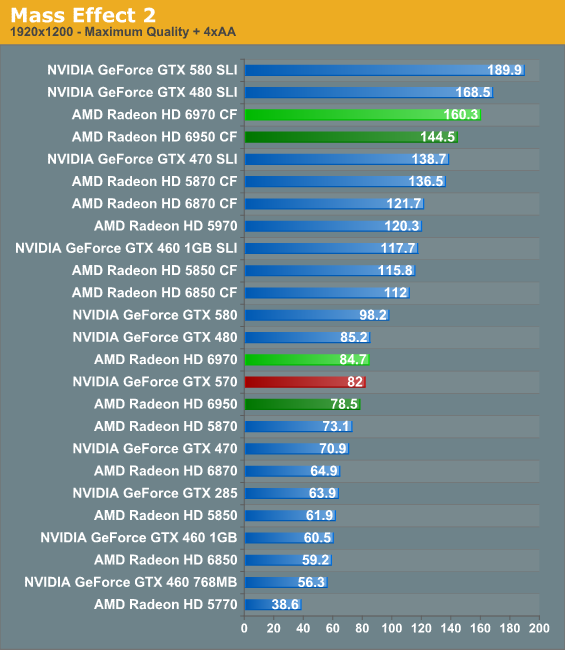
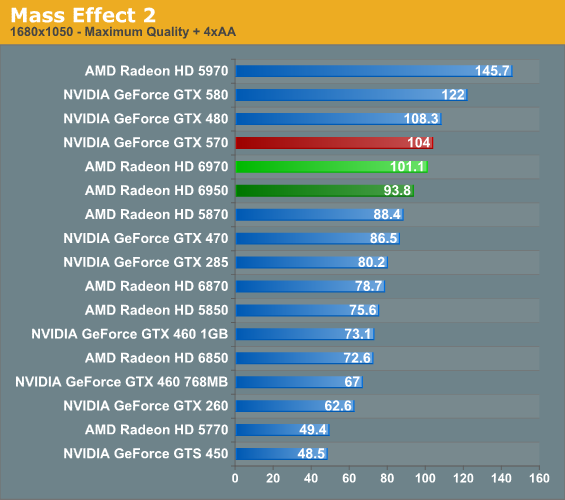
With Mass Effect 2 we’re looking at a fairly typical scenario. The 6970 holds a slight-to-no lead on the GTX 570, while the 6950 sits between the GTX 570 and the 5870. As one of the only DX9 games still in our benchmark suite we’d expect the 6900 series to take a hit due to the shader overhaul, but either that’s not the case or it’s masking better performance.
Wolfenstein
Finally among our benchmark suite we have Wolfenstein, the most recent game to be released using the id Software Tech 4 engine. All things considered it’s not a very graphically intensive game, but at this point it’s the most recent OpenGL title available. It’s more than likely the entire OpenGL landscape will be thrown upside-down once id releases Rage next year.
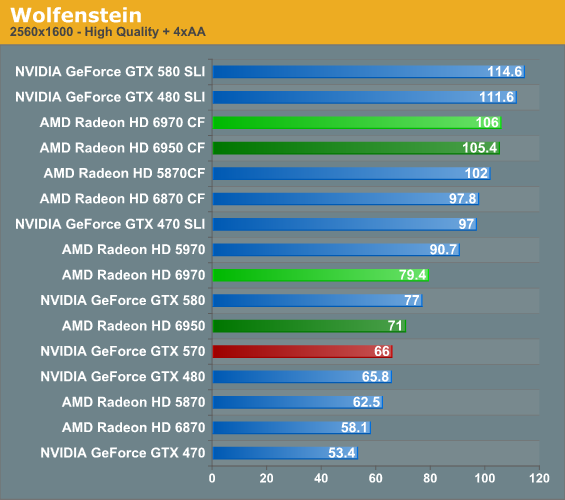

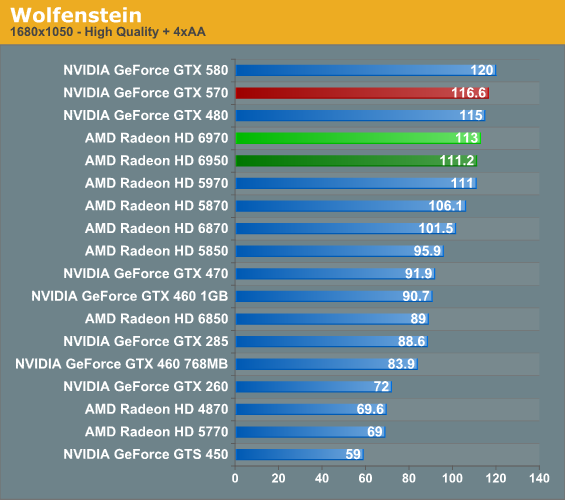
Wolfenstein is a game that normally favors AMD’s GPUs, and even an architectural refresh can’t change this fact. It takes running in to the game’s CPU bottleneck to slow things down for AMD, otherwise even the 6950 is faster than the GTX 570, while the 6970 manages to take down the GTX 580. The million dollar question of course is whether we’ll see a similar outcome for Rage next year.
Compute & Tessellation
Moving on from our look at gaming performance, we have our customary look at compute performance, bundled with a look at theoretical tessellation performance. This will give us our best chance to not only look at the theoretical aspects of AMD’s tessellation improvements, but to isolate shader performance to see whether AMD’s theoretical performance advantages and disadvantages from VLIW4 map out to real world scenarios.
Our first compute benchmark comes from Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes.

