Original Link: https://www.anandtech.com/show/1314
ATI Radeon X800 Pro and XT Platinum Edition: R420 Arrives
by Derek Wilson on May 4, 2004 10:28 AM EST- Posted in
- GPUs
Introduction
Today we herald the release of the new ATI graphics solution. Though the R420 is still based on DX9's PS2.0, performance numbers look to be on par with what we would expect from a company who has lead the industry in performance for nearly two years. The two new board configurations based on R420 at which we will be looking today are the Radeon X800 Pro, and the Radeon X800 XT Platinum Edition. The Radeon X800 Pro is shipping today, but the XT Platinum Edition won't make it out the door until later this month (ATI cites May 21st as the shipping date).

We were skeptical, when the GeForce 6800 Ultra was thrust into the spotlight, that ATI would be able to keep up with their toughest competitor. From the first briefing we had regarding the R420 GPU, we knew it would be an intense fight. Both the NV40 and R420 architectures are very sound and well founded, and the next six months will be a very good time for consumers of computer technology. But before we start handing out the nominations for happiest customer, let's take a look at the new kid on the block.
The Chip
R420 is a very power GPU in tight little package. ATI opted not to go with full DirectX 9.0 Shader Model 3.0 support in their latest GPU, but that doesn't mean that this chip doesn't pack a punch. Here's a breakdown of what's on the top of the line playing field now.
| NV38 | NV40 | R360 | R420 | |
|---|---|---|---|---|
| Transistors | 130M |
222M |
110M |
160M |
| Core clock | 475MHz |
400MHz |
412MHz |
500MHz |
| Mem clock | 950MHz |
1.1GHz |
900MHz |
1.12GHz |
| Memory Bus | 256bit |
256bit |
256bit |
256bit |
| Vertex Pipelines | ~4 |
6 |
4 |
6 |
| Pixel Pipelines | 4x2 |
16x1 |
8x1 |
16x1 |
| Shader Model | 2.0+ |
3.0 |
2.0 |
2.0+ |
| Fab Process | 130nm |
130nm |
150nm |
130nm |
| GeForce 6800 GT | GeForce 6800 Ultra | GeForce 6850 Ultra | Radeon X800 Pro | Radeon X800 XT PE | |
|---|---|---|---|---|---|
| Price | $399 |
$499 |
$499+ |
$399 |
$499 |
The first thing we see is that R420 has the highest clock speed (giving it the highest peak fillrate), and it just edges out NV40 for memory speed. Of course, these theoretical numbers don't really translate directly into performance. In order to understand where performance comes from, we'll need to take a much closer look at the architecture.
Before we get in over our heads on this, it is important to differentiate the hardware itself from how the hardware looks in terms of a graphics API. Both NVIDIA and ATI, in presenting their hardware to us, have relied heavily on using the constructs of DirectX 9 to explain what's going on at different stages in the pipeline. This is useful in that we can understand how the hardware looks to the software, but there are some caveats. We will be keeping this in mind as we look over the new offerings from ATI and NVIDIA.
The R420 Vertex Pipeline
The point of the vertex pipeline in any GPU is to take geometry data, manipulate it if needed (with either fixed function processes, or a vertex shader program), and project all of the 3D data in a scene to 2 dimensions for display. It is also possible to eliminate unnecessary data from the rendering pipeline to cut out useless work (via view volume clipping and backface culling). After the vertex engine is done processing the geometry, all the 2D projected data is sent to the pixel engine for further processing (like texturing and fragment shading).
The vertex engine of R420 includes 6 total vertex pipelines (R3xx has four). This gives R420 a 50% per clock increase in peak vertex shader power per clock cycle.
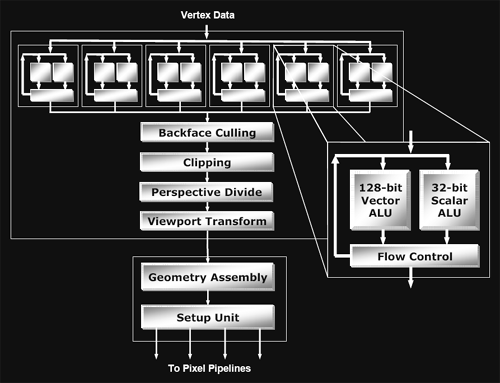
Looking inside an individual vertex pipeline, not much has changed from R3xx. The vertex pipeline is laid out exactly the same, including a 128bit vector math unit, and a 32bit scalar math unit. The major upgrade R420 has had from R3xx is that it is now able to compute a SINCOS instruction in one clock cycle. Before now, if a developer requested the sine or cosine of a number in a vertex shader program, R3xx would actually compute a taylor series approximation of the answer (which takes longer to complete). The adoption of a single cycle SINCOS instruction by ATI is a very smart move, as trigonometric computations are useful in implementing functionality and effects attractive to developers. As an example, developers could manipulate the vertices of a surface with SINCOS in order to add ripples and waves (such as those seen in bodies of water). Sine and cosine computations are also useful in more basic geometric manipulation. Overall, R420 has a welcome addition in single cycle SINCOS computation.
So how does ATI's new vertex pipeline layout compare to NV40? On a major hardware "black box" level, ATI lacks the vertex texture unit featured in NV40 that's required for shader model 3.0's vertex texturing support. Vertex texturing allows developers to easily implement any effect which would benefit from allowing texture data to manipulate geometry (such as displacement mapping). The other major difference between R420 and NV40 is feature set support. As has been widely talked about, NV40 supports Shader Model 3.0 and all the bells and whistles that come along with it. R420's feature set support can be described as an extended version of Shader Model 2.0, offering a few more features above and beyond the R3xx line (including more support of longer shader programs, and more registers).
What all this boils down to is that we are only seeing something that looks like a slight massaging of the hardware from R300 to R420. We would probably see many more changes if we were able too peer deeper under the hood. From a functionality standpoint, it is sometimes hard to see where performance comes from, but (as we will see even more from the pixel pipeline) as graphics hardware evolves into multiple tiny CPUs all laid out in parallel, performance will be effected by factors traditionally only spoken of in CPU analysis and reviews. The total number of internal pipeline stages (rather than our high level functionality driven pipeline), cache latencies, the size of the internal register file, number of instructions in flight, number of cycles an instructions takes to complete, and branch prediction will all come heavily into play in the future. In fact, this review marks the true beginning of where we will be seeing these factors (rather than general functionality and "computing power") determine the performance of a generation of graphics products. But, more on this later.
After leaving the vertex engine portion of R420, data moves into the setup engine. This section of the hardware takes the 2D projected data from the vertex engine, generates triangles and point sprites (particles), and partitions the output for use in the pixel engine. The triangle output is divided up into tiles, each of which are sent to a block of four pixel pipelines (called a quad pipeline by ATI). These tiles are simply square blocks of projected pixel data, and have nothing to do with "tile based rendering" (front to back rendering of small portions of the screen at a time) as was seen in PowerVR's Kyro series of GPUs.
