Original Link: https://www.anandtech.com/show/13244/hot-chips-2018-smiv-dnn-soc-for-iot-live-blog
Hot Chips 2018: SMIV DNN SoC for IoT Live Blog (4pm PT, 11pm UTC)
by Ian Cutress on August 20, 2018 6:55 PM EST
07:05PM EDT - A slightly different talk from Hot Chips this time: here's a neural network processor aimed at IoT devices based in 16nm. The slides look interesting, so we're covering this talk too.
07:05PM EDT - Designing NN algorithms that require less multiplications and less storage
07:05PM EDT - For IoT
07:05PM EDT - MobileNet for reducing workloads


07:06PM EDT - Optimize the hardware to reduce compute
07:06PM EDT - Efficiency vs flexibility
07:06PM EDT - Accelerators optimized for a specific workload might not be flexible
07:07PM EDT - In embedded, still care about die area
07:07PM EDT - DNNs have risk of premature obsolescence
07:07PM EDT - Few DNNs have converged
07:07PM EDT - No silver bullet
07:07PM EDT - IoT spend a lot of time in low power
07:08PM EDT - Heavily optimized hardware is preferential in low power scenarios, but lose flexibility
07:08PM EDT - Don't just care about performance, it's efficiency with minimum perf
07:08PM EDT - This led to SMIV
07:09PM EDT - Built at Harvard, academic chip
07:09PM EDT - 25mm2, 500m transistors, Cortex A-class CPUs
07:09PM EDT - 672-pin BGA package
07:09PM EDT - Near Threshold always on cluster
07:10PM EDT - Rest of system will spend most of the time off
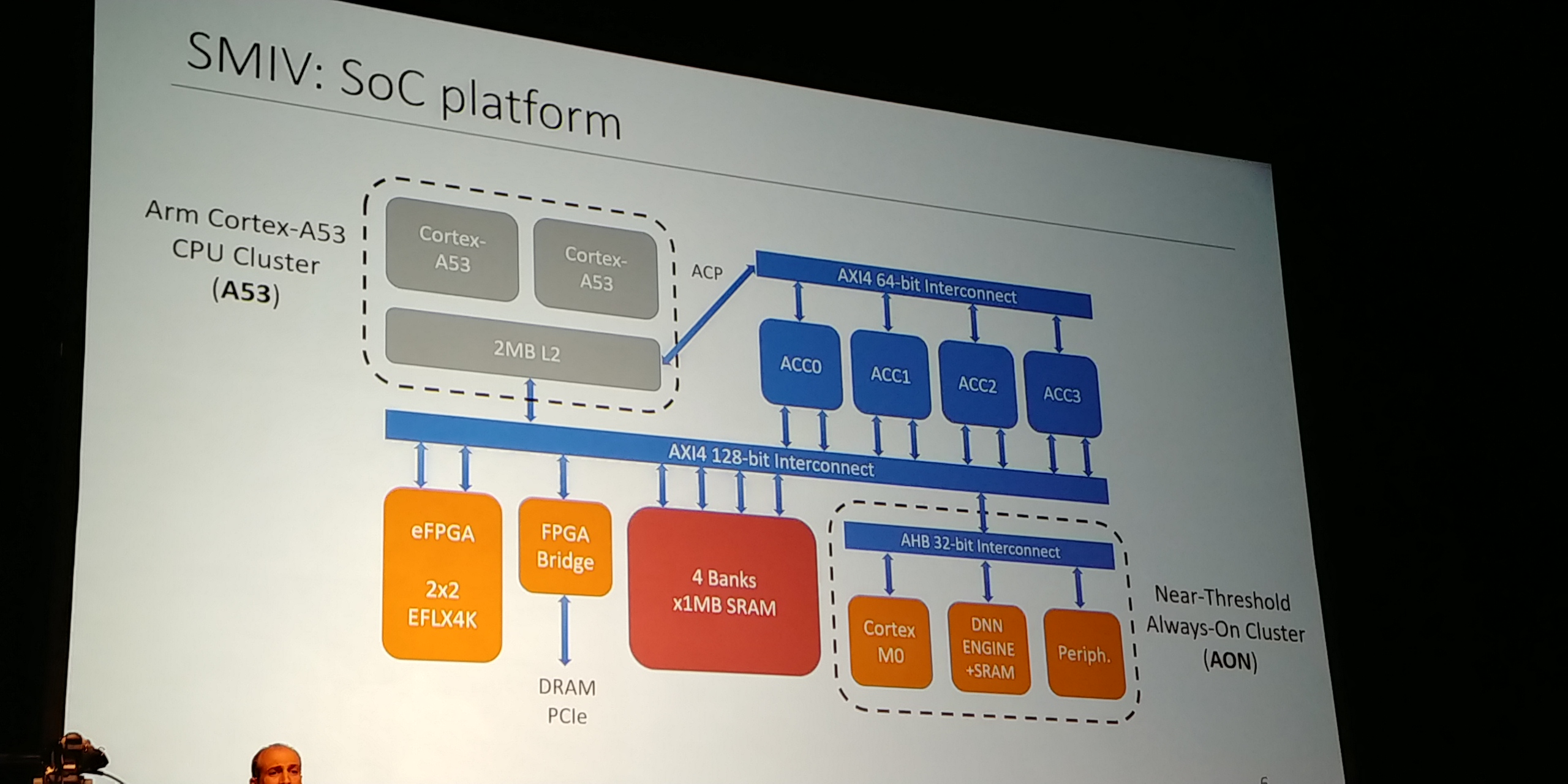
07:10PM EDT - Dual ARM Cortex A53
07:11PM EDT - embedded FPGA core from FlexLogic
07:11PM EDT - Standalone accelerator for CPU
07:11PM EDT - 4MB of SRAM for Neural Network workloads
07:11PM EDT - off-chip link to FPGA
07:12PM EDT - Cortex M0 always on core
07:12PM EDT - Using regularly
07:12PM EDT - Also includes DNN engine classifier