Civilization V’s compute shader benchmark has always benefitted NVIDIA, but that’s not the real story here. The real story is just how poorly the 6900 series does compared to the 5870. The 6970 barely does better than the 5850, meanwhile the 6950 is closest to NVIDIA’s GTX 460, the 768MB version. If what AMD says is true about the Cayman shader compiler needing some further optimization, then this is benchmark where that’s readily apparent. As an application of GPU computing, we’d expect the 6900 series to do at least somewhat better than the 5870, not notably worse.
Our second GPU compute benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. While it’s still in beta, SmallLuxGPU recently hit a milestone by implementing a complete ray tracing engine in OpenCL, allowing them to fully offload the process to the GPU. It’s this ray tracing engine we’re testing.

Unlike Civ 5, SmallLuxGPU’s performance is much closer to where things should be theoretically. Even with all of AMD’s shader changes both the 5870 and 6970 have a theoretical 2.7 TFLOPs of compute performance, and SmallLuxGPU backs up that number. The 5870 and 6970 are virtually tied, exactly where we’d expect our performance to be if everything is running under reasonably optimal conditions. Note that this means that the 6950 and 6970 both outperform the GTX 580 here, as SmallLuxGPU does a good job setting AMD’s drivers up to extract ILP out of the OpenCL kernel it uses.
Our final compute benchmark is Cyberlink’s MediaEspresso 6, the latest version of their GPU-accelerated video encoding suite. MediaEspresso 6 doesn’t currently utilize a common API, and instead has codepaths for both AMD’s APP and NVIDIA’s CUDA APIs, which gives us a chance to test each API with a common program bridging them. As we’ll see this doesn’t necessarily mean that MediaEspresso behaves similarly on both AMD and NVIDIA GPUs, but for MediaEspresso users it is what it is.
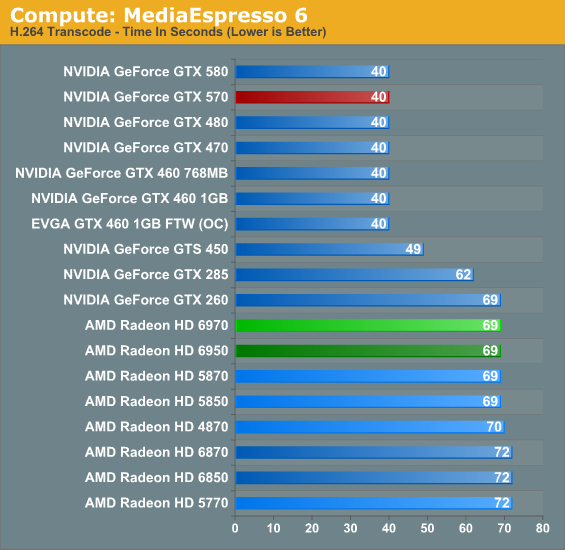
MediaEspresso 6 quickly gets CPU bottlenecked when paired with a faster GPU, leading to our clusters of results. For the 6900 series this mostly serves as a sanity check, proving that transcoding performance has not slipped even with AMD’s new architecture.
At the other end of the spectrum from GPU computing performance is GPU tessellation performance, used exclusively for graphical purposes. For the Radeon 6900 series, AMD significantly enhanced their tessellation by doubling up on tessellation units and the graphic engines they reside in, which can result in up to 3x the tessellation performance over the 5870. In order to analyze the performance of AMD’s enhanced tessellator, we’re using the Unigine Heaven benchmark and Microsoft’s DirectX 11 Detail Tessellation sample program to measure the tessellation performance of a few of our cards.
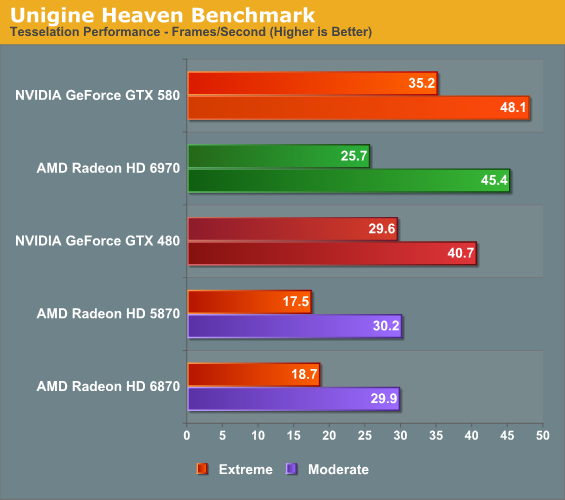
Since Heaven is a synthetic benchmark at the moment (the DX11 engine isn’t currently used in any games) we’re less concerned with performance relative to NVIDIA’s cards and more concerned with performance relative to the 5870. So with AMD’s tessellation improvements we see the 6970 shoot to life on this benchmark, coming in at nearly 50% faster than the 5870 at both moderate and extreme tessellation settings. This is actually on the low end of AMD’s theoretical tessellation performance improvements, but then even the geometrically overpowered GTX 580 doesn’t get such clear gains. But on that note while the 6970 does well at moderate tessellation levels, at extreme tessellation levels it still falls to the more potent GTX 400/500 series.