Now we're ready to see what happens on the per-pixel level.
The Pixel Shader Engine
On par with what we have seen from NVIDIA, ATI's top of the line card is offering a GPU with a 16x1 pixel pipeline architecture. This means that it is able to render up to 16 single textured pixels in parallel per clock. As previously alluded to, R420 divides its pixel pipes into groups of four called quads. The new line of ATI GPUs will offer anywhere from one to four quad pipelines. The R3xx architecture offers an 8x1 pixel pipeline layout (grouped into two quad pipelines), delivering half of R420's pixel processing power per clock. For both R420 and R3xx, certain resources are shared between individual pixel pipelines in each quad. It makes a lot of sense to share local memory among quad members, as pixels near eachother on the screen should have (especially texture) data with a high locality of reference. At this level of abstraction, things are essentially the same as NV40's architecture.
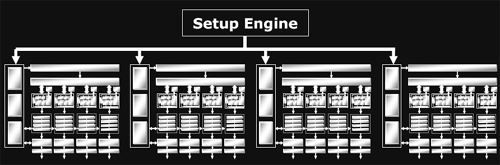
Of course, it isn't enough to just look how many pixel pipelines are available: we must also discover how much work each pipeline is able to get done. As we saw in our final analysis of what went wrong with NV3x, the internals of a shader unit can have a very large impact on the ability of the GPU to schedule and execute shader code quickly and efficiently.
At our first introduction, the inside of R420's pixel pipeline was presented as a collection of 2 vector units, 2 scalar units, and one texture unit that can all work in parallel. We've seen the two math and one texture layout of NV40's pixel pipeline, but does this mean that R420 will be able to completely blow NV40 out of the water? In short, no: it's all about what kind of work these different units can do.
Lifting up the hood, we see that ATI has taken a different approach to presenting their architecture than NVIDIA. ATI's presentation of 2 vector units (which are 3 wide at 72bits), 2 scalar units (24bits), and a texture unit may be more reflective of their implementation than what NVIDIA has shown (but we really can't know this without many more low level details). NVIDIA's hardware isn't quite as straight forward as it may end up looking to software. The fact is that we could look at the shader units in NV40's pixel pipeline in the same way as ATI's hardware (with the exception of the fact that the texture unit shares some functionality with one of the math units). We could also look at NV40 architecture as being 4 2-wide vector units or 2 4-wide vector units (though this is still an over simplification as there are special cases NVIDIA's compiler can exploit that allow more work to be done in parallel). If ATI had decided to present it's architecture in the same way as NVIDIA, we would have seen 2 shader math units and one completely independent texture unit.
In order to gain better understanding, here is a diagram of the parallelism and functionality of the shader units within the pixel pipelines of R420 and NV40:
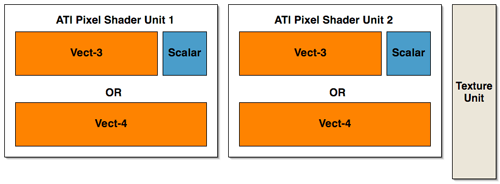
ATI has essentially three large blocks that can push up to 5 operations per clock cycle
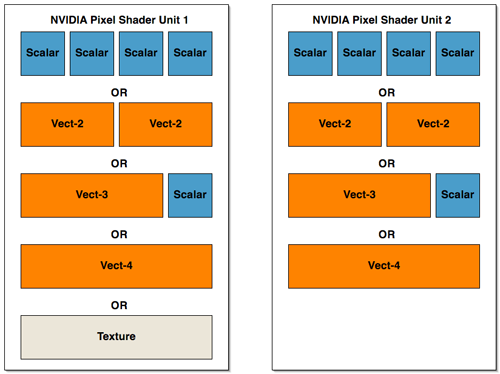
NV40 can be seen two blocks of a more amorphous configuration (but there are special cases that allow some of these parts to work at the same time within each block.
Interestingly enough, there haven't been any changes to the block diagram of a pixel pipeline at this level of detail from R3xx to R420.
The big difference in the pixel pipe architectures that gives the R420 GPU a possible upper hand in performance over NV40 is that texture operations can be done entirely in parallel with the other math units. When NV40 needs to execute a texture operation, it looses much of its math processing power (the texturing unit cannot operate totally independently of the first shader unit in the NV40 pixel pipeline). This is also a feature of R3xx that carried over to R420.
![]()
Understanding what this all means in terms of shader performance depends on the kind of code developers end up writing. We wanted to dedicate some time to hand mapping some shader code to both architecture's pixel pipelines in order to explain how each GPU handled different situations. Trial and error have led us to the conclusion that video card drivers have their work cut out for them when trying to optimize code; especially for NV40. There are multiple special cases that allow NVIDIA's architecture to schedule instructions during texturing operations on the shared math/texture unit, and some of the "OR" cases from our previous diagram of parallelism can be massaged into "and" cases when the right instructions are involved. This also indicates that performance gains due to compiler optimizations could be in NV40's future.
Generally, when running code with mixed math and texturing (with a little more math than texturing) ATI will lead in performance. This case is probably the most indicative of real code.
The real enhancements to the R420 pixel pipeline are deep within the engine. ATI hasn't disclosed to us the number of internal registers their architectures have, or how many pixels each GPU can maintain in flight at any given time, or even cache hit/miss latencies. We do know that, in addition to the extra registers (32 constant and 32 temp registers up from 12) and longer length shaders (somewhere between 512 and 1536 depending on what's being done) available to developers on R420, the number of internal registers has increased and the maximum number of pixels in flight has increased. These facts are really important in understanding performance. The fundamental layout of the pixel pipelines in R420 and NV40 are not that different, but the underlying hardware is where the power comes from. In this case, the number of internal pipeline stages in each pixel pipeline, and the ability of the hardware to hide the latency of a texture fetch are of the utmost importance.
The bottom line is that R420 has the potential to execute more PS 2.0 instructions per clock than NVIDIA in the pixel pipeline because of the way it handles texturing. Even though NVIDIA's scheduler can help to allow more math to be done in parallel with texturing, NV40's texture and math parallelism only approaches that of ATI. Combine that with the fact that R420 runs at a higher clock speed than NV40, and even more pixel shader work can get done in the same amount of time on R420 (which translates into the possibility for frames being rendered faster under the right conditions).
Of course, when working with fp32 data, NV40 is doing 25% more "work" per operation, and it's likely that the support for fp32 from the front of the shader pipeline to the back contributes greatly to the gap in the transistor count (as well as performance numbers). When fp16 is enabled in NV40, internal register pressure is decreased, and less work is being done than in fp32 mode. This results in improved performance for NV40, but questions abound as to real world image quality from NVIDIA's compiler and precision optimized shaders (we are currently exploring this issue and will be following up with a full image quality analysis of now current generation hardware).