07:12PM EDT - AON cluster has 1 MB of SRAM. Doesn't use off-chip memory access
07:12PM EDT - 150nJ per inference for small tasks

07:13PM EDT - A53 has ACP - Accelerator Coherency Port
07:13PM EDT - efficient way to interface accelerators
07:13PM EDT - Low hardware cost for the accelerator, advantages with coherent memory access

07:14PM EDT - Gives the accelerators access to L2 cache
07:14PM EDT - Fine grained datapath acceleration
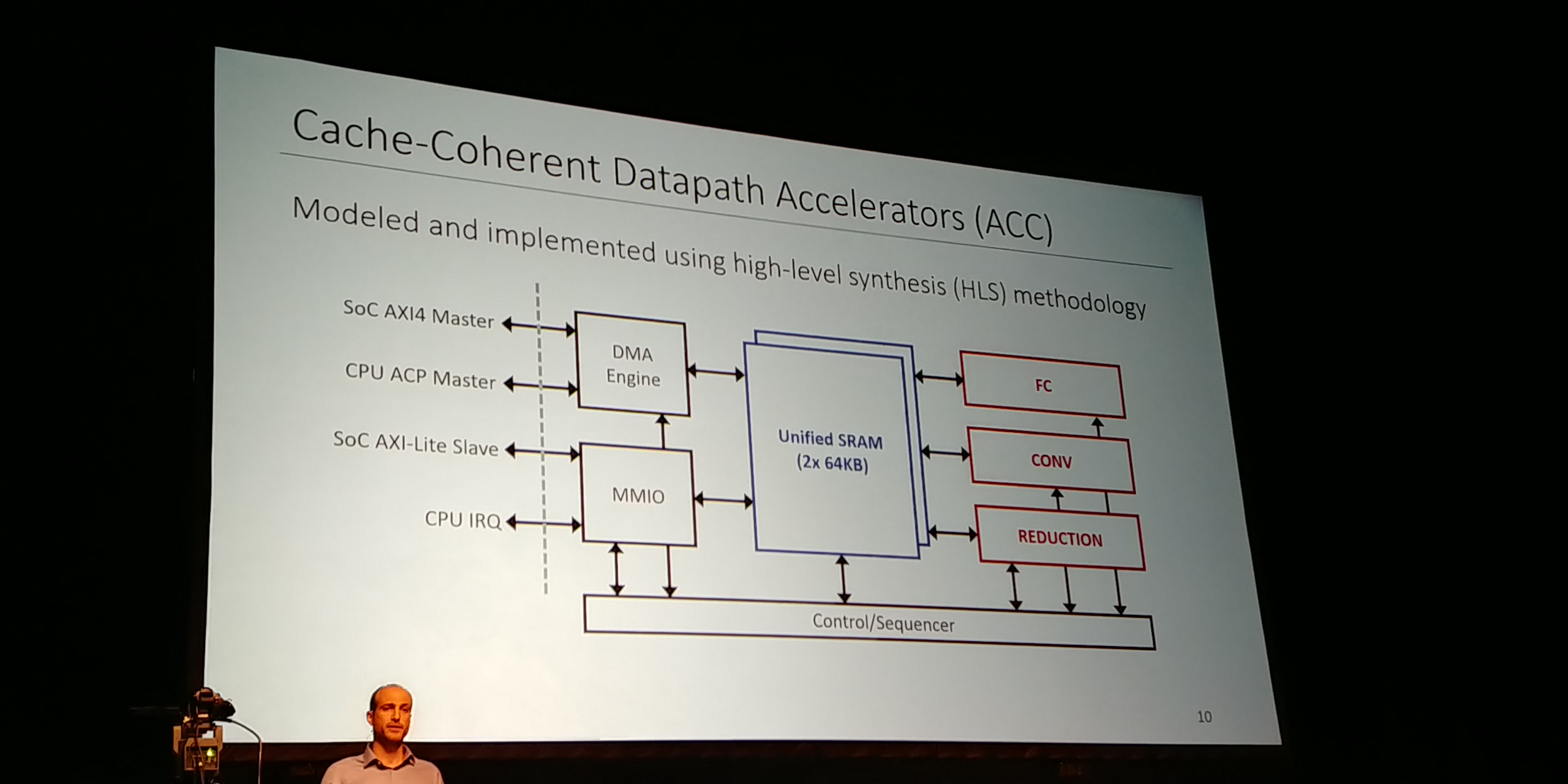
07:14PM EDT - Cache Coherent Datapath Acceleators