As for Microsoft’s DirectX 11 Detail Tessellation Sample program, a different story is going on. The 6970 once again shows significant gains over the 5870, but this time not against the 6870. With the 6870 implementing AMD’s tessellation factor optimized tessellator, most of the 6970’s improvements are already accounted for here. At the same time we can still easily see just how much of an advantage NVIDIA’s GTX 400/500 series still has in the theoretical tessellation department.
Power, Temperature, & Noise
Last but not least as always is our look at the power consumption, temperatures, and acoustics of the Radeon HD 6900 series. This is an area where AMD has traditionally had an advantage, as their small die strategy leads to less power hungry and cooler products compared to their direct NVIDIA counterparts. However NVIDIA has made some real progress lately with the GTX 570, while Cayman is not a small die anymore.
AMD continues to use a single reference voltage for their cards, so the voltages we see here represent what we’ll see for all reference 6900 series cards. In this case voltage also plays a big part, as PowerTune’s TDP profile is calibrated around a specific voltage.
| Radeon HD 6900 Series Load Voltage | ||||
| Ref 6970 | Ref 6950 | 6970 & 6950 Idle | ||
| 1.175v | 1.100v | 0.900v | ||

As we discussed at the start of our look at these cards, AMD has been tweaking their designs to take advantage of TSMC’s more mature 40nm process. As a result they’ve been able to bring down idle power usage slightly, even though Cayman is a larger chip than Cypress. For this reason the 6970 and 6950 both can be found at the top of our charts, running into the efficiency limits of our 1200W PSU.

Under Crysis PowerTune is not a significant factor, as Crysis does not generate enough of a load to trigger it. Accordingly our results are rather straightforward, with the larger, more power hungry 6970 drawing around 30W more than the 5870. The 6950 meanwhile is rated 50W lower and draws almost 50W less on the dot. At 292W it’s 15W more than the 5850, or effectively tied with the GTX 460 1GB.
Between Cayman’s larger die and NVIDIA’s own improvements in power consumption, the 6970 doesn’t end up being very impressive here. True, it does draw 20W less, but with the 5000 series AMD’s higher power efficiency was much more pronounced.

It’s under FurMark that we finally see the complete ramifications of AMD’s PowerTune technology. The 6970, even with a TDP over 60W above the 5870, still ends up drawing less power than the 5870 due to PowerTune throttling. This puts our FurMark results at odds with our Crysis results which showed an increase in power usage, but as we’ve already covered PowerTune tightly clamps power usage to AMD’s TDP, keeping the 6900 series’ worst case scenario for power consumption far below the 5870. While we could increase the TDP to 300W we have no practical reason to, as even with PowerTune FurMark still accurately represents the worst case scenario for a 6900 series GPU.
Meanwhile at 320W the 6950 ends up drawing more power than its counterpart the 5850, but not by much. It’s CrossFire variant meanwhile is drawing 509W,only 19W over a single GTX 580, driving home the point that PowerTune significantly reduces power usage for high load programs such as FurMark.

At idle the 6900 series is in good company with a number of other lower power and well-built GPUs. 37-38C is typical for these cards solo, meanwhile our CrossFire numbers conveniently point out the fact that the 6900 series doesn’t do particularly well when its cards are stacked right next to each other.