As an extension of the fp32 vs. fp24 vs. fp16 debate, NV40's support of Shader Model 3.0 puts it at a slight performance disadvantage. By supporting fp32 all the way through the shader pipeline, flow control, fp16 to the framebuffer and all the other bells and whistles that have come along for the ride, NV40 adds complexity to the hardware, and size to the die. The downside for R420 is that it now lags behind on the feature set front. As we pointed out earlier, the only really new features of the R420 pixel shaders are: higher instruction count shader programs, 32 temporary registers, and a polygon facing register (which can help enable two sided lighting).
To round out the enhancements to the R420's pixel pipeline, ATI's F-Buffer has been tweaked. The F-Buffer is what ATI calls the memory that stores pixels that have come out of the pixel shader but still require another pass (or more) thorough the pixel shader pipeline in order to finish being processed. Since the F-Buffer can require anywhere from no memory to enough memory to handle every pixel coming down the pipeline, ATI have built "improved" memory management hardware into the GPU rather than relegating this task to the driver.
Depth and Stencil with Hyper Z HD
In accordance with their "High Definition Gaming" theme, ATI is calling the R420's method of handling depth and stencil processing Hyper Z HD. Depth and stencil processing is handled at multiple points throughout the pipeline, but grouping all this hardware into one block can make sense as each step along the way will touch the z-buffer (an on die cache of z and stencil data). We have previously covered other incarnations of Hyper Z which have done basically the same job. Here we can see where the Hyper Z HD functionality interfaces with the rendering pipeline:
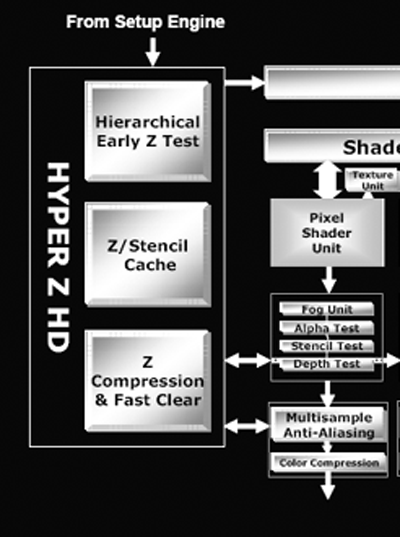
The R420 architecture implements a hierarchical and early z type of occlusion culling in the rendering pipeline.
With early z, as data emerges from the geometry processing portion of the GPU, it is possible to skip further rendering large portions of the scene that are occluded (or covered) by other geometry. In this way, pixels that won't be seen don't need to run through the pixel shader pipelines and waste precious resources.
Hierarchical z indicates that large blocks of pixels are checked and thrown out if the entire tile is occluded. In R420, these tiles are the very same ones output by the geometry and setup engine. If only part of a tile is occluded, smaller subsections are checked and thrown out if possible. This processing doesn't eliminate all the occluded pixels, so pixels coming out of the pixel pipelines also need to be tested for visibility before they are drawn to the framebuffer. The real difference between R3xx and R420 is in the number of pixels that can be gracefully handled.
As rasterization draws nearer, the ATI and NVIDIA architectures begin to differentiate themselves more. Both claim that they are able to calculate up to 32 z or stencil operations per clock, but the conditions under which this is true are different. NV40 is able to push two z/stencil operations per pixel pipeline during a z or stencil only pass or in other cases when no color data is being dealt with (the color unit in NV40 can work with z/stencil data when no color computation is needed). By contrast, R420 pushes 32 z/stencil operations per clock cycle when antialiasing is enabled (one z/stencil operation can be completed per clock at the end of each pixel pipeline, and one z/stencil operation can be completed inside the multisample AA unit).
The different approaches these architectures take mean that each will excel in different ways when dealing with z or stencil data. Under R420, z/stencil speed will be maximized when antialiasing is enabled and will only see 16 z/stencil operations per clock under non-antialiased rendering. NV40 will achieve maximum z/stencil performance when a z/stencil only pass is performed regardless of the state of antialiasing.
The average case for NV40 will be closer to 16 z/stencil operations per clock, and if users don't run antialiasing on R420 they won't see more than 16 z/stencil operations per clock. Really, if everyone begins to enable antialiasing, R420 will begin to shine in real world situations, and if developers embrace z or stencil only passes (such as in Doom III), NV40 will do very well. The bottom line on which approach is better will be defined by the direction the users and developers take in the future. Will enabling antialiasing win out over running at ultra-high resolutions? Will developers mimic John Carmack and the intensive shadowing capabilities of Doom III? Both scenarios could play out simultaneously, but, really, only time will tell.
A New Compression Scheme: 3Dc
3Dc isn't something that's going to make current games run better or faster. We aren't talking about a glamorous technology; 3Dc is a lossy compression scheme for use in 3D applications (as its name is supposed to imply). Bandwidth is a highly prized commodity inside a GPU, and compression schemes exist to try to help alleviate pressure on the developer to limit the amount of data pushed through a graphics card.
There are already a few compressions schemes out there, but in their highest compression modes, they introduce some discontinuity into the texture. This is acceptable in some applications, but not all. The specific application ATI is initially targeting for use with 3Dc is normal mapping.
Normal mapping is used in making the lighting of a surface more detailed than is its geometry. Usually, the normal vector at any given point is interpolated from the normal data stored at the vertex level, but, in order to increase the detail of lighting and texturing effects on a surface, normal maps can be used to specify the way normal vectors should be oriented across an entire surface at a high level of detail. If very large normal maps are used, enormous amounts of lighting detail can produce the illusion of geometry that isn't actually there.
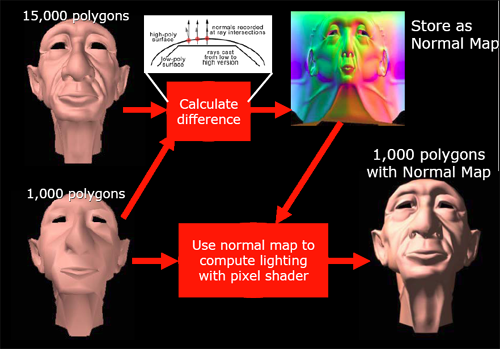
Here's an example of how normal mapping can add the appearance of more detailed geometry
In order to work with these large data sets, we would want to use a compression scheme. But since we don't want discontinuities in our lighting (which could appear as flashy or jumpy lighting on a surface), we would like a compression scheme that maintains the smoothness of the original normal map. Enter 3Dc.