07:15PM EDT - Embedded FPGA in 2x2 array
07:15PM EDT - Standard cell approach, IP is scalable and flexible
07:15PM EDT - Logic tile is 2500 LUT6, DSP tile has 40x 22b MACs
07:16PM EDT - 2 Logic tiles + 2 DSP tiles in 2x2 array
07:16PM EDT - Use embedded FPGA as standalone accelerator for efficiency vs flexibility
07:16PM EDT - Chips already back from TSMC
07:16PM EDT - All pre-silicon tests passed.
07:17PM EDT - Using for research
07:17PM EDT - eFPGA as first class citizen, incremental wakeup from AON sub-system
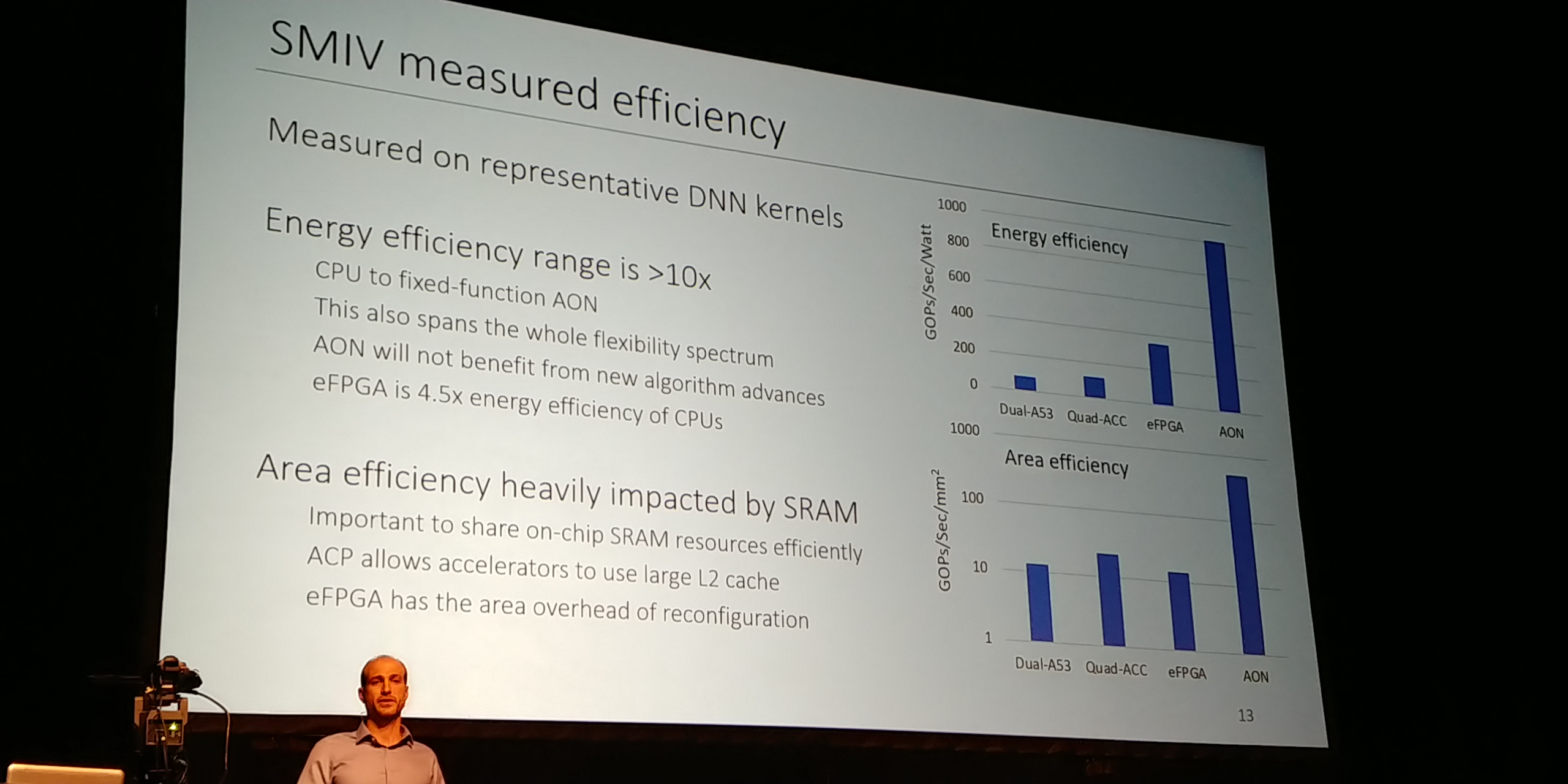
07:18PM EDT - AON has best Energy / Area efficiency - but heavily impacted by SRAM
07:18PM EDT - Perf is obviously different
07:18PM EDT - eFPGA is 4.5x efficiency of CPUs
07:18PM EDT - Graph is in GOPS/Watt
07:19PM EDT - eFPGA has area overhead for reconfigurability
07:20PM EDT - Made under DARPA program

07:20PM EDT - No custom layout - standard cells and SRAMs
07:20PM EDT - High-level synthesis using NVIDIA methodology
07:20PM EDT - Scripted methodologies for generating memory mapped registers, IO pad-ring, clock domains
07:21PM EDT - Makes validation on completed silicon easier

07:23PM EDT - Arm Designstart helped
07:23PM EDT - Used academic licences

07:24PM EDT - Driving new IoT use cases with DNN in IoT SoCs in 16nm
07:25PM EDT - Q: What acceleration can you do on eFPGA?
07:26PM EDT - A: MatMul for Convolutional Neural Networks. Smart DMA engines.
07:27PM EDT - Q: Why is the efficiency of the dedicated accelerator less than the Always On?
07:27PM EDT - A: Our dedicated accelerator was mainly focused on the connectivity, but can be scaled
07:28PM EDT - That's a wrap. Next talk in 30 minutes on Xavier