When it comes to Crysis our 6900 series cards end up performing very similarly to our 5800 series cards, a tradeoff between the better vapor chamber cooler and the higher average power consumption when gaming. Ultimately it’s going to be noise that ties all of this together, but there’s certainly nothing objectionable about temperatures in the mid-to-upper 70s. Meanwhile our 6900 series CF cards approach the upper 80s, significantly worse than our 5800 series CF cards.

Faced once more with FurMark, we see the ramifications of PowerTune in action. For the 6970 this means a temperature of 83C, a few degrees better than the 5870 and 5C better than the GTX 570. Meanwhile the 6950 is at 82C in spite of the fact that it uses a similar cooler in a lower powered configuration; it’s not as amazing as the 5850, but it’s still quite reasonable.
The CF cards on the other hand are up to 91C and 92C despite the fact that PowerTune is active. This is within the cards’ thermal range, but we’re ready to blame the cards’ boxy design for the poor CF cooling performance. You really, really want to separate these cards if you can.

At idle both the 6970 and 6950 are on the verge of running in to our noise floor. With today’s idle power techniques there’s no reason a card needs to have high idle power usage, or the louder fan that often leads to.

Last but not least we have our look at load noise. Both cards end up doing quite well here, once more thanks to PowerTune. As is the case with power consumption, we’re looking at a true worst case scenario for noise, and both cards do very well. At 50.5db and 54.6db neither card is whisper quiet, but for the gaming performance they provide it’s a very good tradeoff and quieter than a number of slower cards. As for our CrossFire cards, the poor ventilation pours over in to our noise tests. Once more, if you can separate your cards you should do so for greatly improved temperature and noise performance.
Final Thoughts
Often it’s not until the last moment that we have all the information in hand to completely analyze a new video card. The Radeon HD 6970 and Radeon HD 6950 were no different. With AMD not releasing the pricing information to the press until Monday afternoon, we had already finished our performance benchmarks before we even knew the price, so much time was spent speculating and agonizing over what route AMD would go. So let’s jump straight in to our recommendations.
Our concern was that AMD would shoot themselves in the foot by pricing the Radeon HD 6970 in particular at too high a price. If we take a straight average at 1920x1200 and 2560x1600, its performance is more or less equal to the GeForce GTX 570. In practice this means that NVIDIA wins a third of our games, AMD wins a third of our games, and they effectively tie on the rest, so the position of the 6970 relative to the GTX 570 is heavily dependent on just what games out of our benchmark suite you favor. All we can say for sure is that on average the two cards are comparable.
So with that in mind a $370 launch price is neither aggressive nor overpriced. Launching at $20 over the GTX 570 isn’t going to start a price war, but it’s also not so expensive to rule the card out. Of the two the 6970 is going to take the edge on power efficiency, but it’s interesting to see just how much NVIDIA and AMD’s power consumption and performance under gaming has converged. It used to be much more lopsided in AMD’s favor.
Meanwhile the Radeon HD 6950 occupies an interesting spot. Above it is the 570/6970, below it are the soon to be discontinued GTX 470 and Radeon HD 5870. These cards were a bit of a spoiler for the GTX 570, and this is once more the case for the 6950. The 6950 is on average 7-10% faster than the 5870 for around 20% more. I am becoming increasingly convinced that more than 1GB of VRAM is necessary for any new cards over $200, but we’re not quite there yet. When the 5870 is done and gone the 6950 will be a reasonable successor, but for the time being the 5870 at $250 currently is a steal of a deal if you don’t need the extra performance or new features like DP1.2. Conversely the 6950 is itself a bit of a spoiler; the 6970 is only 10-15% faster for $70 more. If you had to have a 6900 card, the 6950 is certainly the better deal. Whether you go with the 5870, the 6950, or the 6970, just keep in mind that the 6900 series is in a much better position for future games due to AMD’s new architecture.
And that brings us to the final matter for today, that new architecture. Compared to the launch of Cypress in 2009 the feature set isn’t radically different like it was when AMD first added DirectX 11 support, but Cayman is radically different in its own way. After being carried by their current VLIW5 architecture for nearly four years, AMD is set to hand off their future to their new VLIW4 architecture. It won’t turn the world upside down for AMD or its customers, but it’s a reasonable step forward for the company by reducing their reliance on ILP in favor of more narrow TLP-heavy loads. For gaming this specifically means their hardware should be a better match for future DX10/DX11 games, and the second graphics engine should give them enough tessellation and rasterizing power for the time being.
Longer term we will have to see how AMD’s computing gamble plays out. Though we’ve largely framed Cayman in terms of gaming, to AMD Cayman is first and foremost a compute GPU, in a manner very similar to another company whose compute GPU is also the fastest gaming GPU on the market. Teething issues aside this worked out rather well for NVIDIA, but will lightning strike twice for AMD? The first Cayman-based video cards are launching today, but the Cayman story is just getting started.