This is an example of how 3Dc can help alieve continuity problems in normal map compression
In order to facilitate a high level of continuity, 3Dc divides textures into four by four blocks of vector4 data with 8 bits per component (512bit blocks). For normal map compression, we throw out the z component which can be calculated from the x and y components of the vector (all normal vectors in a normal map are unit vectors and fit the form x^2 + y^2 + z^2 = 1). After throwing out the unused 16 bits from each normal vector, we then calculate the minimum and maximum x and minimum and maximum y for the entire 4x4 block. These four values are stored, and each x or y value is stored as a 3 bit value selecting any of 8 equally spaced steps between the minimum and maximum x or y values (inclusive).
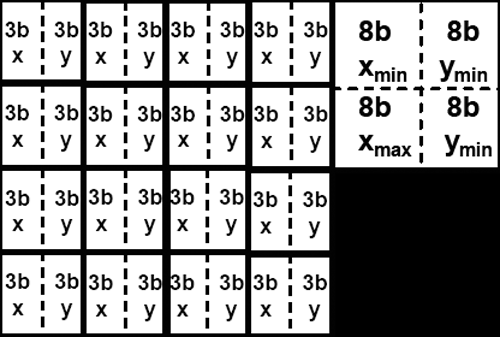
The storage space required for a 4x4 block of normal map data using 3Dc
the resulting compressed data is 4 vectors * 4 vectors * 2 components * 3 bits + 32 bits (128 bits) large, giving a 4:1 compression ratio for normal maps with no discontinuities. Any two channel or scalar data can be compressed fairly well via this scheme. When compressing data that is very noisy (or otherwise inherently discontinuous -- not that this is often seen) accuracy may suffer, and compression ratio falls off for data that is more than two components (other compression schemes may be more useful in these cases).
ATI would really like this compression scheme to catch on much as ST3C and DXTC have. Of course, the fact that compression and decompression of 3Dc is built in to R420 (and not NV40) won't play a small part in ATI's evangelism of the technology. After all is said and done, future hardware support by other vendors will be based on software adoption rate of the technology, and software adoption will likely also be influenced by hardware vendor's plans for future support.
As far as we are concerned, all methods of increasing apparent useable bandwidth inside a GPU in order to deliver higher quality games to end users are welcome. Until memory bandwidth surpasses the needs of graphics processors (which will never happen), innovative and effective compressions schemes will be very helpful in applying all the computational power available in modern GPUs to very large sets of data.
The Cards
Both the Radeon X800 Pro and the Radeon X800 XT Platinum Edition reference cards we received looked exactly the same.

It's very nice to see that this single slot card is equipped with only one molex connector (and in fact require less power than the 9800XT).

The only difference we could spot between the Pro and XT parts was the type of RAM used on each. The X800 Pro used 2ns ram which is capable of achieving 1GHz DDR rates of speed (but is clocked at 900MHz in the X800 Pro)

The X800 XT Platinum Edition makes use of 1.6ns RAM capable of over 1.2GHz DDR speeds.

Each board had 256MB of RAM strapped on board, and though they have slightly different cooling solutions, we were at a loss to locate the difference.
And what is the cost of one of these cards? The Radeon X800 Pro costs $399, and the Radeon X800 XT Platinum Edition will run the standard top of the line price of $499.
NVIDIA's Last Minute Effort
On the verge of ATI's R420 GPU launch, NVIDIA brought out a new card called the GeForce 6850 Ultra. This new card is to be sold as an OEM overclocked part (ala the "Golden Sample" and other such beasts), and will be able to run at 450MHz+ core and 1.1GHz+ memory clock speeds. It is very clear to us getting this board out here right now was a bit of a rush for NVIDIA, and it would seem that they didn't expect to see the kind of performance ATI's X800 series can deliver. We were unable to get drivers installed and running on our 6850 Ultra card until about two hours ago, but we will be following this article up with an update to the data as soon as we are able to benchmark the card. The 6850 Ultra looks exactly the same as the 6800 Ultra (it really is the same card with an overclock), so we'll forego the pictures.
The other part NVIDIA is launching today is their $399 price point card, the GeForce 6800 GT. This card won't be shipping for a while (mid June), and NVIDIA cites the fact that they didn't want to announce the card too far ahead of availability as the reason for the timing of this announcement.

The 6800 GT is a 16x1 architecture card that runs at 350MHz core and 1GHz memory clocks. As we can see from the beautiful picture, NVIDIA is bringing out a single slot card with one molex power connector based on NV40. Even if its not the fastest thing we'll see today, it is still good news. We will definitely be trying our hand at a little overclocking in the future. Power requirements are much less than the 6800 Ultra part, with something like a 300W PSU being perfectly fine to run this card.
Along with this new card release, NVIDIA have pushed out new beta drivers (61.11), of which we are still evaluating the image quality. We haven't seen any filtering differences, but we currently exploring some shader based image quality tests.
The Test
The key factor in the ongoing battle is DirectX 9 performance. We will be taking the hardest look at games that exploit PS 2.0, but that's not all people play (and there aren't very many on the market yet), we have included some past favorites as well.
Our test system is:
FIC K8T800 Motherboard
AMD Athlon 64 3400+
1GB OCZ PC3400 RAM
Segate 120GB PATA HDD
510W PC Power & Cooling PSU
The drivers we used in testing are:
NVIDIA Beta ForceWare 60.72
NVIDIA Beta ForceWare 61.11
ATI CATALYST BETA (version unknown)
ATI CATALYST 4.4
We didn't observe any performance difference when moving to the Beta CATAYLST from 4.4 on 9800 XT, so we chose to forgo retesting everything on the new drivers. Also, the 61.11 driver does show a slight increase in performance on NVIDIA cards, so we retested previously benchmarked hardware with the 61.11 drivers. Old numbers will be left in the benchmarks for completeness sake.
As mentioned earlier, we will be updating our tests later today with number collected from the GeForce 6850 Ultra (and we'll throw in a few other surprises as well).
Pixel Shader Performance Tests
ShaderMark v2.0 is a program designed to stress test the shader performance of modern DX9 graphics hardware with Shader Model 2.0 programs written in HLSL running on a couple shapes in a scene.

We haven't used ShaderMark in the past because we don't advocate the idea of trying to predict the performance of real world game code using a synthetic set of tests designed to push the hardware. Honestly, as we've said before, the only way to determine performance of a certain program on specific hardware is to run that program on that hardware. As both software and hardware get more complex, results of any given test become less and less generalize able, and games, graphics hardware, and modern computer systems are some of the most complex entities on earth.
So why are we using ShaderMark you may ask. There are a couple reasons. First this is only a kind of ball park test. ATI and NVIDIA both have architectures that should be able to push a lot of shader operations through. It is a fact that NV3x had a bit of a handicap when it came to shader performance. A cursory glance at ShaderMark should tell us enough to know if that handicap carries over to the current generation of cards, and whether or not R420 and NV40 are on the same playing field. We don't want to make a direct comparison, we just want to get a feel for the situation. With that in mind, here are the benchmarks.
| Radeon X800 XT PE | Radeon X800 Pro | GeForce 6800 Ultra | GeForce 6800 GT | GeForce FX 5950 U | |
|---|---|---|---|---|---|
| 2 | 310 |
217 |
355 |
314 |
65 |
| 3 | 244 |
170 |
213 |
188 |
43 |
| 4 | 238 |
165 |
|||
| 5 | 211 |
146 |
162 |
143 |
34 |
| 6 | 244 |
169 |
211 |
187 |
43 |
| 7 | 277 |
160 |
205 |
182 |
36 |
| 8 | 176 |
121 |
|||
| 9 | 157 |
107 |
124 |
110 |
20 |
| 10 | 352 |
249 |
448 |
410 |
72 |
| 11 | 291 |
206 |
276 |
248 |
54 |
| 12 | 220 |
153 |
188 |
167 |
34 |
| 13 | 134 |
89 |
133 |
118 |
20 |
| 14 | 140 |
106 |
141 |
129 |
29 |
| 15 | 195 |
134 |
145 |
128 |
29 |
| 16 | 163 |
113 |
149 |
133 |
27 |
| 17 | 18 |
13 |
15 |
13 |
3 |
| 18 | 159 |
111 |
99 |
89 |
17 |
| 19 | 49 |
34 |
|||
| 20 | 78 |
56 |
|||
| 21 | 85 |
61 |
|||
| 22 | 47 |
33 |
|||
| 23 | 49 |
43 |
49 |
46 |
These benchmarks are run with fp32 on NVIDIA hardware and fp24 on ATI hardware. It isn't really an apples to apples comparison, but with some of the shaders used in shadermark, partial precision floating point causes error accumulation (since this is a benchmark designed to stress shader performance, this is not surprising).
ShaderMark v2.0 clearly shows huge increase in pixel shader performance from NV38 to either flavor of NV40. Even though the results can't really be compared apples to apples (because of the difference in precision), NVIDIA manages to keep up with the ATI hardware fairly well. In fact, under the diffuse lighting and environment mapping, shadowed bump mapping and water color shaders don't show ATI wiping the floor with NVIDIA.
In looking at data collected on the 60.72 version of the NVIDIA driver, no frame rates changed and a visual inspection of the images output by each driver yielded no red flags.
We would like to stress again that these numbers are not apples to apples numbers, but the relative performance of each GPU indicates that the ATI and NVIDIA architectures are very close to comparable from a pixel shader standpoint (with each architecture having different favored types of shader or operation).
In addition to getting a small idea of performance, we can also look deep into the hearts of NV40 and see what happens when we enable partial precision rendering mode in terms of performance gains. As we have stated before, there were a few image quality issues with the types of shaders ShaderMark runs, but this bit of analysis will stick only to how much work is getting done in the same amount of time without regard to the relative quality of the work.
| GeForce 6800 U PP | GeForce 6800 GT PP | GeForce 6800 U | GeForce 6800 GT | |
|---|---|---|---|---|
| 2 | 413 |
369 |
355 |
314 |
| 3 | 320 |
283 |
213 |
188 |
| 5 | 250 |
221 |
162 |
143 |
| 6 | 300 |
268 |
211 |
187 |
| 7 | 285 |
255 |
205 |
182 |
| 9 | 159 |
142 |
124 |
110 |
| 10 | 432 |
389 |
448 |
410 |
| 11 | 288 |
259 |
276 |
248 |
| 12 | 258 |
225 |
188 |
167 |
| 13 | 175 |
150 |
133 |
118 |
| 14 | 167 |
150 |
141 |
129 |
| 15 | 195 |
173 |
145 |
128 |
| 16 | 180 |
161 |
149 |
133 |
| 17 | 21 |
19 |
15 |
13 |
| 18 | 155 |
139 |
99 |
89 |
| 23 | 49 |
46 |
49 |
46 |
The most obvious thing to notice is that, overall, partial precision mode rendering increases shader rendering speed. Shader 2 through 8 are lighting shaders (with 2 being a simple diffuse lighting shader). These lighting shaders (especially the point and spot light shaders) will make heavy use of vector normalization. As we are running in partial precision mode, this should translate to a partial precision normalize, which is a "free" operation on NV40. Almost any time a partial precision normalize is needed, NV40 will be able to schedule the instruction immediately. This is not the case when dealing with full precision normalization, so the many 50% performance gains coming out of those lighting shaders is probably due to the partial precision normalization hardware built into each shader unit in NV40. The smaller performance gains (which, interestingly, occur on the shaders that have image quality issues) are most likely the result of decreased bandwidth requirements, and decreased register pressure: a single internal fp32 register can handle two fp16 values making scheduling and managing resources much less of a task for the hardware.
As we work on our image quality analysis of NV40 and R420, we will be paying heavy attention to shader performance in both full and partial precision modes (as we want to look at what gamers will actually be seeing in the real world). We will likely bring shadermark back for these tests as well. This is a new benchmark for us, so please bear with us as we get used to its ins and outs.
Aquamark 3 Performance
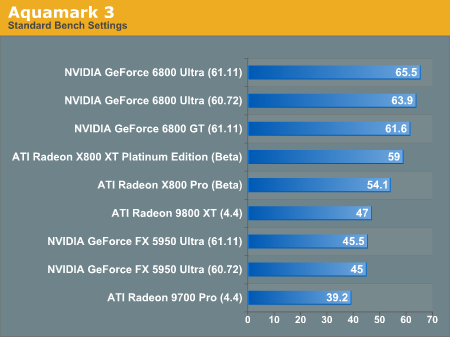
In our first game benchmark of the day, the GeForce 6800 Ultra takes the lead. Of course, we also have to remember that this benchmark is only running at 1024x768 which barely gives the 16x1 architectures a chance to stretch their legs.
If AquaNox was a more popular game, we might look into getting the full version and running this benchmark at 1600x1200. But as it stands, these are the numbers that people know, so these are the numbers we will continue to run.
FarCry Performance
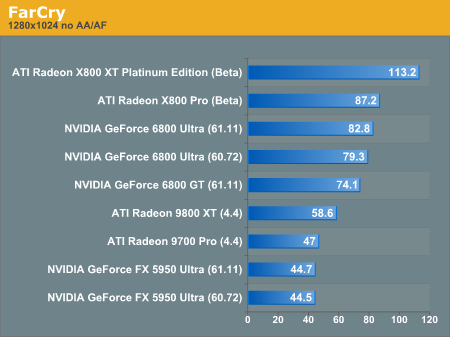
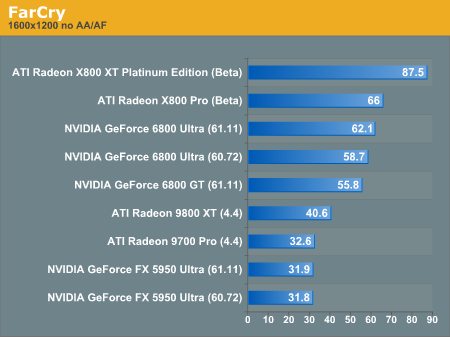
With no AA or AF enabled in FarCry, the X800 XT Platinum Edition takes off and looks great doing it. Leading the 6800 Ultra by over 40% at 1600x1200 is not a small feat, and its hard to believe we are talking about a 168% increase in speed over the 9700 Pro.
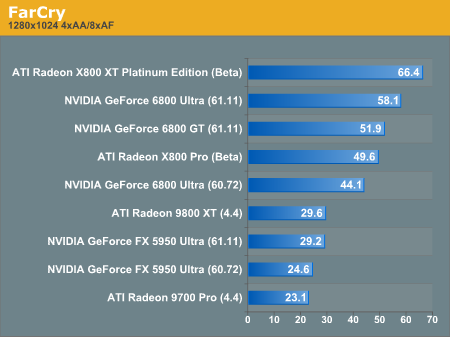
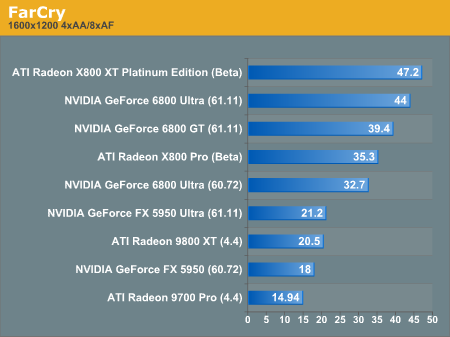
Enabling antialiasing and anisotropic filtering closes the gap between the NV40 and R420, but the X800 XT Platinum Edition still has a comfortable lead.
Halo Performance
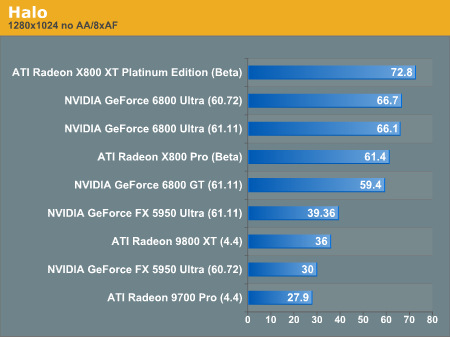
The lead isn't as pronounced here as it was in FarCry, but the X800 XT is at the top of the leaderboard. The X800 Pro and the 6800 GT seem fairly evenly matched here, which is nice to see.
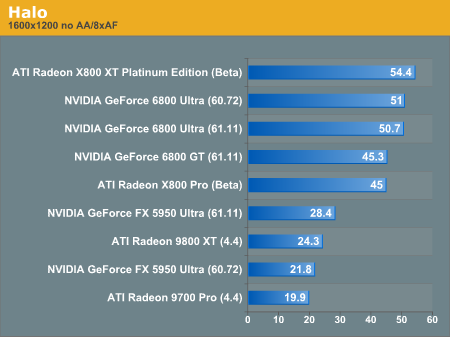
Again, the X800 XT leads the 6800 Ultra, and the $399 parts from ATI and NVIDIA are solidly defining four hundred dollar performance in Halo.
Homeworld 2 Performance
Interestingly enough, Homeworld 2 (with the 1.1 patch) makes use of two different shadowing methods. NV40, R420, and R3xx parts make use of a shader model 2.0 program for shadowing, while other GPUs (including NV3x) make use of shadow maps.
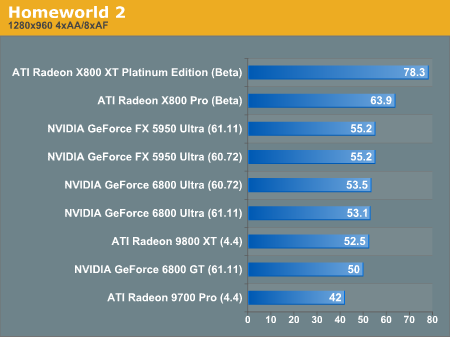
We can see that the shadow map technique runs much faster on NV3x than the shader runs on everything but R420.
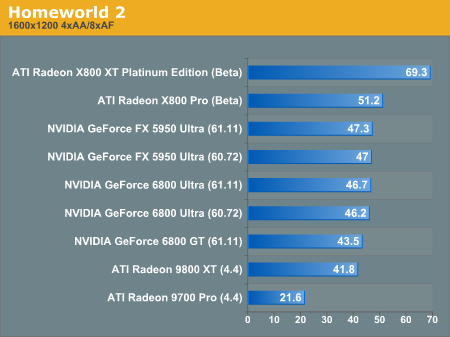
The same trend continues at higher resolutions as well. It is possible to force NV3x to run using the shader program, but this is how the game will play on end users hardware, so this is how we will look at performance. It is important to note that there is no image quality difference between the shadow mapped and shaded methods used in the game.
Final Fantasy XI Benchmark
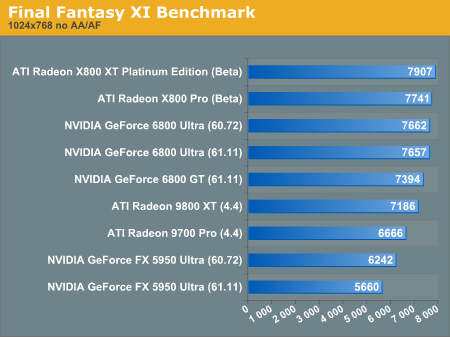
This benchmark is said to use some DX9 functionality, though we not sure in what capacity. Toward the top of end of peformance, Final Fantasy starts to look CPU bound. It might be worth looking in to benchmarking the actual game now that it's out as the benchmark is limited to a maximum of 1024x768 in hi res mode.
Not that it isn't obvious, but the R420 based parts are on top once again.
F1 Challenge '99-'02 Performance
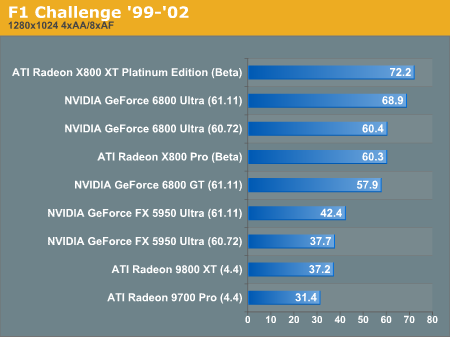
In this DX 8 benchmark, we see the two high end parts battling it out for the performance lead at low resolution...
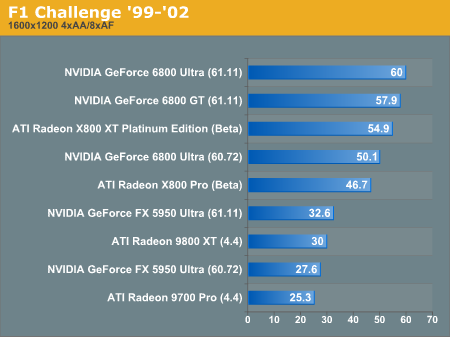
... while at high resolution, the NV40 parts push to the front of the pack.
EVE: The Second Genesis Performance
CCP have previously stated that they are working on adding benchmark functionality to EVE in order to help make our lives easier. Currently we have to log on to the EVE servers and hide in lonely areas of space to do our testing in this game. But such is the difficulty of benchmarking a persistant world MMORPG.

Without AA and AF, the R420 brothers are at the top of the heap, followed very closely by the 6800 Ultra running a previous beta driver revision.

When AA and AF are turned on, however, the X800 Pro drops a few spots to exactly the same performance level as the 6800 GT part. We might think that his relative drop might have something to do with the scalability of the 12 pipe version of R420 except for the fact that the 8 pipe 9800 XT maintains its position so well.
Unreal Tournament 2004 Performance
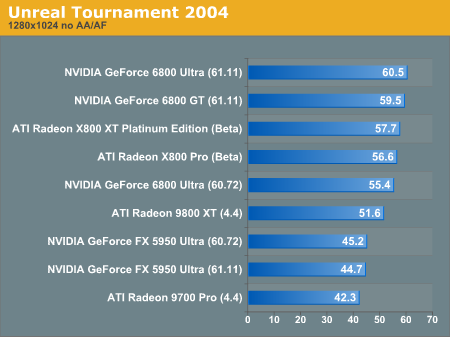
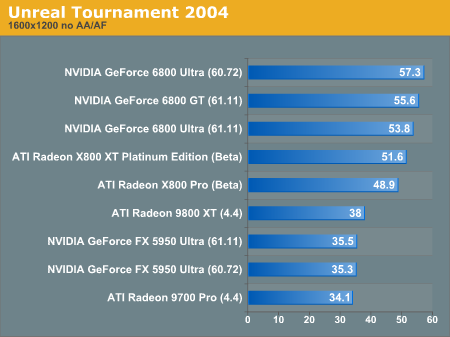
Without aniso and antialiasing enabled, it looks like NVIDIA is leadign the pack.
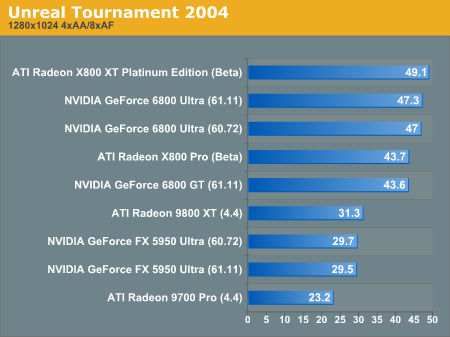
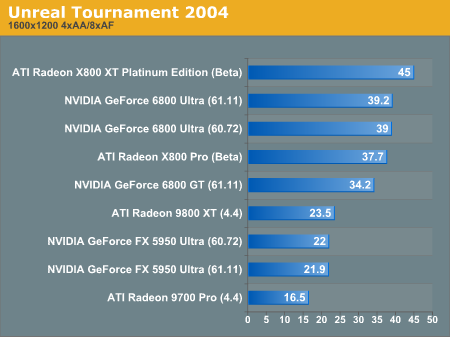
This time around, it seems like kicking up the antialiasing and anisotropic filtering also gave a kick in the pants to R420. The top end X800 XT takes the least performance hit from enabling these features.
X2: The Threat Performance
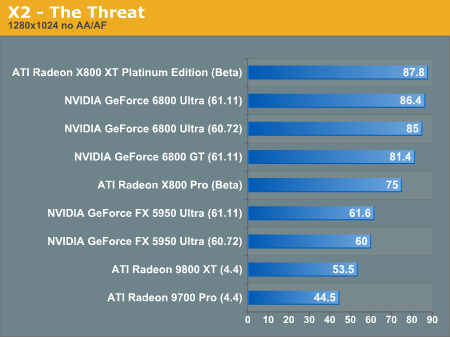
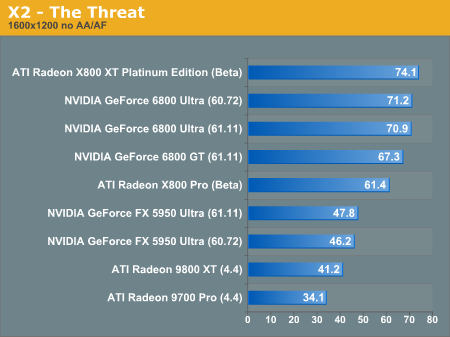
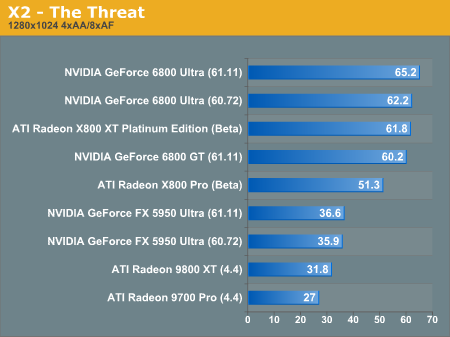
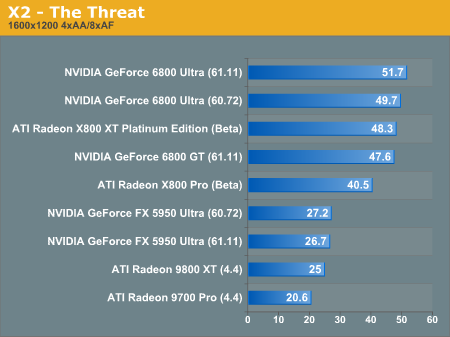
Here we see the flipside of the Unreal benchmark where X800 leads without anisotropic fitering and antialiasing enabled, and the 6800 parts come up from behind after the juice is switched on. This behavior is a little bit difficult to understand, and we will need to devote some time specifically to antialiasing and anisotropic filtering performance.
Jedi Knight: Jedi Academy Performance
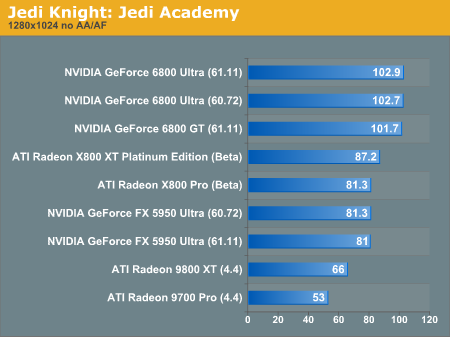
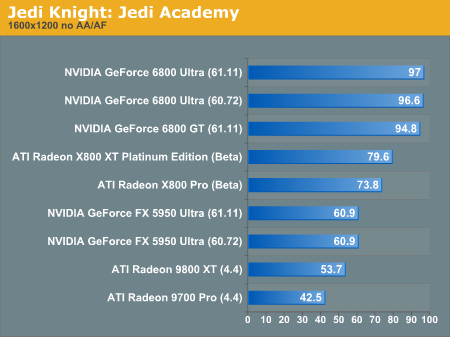
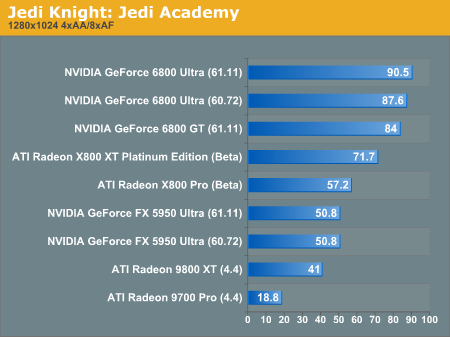
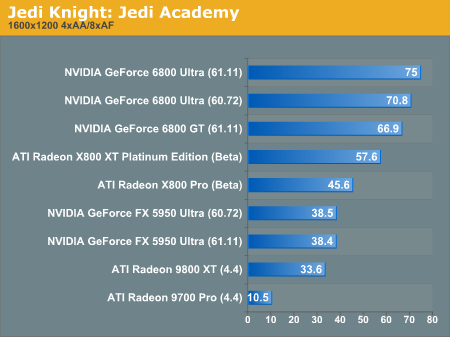
As we make our way into OpenGL territory, it becomes apparent that NVIDIA hasn't lost its edge when rendering games that run under this API.
Wolfenstein: Enemy Territory Performance

Here we start to see signs of a CPU bound quake engine based game. Fortunately this is our lightest test setting.

increasing the resolution helps the rest of the pack fall a little further behind NV40.
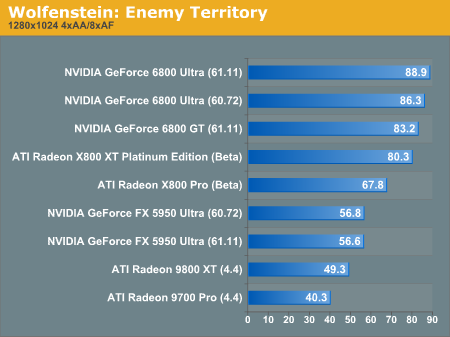

These benchmarks are really no surprise. NVIDIA has always been stronger in OGL based games, and Quake III engine based games in particular.
Neverwinter Nights: Shadow of the Undrentide Performance
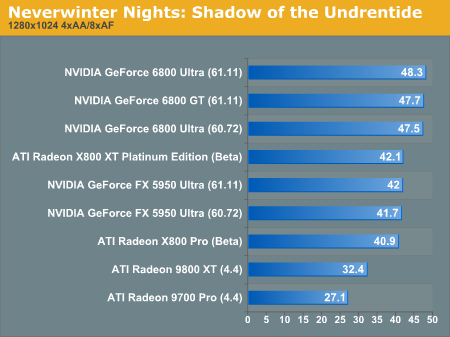
The thrid person style of this game lends itself to AA and AF, and since we've got plenty of power to spare, why not crank up the settings. At our low resolution, the NV40 parts are very close together, while the rest of the pack seems to fall away abruptly (again, we are dealing with OpenGL).
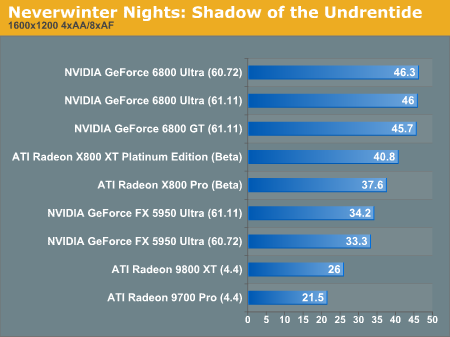
Moving up to 16x12, we see more of the same, with the only card able to hold on to its relative performance being the X800 XT Platinum Edition.
Final Words
I don't think anyone thought the race would be this close after what has been going on over the past couple years with ATI and NVIDIA. Clearly, both camps have had their wins and losses, but it is safe to say that ATI comes out on top when it comes to DX9 and PS 2.0 performance, NVIDIA leads the way in OpenGL performance, and NV40 and R420 split the difference when it comes to DX8 (and older) style games. Even though we haven't yet seen the performance numbers from NVIDIA's 6850 Ultra part, it is likely that there will be a price premium that goes along with that performance. On top of that, the 6850 is really just an overclocked 6800 Ultra part. We will take a look at the issue further when we are finally able to run some numbers.
It is very clear that both NVIDIA and ATI have strong offerings. With better competition in the market place, and NVIDIA differentiating themselves by offering a richer feature set (that doesn't necessarily translate into value unless developers start producing games that use those features), consumers will be able to make a choice without needing to worry about sacrificing real performance. Hopefully we will be able to say the same about image quality when we get done with our testing in that area as well.
Of course, we are still trying to gather all the pieces that explain why we are seeing the numbers we are seeing. The problem is really the amount and level of information we are able to gather is based on how the API maps to the hardware rather than how the hardware does things.
The two rather large issues we have encountered when trying to talk about hardware from the software's perspective are the following: it is easy to get lost when looking at performing tasks from slightly different perspectives or angles of attack, and looking at two architectures that are designed to accomplish similar tasks obfuscates the characteristics of the underlying architectures. We are very happy that both NVIDIA and ATI have started opening up and sharing more about there architectures with us, and hopefully the next round of products will see even further development of this type of relationship.
There is one final dilemma we have on our hands: pricing. From the performance numbers from both this generation and the previous generation, it doesn't seem like prices can stay where they are. As we get a better feel for the coming market with the 12x1 NVIDIA offering, and other midrange and budget offerings from both NVIDIA and ATI, there will be so much overlap in price, performance, and generation without a very large gap in functionality that it might not make sense to spend more money to get something newer. Of course, we will have to wait and see what happens in that area, but depending on what the test results for our 6850 Ultra end up looking like, we may end up recommending that NVIDIA push their prices down slightly (or shift around a few specs) in order to keep the market balanced. With ATI's performance on par in older games and slightly ahead in newer games, the beefy power supply requirement, two slot solution, and sheer heat generated by NV40 may be too much for most people to take the NVIDIA plunge. The bottom line is the consumer here, and its good news all around.






